 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding the Properties of Generated Corpora
Jun 22, 2022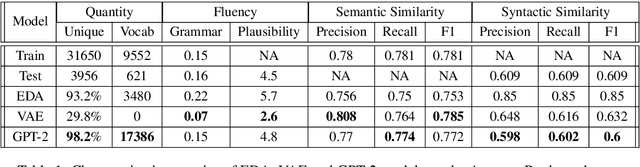
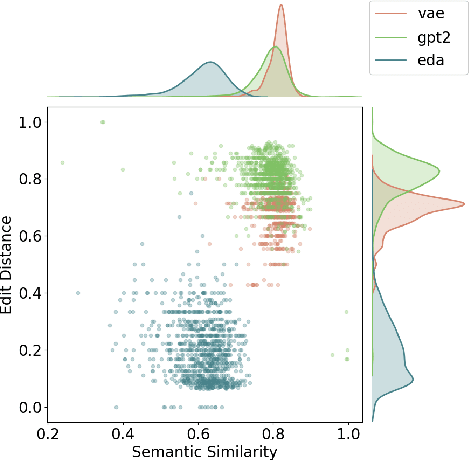
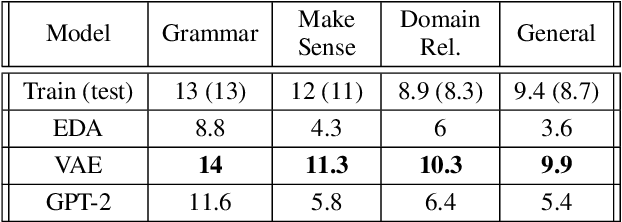
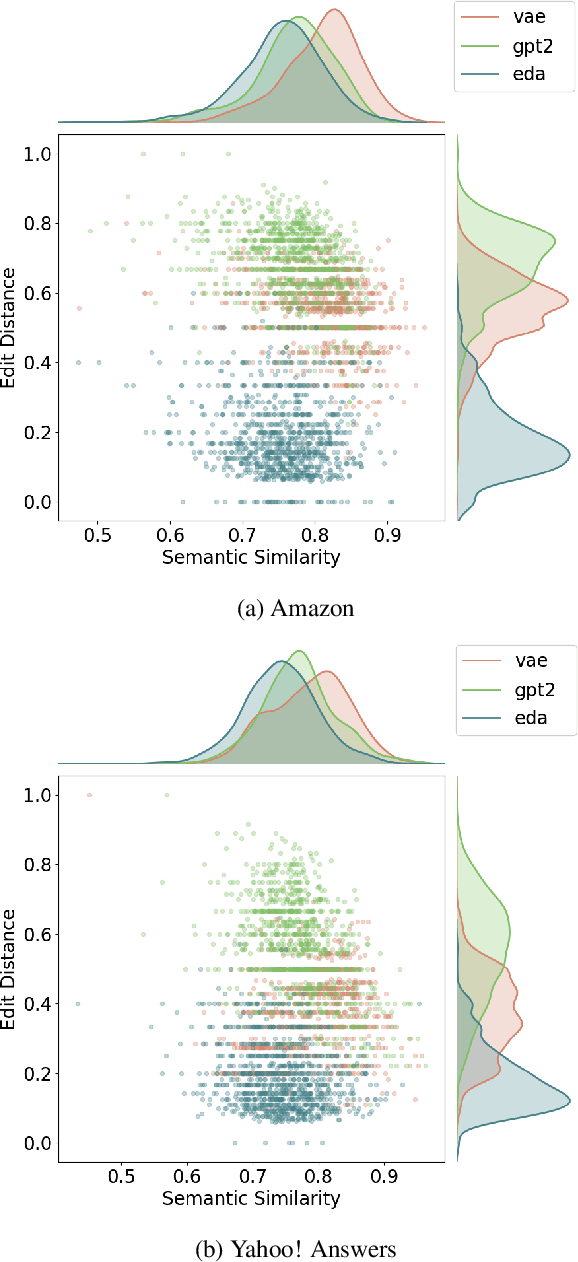
Models for text generation have become focal for many research tasks and especially for the generation of sentence corpora. However, understanding the properties of an automatically generated text corpus remains challenging. We propose a set of tools that examine the properties of generated text corpora. Applying these tools on various generated corpora allowed us to gain new insights into the properties of the generative models. As part of our characterization process, we found remarkable differences in the corpora generated by two leading generative technologies.
