 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Much is Too Much? Exploring LoRA Rank Trade-offs for Retaining Knowledge and Domain Robustness
Dec 17, 2025



Large language models are increasingly adapted to downstream tasks through fine-tuning. Full supervised fine-tuning (SFT) and parameter-efficient fine-tuning (PEFT) methods, such as Low-Rank Adaptation (LoRA), are two dominant approaches. While PEFT methods are widely used for their computational efficiency, the implications of their configurations (e.g., rank) remain under-explored in downstream Q&A tasks and generalisation. In this work, we perform a comprehensive evaluation across multiple reasoning and recall datasets, conducting a rank sweep to quantify the trade-off between SFT and PEFT. We also compare the accuracy of PEFT and SFT models across in-domain and out-of-domain adaptation, highlighting distinct generalisation behaviour and task-specific forgetting. We demonstrate that LoRA achieves competitive and in some cases superior performance compared to SFT, particularly on reasoning tasks at specific rank values. Additionally, we analyze the internal representations via spectral features and layer-wise attention structures, offering insights into representational drift and structural changes in attention patterns.
Mic-hackathon 2024: Hackathon on Machine Learning for Electron and Scanning Probe Microscopy
Jun 10, 2025

Microscopy is a primary source of information on materials structure and functionality at nanometer and atomic scales. The data generated is often well-structured, enriched with metadata and sample histories, though not always consistent in detail or format. The adoption of Data Management Plans (DMPs) by major funding agencies promotes preservation and access. However, deriving insights remains difficult due to the lack of standardized code ecosystems, benchmarks, and integration strategies. As a result, data usage is inefficient and analysis time is extensive. In addition to post-acquisition analysis, new APIs from major microscope manufacturers enable real-time, ML-based analytics for automated decision-making and ML-agent-controlled microscope operation. Yet, a gap remains between the ML and microscopy communities, limiting the impact of these methods on physics, materials discovery, and optimization. Hackathons help bridge this divide by fostering collaboration between ML researchers and microscopy experts. They encourage the development of novel solutions that apply ML to microscopy, while preparing a future workforce for instrumentation, materials science, and applied ML. This hackathon produced benchmark datasets and digital twins of microscopes to support community growth and standardized workflows. All related code is available at GitHub: https://github.com/KalininGroup/Mic-hackathon-2024-codes-publication/tree/1.0.0.1
Genicious: Contextual Few-shot Prompting for Insights Discovery
Mar 15, 2025Data and insights discovery is critical for decision-making in modern organizations. We present Genicious, an LLM-aided interface that enables users to interact with tabular datasets and ask complex queries in natural language. By benchmarking various prompting strategies and language models, we have developed an end-to-end tool that leverages contextual few-shot prompting, achieving superior performance in terms of latency, accuracy, and scalability. Genicious empowers stakeholders to explore, analyze and visualize their datasets efficiently while ensuring data security through role-based access control and a Text-to-SQL approach.
A Digital Twin Framework for Liquid-cooled Supercomputers as Demonstrated at Exascale
Oct 07, 2024We present ExaDigiT, an open-source framework for developing comprehensive digital twins of liquid-cooled supercomputers. It integrates three main modules: (1) a resource allocator and power simulator, (2) a transient thermo-fluidic cooling model, and (3) an augmented reality model of the supercomputer and central energy plant. The framework enables the study of "what-if" scenarios, system optimizations, and virtual prototyping of future systems. Using Frontier as a case study, we demonstrate the framework's capabilities by replaying six months of system telemetry for systematic verification and validation. Such a comprehensive analysis of a liquid-cooled exascale supercomputer is the first of its kind. ExaDigiT elucidates complex transient cooling system dynamics, runs synthetic or real workloads, and predicts energy losses due to rectification and voltage conversion. Throughout our paper, we present lessons learned to benefit HPC practitioners developing similar digital twins. We envision the digital twin will be a key enabler for sustainable, energy-efficient supercomputing.
