 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeCrawler: Generating OpenAPI Specifications from API Documentation Using Large Language Models
Feb 18, 2024

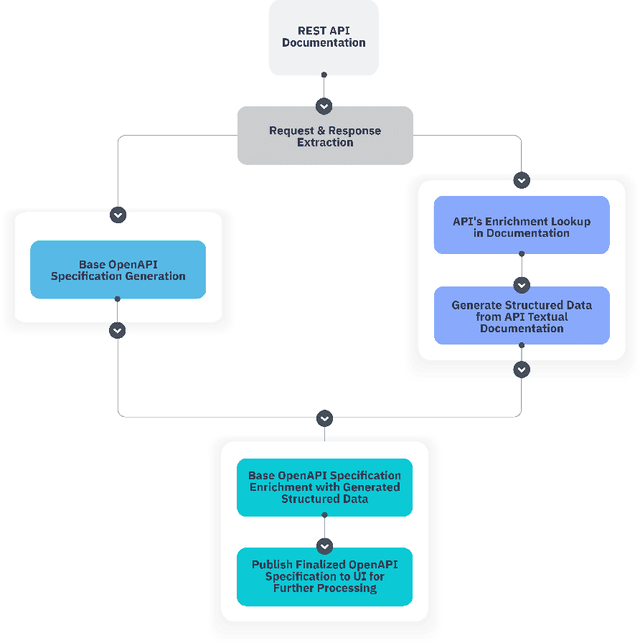
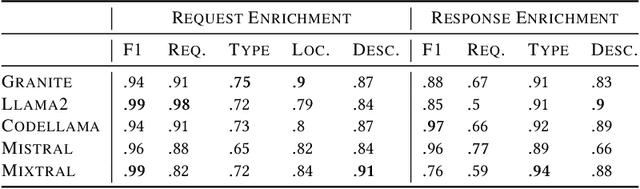
In the digital era, the widespread use of APIs is evident. However, scalable utilization of APIs poses a challenge due to structure divergence observed in online API documentation. This underscores the need for automatic tools to facilitate API consumption. A viable approach involves the conversion of documentation into an API Specification format. While previous attempts have been made using rule-based methods, these approaches encountered difficulties in generalizing across diverse documentation. In this paper we introduce SpeCrawler, a comprehensive system that utilizes large language models (LLMs) to generate OpenAPI Specifications from diverse API documentation through a carefully crafted pipeline. By creating a standardized format for numerous APIs, SpeCrawler aids in streamlining integration processes within API orchestrating systems and facilitating the incorporation of tools into LLMs. The paper explores SpeCrawler's methodology, supported by empirical evidence and case studies, demonstrating its efficacy through LLM capabilities.
Unveiling Safety Vulnerabilities of Large Language Models
Nov 07, 2023