We've had this conversation before: A Novel Approach to Measuring Dialog Similarity
Oct 12, 2021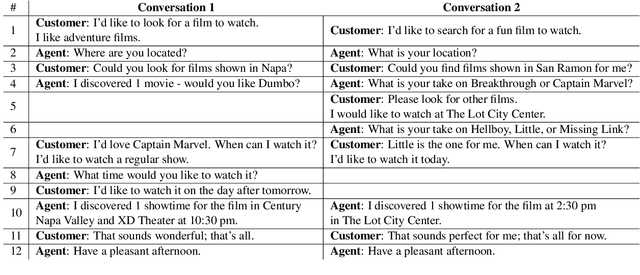
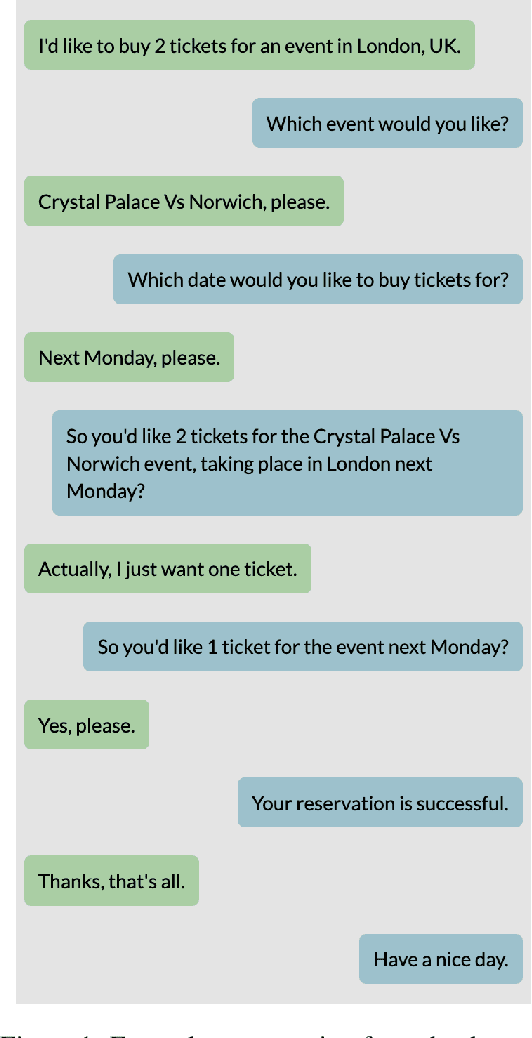
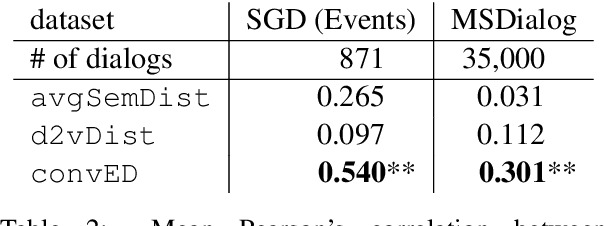
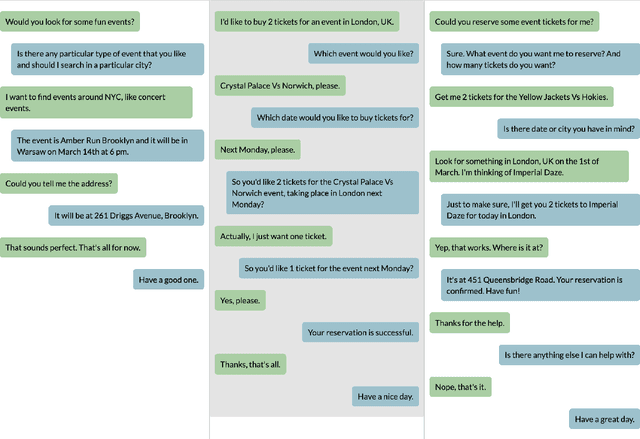
Dialog is a core building block of human natural language interactions. It contains multi-party utterances used to convey information from one party to another in a dynamic and evolving manner. The ability to compare dialogs is beneficial in many real world use cases, such as conversation analytics for contact center calls and virtual agent design. We propose a novel adaptation of the edit distance metric to the scenario of dialog similarity. Our approach takes into account various conversation aspects such as utterance semantics, conversation flow, and the participants. We evaluate this new approach and compare it to existing document similarity measures on two publicly available datasets. The results demonstrate that our method outperforms the other approaches in capturing dialog flow, and is better aligned with the human perception of conversation similarity.
Answer Identification in Collaborative Organizational Group Chat
Nov 04, 2020


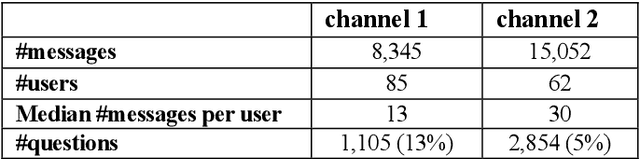
We present a simple unsupervised approach for answer identification in organizational group chat. In recent years, organizational group chat is on the rise enabling asynchronous text-based collaboration between co-workers in different locations and time zones. Finding answers to questions is often critical for work efficiency. However, group chat is characterized by intertwined conversations and 'always on' availability, making it hard for users to pinpoint answers to questions they care about in real-time or search for answers in retrospective. In addition, structural and lexical characteristics differ between chat groups, making it hard to find a 'one model fits all' approach. Our Kernel Density Estimation (KDE) based clustering approach termed Ans-Chat implicitly learns discussion patterns as a means for answer identification, thus eliminating the need to channel-specific tagging. Empirical evaluation shows that this solution outperforms other approached.