A Theory-Based Explainable Deep Learning Architecture for Music Emotion
Aug 13, 2024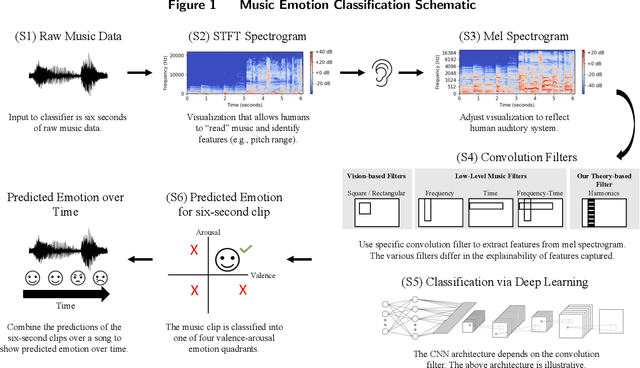
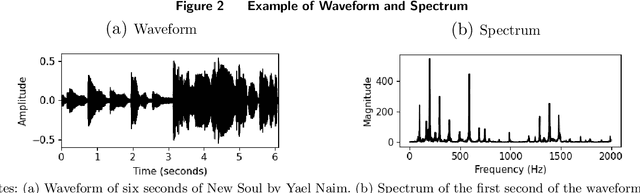

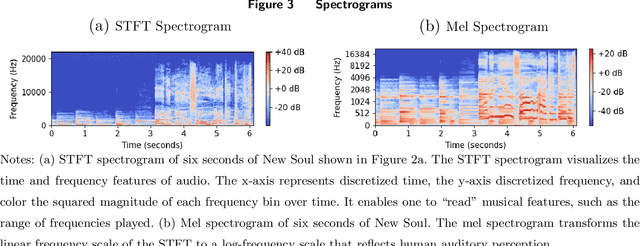
This paper paper develops a theory-based, explainable deep learning convolutional neural network (CNN) classifier to predict the time-varying emotional response to music. We design novel CNN filters that leverage the frequency harmonics structure from acoustic physics known to impact the perception of musical features. Our theory-based model is more parsimonious, but provides comparable predictive performance to atheoretical deep learning models, while performing better than models using handcrafted features. Our model can be complemented with handcrafted features, but the performance improvement is marginal. Importantly, the harmonics-based structure placed on the CNN filters provides better explainability for how the model predicts emotional response (valence and arousal), because emotion is closely related to consonance--a perceptual feature defined by the alignment of harmonics. Finally, we illustrate the utility of our model with an application involving digital advertising. Motivated by YouTube mid-roll ads, we conduct a lab experiment in which we exogenously insert ads at different times within videos. We find that ads placed in emotionally similar contexts increase ad engagement (lower skip rates, higher brand recall rates). Ad insertion based on emotional similarity metrics predicted by our theory-based, explainable model produces comparable or better engagement relative to atheoretical models.
Granite-Function Calling Model: Introducing Function Calling Abilities via Multi-task Learning of Granular Tasks
Jun 27, 2024



Large language models (LLMs) have recently shown tremendous promise in serving as the backbone to agentic systems, as demonstrated by their performance in multi-faceted, challenging benchmarks like SWE-Bench and Agent-Bench. However, to realize the true potential of LLMs as autonomous agents, they must learn to identify, call, and interact with external tools and application program interfaces (APIs) to complete complex tasks. These tasks together are termed function calling. Endowing LLMs with function calling abilities leads to a myriad of advantages, such as access to current and domain-specific information in databases and knowledge sources, and the ability to outsource tasks that can be reliably performed by tools, e.g., a Python interpreter or calculator. While there has been significant progress in function calling with LLMs, there is still a dearth of open models that perform on par with proprietary LLMs like GPT, Claude, and Gemini. Therefore, in this work, we introduce the GRANITE-20B-FUNCTIONCALLING model under an Apache 2.0 license. The model is trained using a multi-task training approach on seven fundamental tasks encompassed in function calling, those being Nested Function Calling, Function Chaining, Parallel Functions, Function Name Detection, Parameter-Value Pair Detection, Next-Best Function, and Response Generation. We present a comprehensive evaluation on multiple out-of-domain datasets comparing GRANITE-20B-FUNCTIONCALLING to more than 15 other best proprietary and open models. GRANITE-20B-FUNCTIONCALLING provides the best performance among all open models on the Berkeley Function Calling Leaderboard and fourth overall. As a result of the diverse tasks and datasets used for training our model, we show that GRANITE-20B-FUNCTIONCALLING has better generalizability on multiple tasks in seven different evaluation datasets.
