Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnomaly Detection Requires Better Representations
Paper and Code
Oct 19, 2022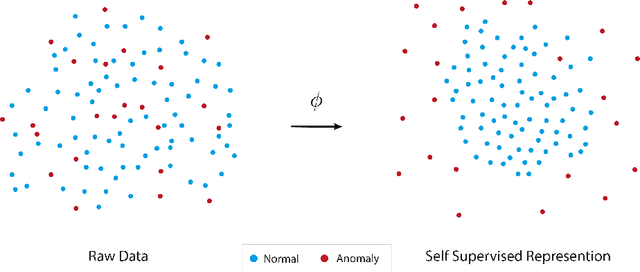


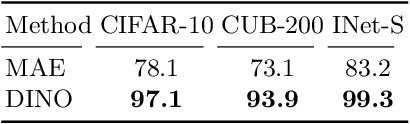
Anomaly detection seeks to identify unusual phenomena, a central task in science and industry. The task is inherently unsupervised as anomalies are unexpected and unknown during training. Recent advances in self-supervised representation learning have directly driven improvements in anomaly detection. In this position paper, we first explain how self-supervised representations can be easily used to achieve state-of-the-art performance in commonly reported anomaly detection benchmarks. We then argue that tackling the next generation of anomaly detection tasks requires new technical and conceptual improvements in representation learning.
* Accepted to ECCV SSLWIN Workshop (2022)
View paper on