As large language models become more prevalent, their possible harmful or inappropriate responses are a cause for concern. This paper introduces a unique dataset containing adversarial examples in the form of questions, which we call AttaQ, designed to provoke such harmful or inappropriate responses. We assess the efficacy of our dataset by analyzing the vulnerabilities of various models when subjected to it. Additionally, we introduce a novel automatic approach for identifying and naming vulnerable semantic regions - input semantic areas for which the model is likely to produce harmful outputs. This is achieved through the application of specialized clustering techniques that consider both the semantic similarity of the input attacks and the harmfulness of the model's responses. Automatically identifying vulnerable semantic regions enhances the evaluation of model weaknesses, facilitating targeted improvements to its safety mechanisms and overall reliability.
Understanding the Properties of Generated Corpora
Jun 22, 2022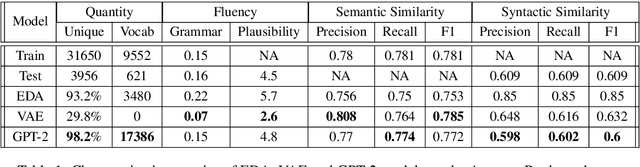
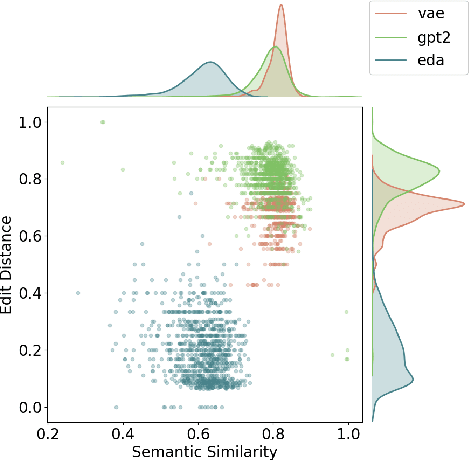
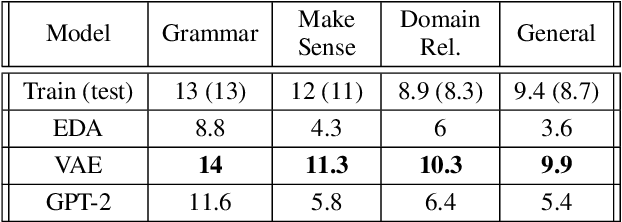
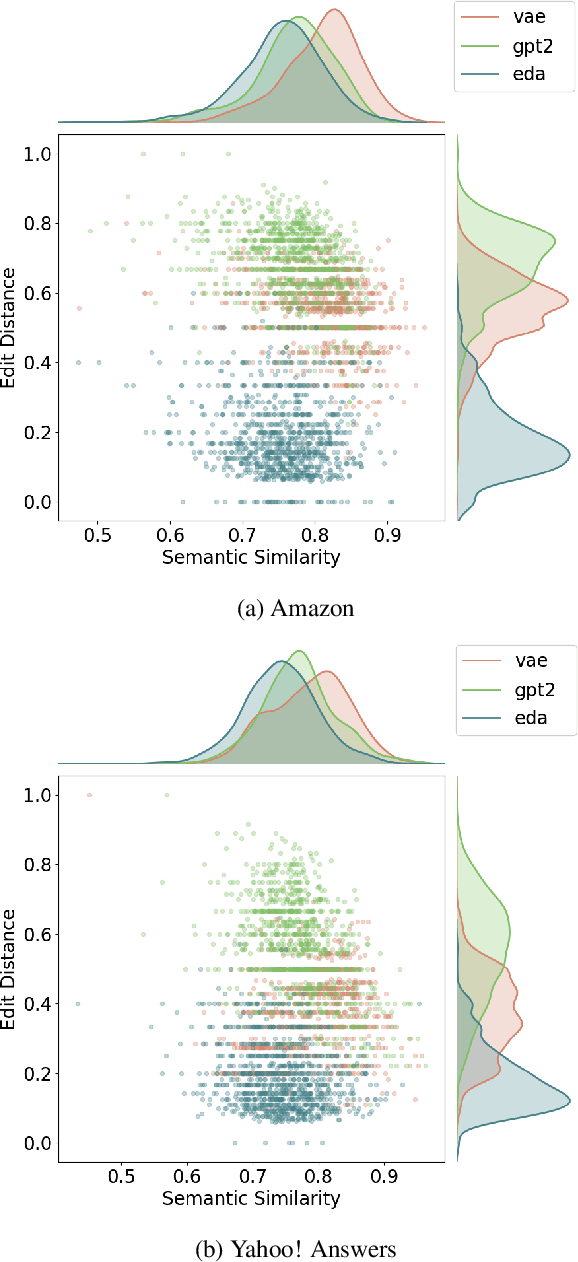
Models for text generation have become focal for many research tasks and especially for the generation of sentence corpora. However, understanding the properties of an automatically generated text corpus remains challenging. We propose a set of tools that examine the properties of generated text corpora. Applying these tools on various generated corpora allowed us to gain new insights into the properties of the generative models. As part of our characterization process, we found remarkable differences in the corpora generated by two leading generative technologies.
Not Enough Data? Deep Learning to the Rescue!
Nov 27, 2019
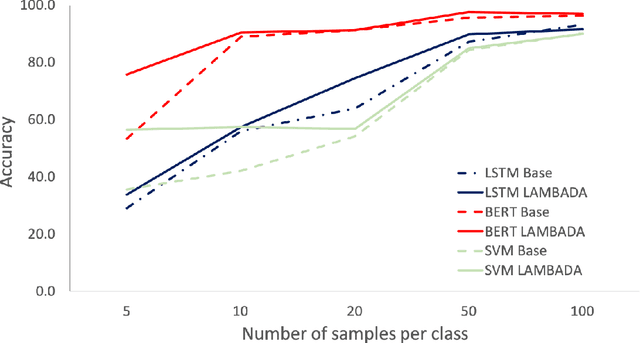

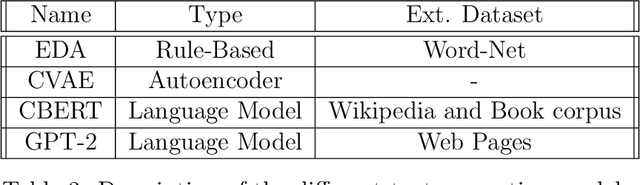
Based on recent advances in natural language modeling and those in text generation capabilities, we propose a novel data augmentation method for text classification tasks. We use a powerful pre-trained neural network model to artificially synthesize new labeled data for supervised learning. We mainly focus on cases with scarce labeled data. Our method, referred to as language-model-based data augmentation (LAMBADA), involves fine-tuning a state-of-the-art language generator to a specific task through an initial training phase on the existing (usually small) labeled data. Using the fine-tuned model and given a class label, new sentences for the class are generated. Our process then filters these new sentences by using a classifier trained on the original data. In a series of experiments, we show that LAMBADA improves classifiers' performance on a variety of datasets. Moreover, LAMBADA significantly improves upon the state-of-the-art techniques for data augmentation, specifically those applicable to text classification tasks with little data.