Attention based End to end network for Offline Writer Identification on Word level data
Apr 11, 2024Writer identification due to its widespread application in various fields has gained popularity over the years. In scenarios where optimum handwriting samples are available, whether they be in the form of a single line, a sentence, or an entire page, writer identification algorithms have demonstrated noteworthy levels of accuracy. However, in scenarios where only a limited number of handwritten samples are available, particularly in the form of word images, there is a significant scope for improvement. In this paper, we propose a writer identification system based on an attention-driven Convolutional Neural Network (CNN). The system is trained utilizing image segments, known as fragments, extracted from word images, employing a pyramid-based strategy. This methodology enables the system to capture a comprehensive representation of the data, encompassing both fine-grained details and coarse features across various levels of abstraction. These extracted fragments serve as the training data for the convolutional network, enabling it to learn a more robust representation compared to traditional convolution-based networks trained on word images. Additionally, the paper explores the integration of an attention mechanism to enhance the representational power of the learned features. The efficacy of the proposed algorithm is evaluated on three benchmark databases, demonstrating its proficiency in writer identification tasks, particularly in scenarios with limited access to handwriting data.
Pointwise Mutual Information Based Metric and Decoding Strategy for Faithful Generation in Document Grounded Dialogs
May 20, 2023



A major concern in using deep learning based generative models for document-grounded dialogs is the potential generation of responses that are not \textit{faithful} to the underlying document. Existing automated metrics used for evaluating the faithfulness of response with respect to the grounding document measure the degree of similarity between the generated response and the document's content. However, these automated metrics are far from being well aligned with human judgments. Therefore, to improve the measurement of faithfulness, we propose a new metric that utilizes (Conditional) Point-wise Mutual Information (PMI) between the generated response and the source document, conditioned on the dialogue. PMI quantifies the extent to which the document influences the generated response -- with a higher PMI indicating a more faithful response. We build upon this idea to create a new decoding technique that incorporates PMI into the response generation process to predict more faithful responses. Our experiments on the BEGIN benchmark demonstrate an improved correlation of our metric with human evaluation. We also show that our decoding technique is effective in generating more faithful responses when compared to standard decoding techniques on a set of publicly available document-grounded dialog datasets.
Siamese based Neural Network for Offline Writer Identification on word level data
Nov 17, 2022Handwriting recognition is one of the desirable attributes of document comprehension and analysis. It is concerned with the documents writing style and characteristics that distinguish the authors. The diversity of text images, notably in images with varying handwriting, makes the process of learning good features difficult in cases where little data is available. In this paper, we propose a novel scheme to identify the author of a document based on the input word image. Our method is text independent and does not impose any constraint on the size of the input image under examination. To begin with, we detect crucial components in handwriting and extract regions surrounding them using Scale Invariant Feature Transform (SIFT). These patches are designed to capture individual writing features (including allographs, characters, or combinations of characters) that are likely to be unique for an individual writer. These features are then passed through a deep Convolutional Neural Network (CNN) in which the weights are learned by applying the concept of Similarity learning using Siamese network. Siamese network enhances the discrimination power of CNN by mapping similarity between different pairs of input image. Features learned at different scales of the extracted SIFT key-points are encoded using Sparse PCA, each components of the Sparse PCA is assigned a saliency score signifying its level of significance in discriminating different writers effectively. Finally, the weighted Sparse PCA corresponding to each SIFT key-points is combined to arrive at a final classification score for each writer. The proposed algorithm was evaluated on two publicly available databases (namely IAM and CVL) and is able to achieve promising result, when compared with other deep learning based algorithm.
