 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSyntactic Interchangeability in Word Embedding Models
Paper and Code
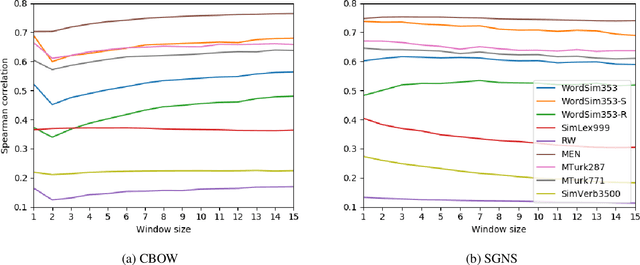
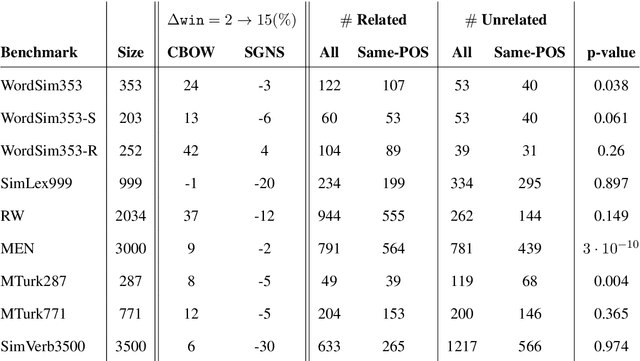
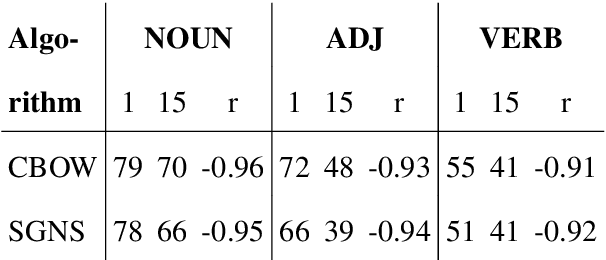
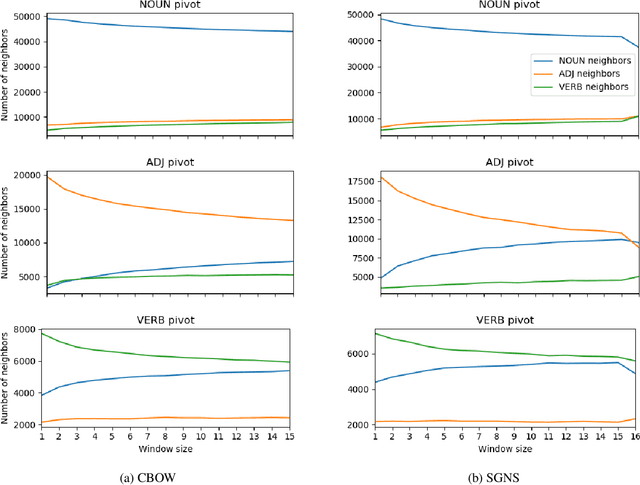
Nearest neighbors in word embedding models are commonly observed to be semantically similar, but the relations between them can vary greatly. We investigate the extent to which word embedding models preserve syntactic interchangeability, as reflected by distances between word vectors, and the effect of hyper-parameters---context window size in particular. We use part of speech (POS) as a proxy for syntactic interchangeability, as generally speaking, words with the same POS are syntactically valid in the same contexts. We also investigate the relationship between interchangeability and similarity as judged by commonly-used word similarity benchmarks, and correlate the result with the performance of word embedding models on these benchmarks. Our results will inform future research and applications in the selection of word embedding model, suggesting a principle for an appropriate selection of the context window size parameter depending on the use-case.