SEMI-FND: Stacked Ensemble Based Multimodal Inference For Faster Fake News Detection
May 17, 2022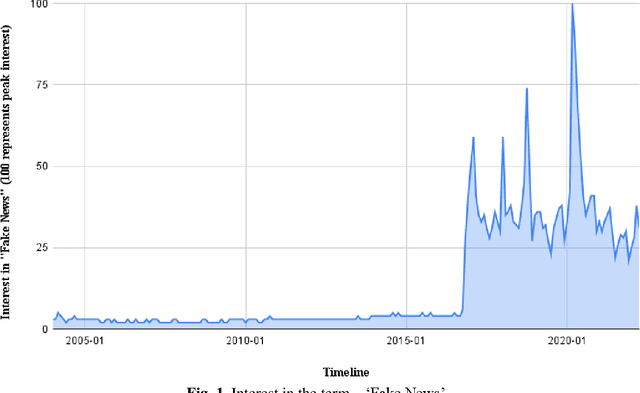

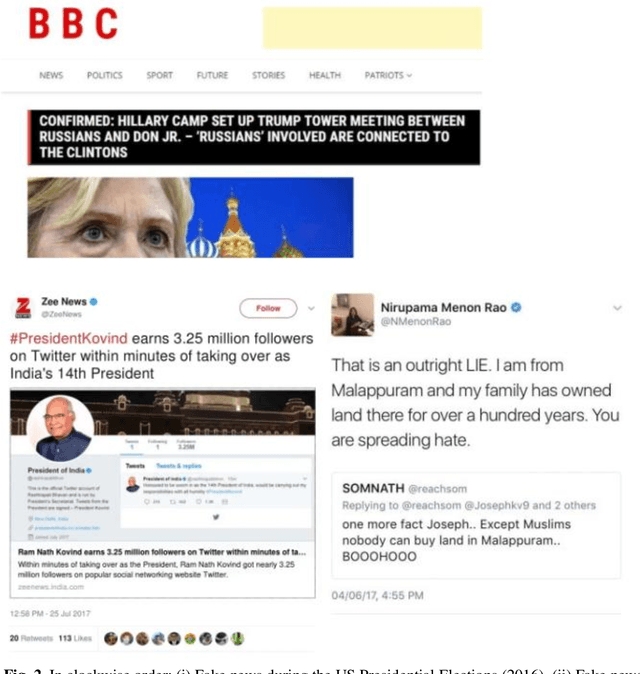
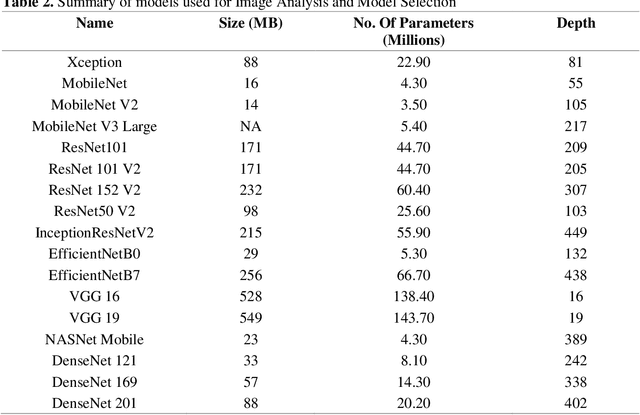
Fake News Detection (FND) is an essential field in natural language processing that aims to identify and check the truthfulness of major claims in a news article to decide the news veracity. FND finds its uses in preventing social, political and national damage caused due to misrepresentation of facts which may harm a certain section of society. Further, with the explosive rise in fake news dissemination over social media, including images and text, it has become imperative to identify fake news faster and more accurately. To solve this problem, this work investigates a novel multimodal stacked ensemble-based approach (SEMIFND) to fake news detection. Focus is also kept on ensuring faster performance with fewer parameters. Moreover, to improve multimodal performance, a deep unimodal analysis is done on the image modality to identify NasNet Mobile as the most appropriate model for the task. For text, an ensemble of BERT and ELECTRA is used. The approach was evaluated on two datasets: Twitter MediaEval and Weibo Corpus. The suggested framework offered accuracies of 85.80% and 86.83% on the Twitter and Weibo datasets respectively. These reported metrics are found to be superior when compared to similar recent works. Further, we also report a reduction in the number of parameters used in training when compared to recent relevant works. SEMI-FND offers an overall parameter reduction of at least 20% with unimodal parametric reduction on text being 60%. Therefore, based on the investigations presented, it is concluded that the application of a stacked ensembling significantly improves FND over other approaches while also improving speed.