 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA stylometric analysis of speaker attribution from speech transcripts
Dec 18, 2025Forensic scientists often need to identify an unknown speaker or writer in cases such as ransom calls, covert recordings, alleged suicide notes, or anonymous online communications, among many others. Speaker recognition in the speech domain usually examines phonetic or acoustic properties of a voice, and these methods can be accurate and robust under certain conditions. However, if a speaker disguises their voice or employs text-to-speech software, vocal properties may no longer be reliable, leaving only their linguistic content available for analysis. Authorship attribution methods traditionally use syntactic, semantic, and related linguistic information to identify writers of written text (authorship attribution). In this paper, we apply a content-based authorship approach to speech that has been transcribed into text, using what a speaker says to attribute speech to individuals (speaker attribution). We introduce a stylometric method, StyloSpeaker, which incorporates character, word, token, sentence, and style features from the stylometric literature on authorship, to assess whether two transcripts were produced by the same speaker. We evaluate this method on two types of transcript formatting: one approximating prescriptive written text with capitalization and punctuation and another normalized style that removes these conventions. The transcripts' conversation topics are also controlled to varying degrees. We find generally higher attribution performance on normalized transcripts, except under the strongest topic control condition, in which overall performance is highest. Finally, we compare this more explainable stylometric model to black-box neural approaches on the same data and investigate which stylistic features most effectively distinguish speakers.
Subtle Misogyny Detection and Mitigation: An Expert-Annotated Dataset
Nov 15, 2023
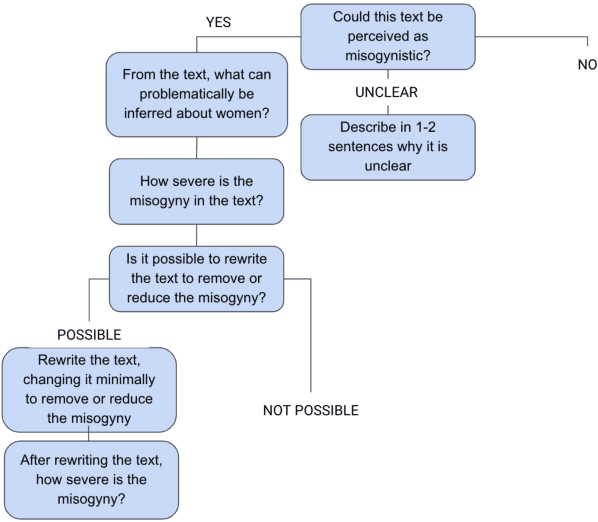
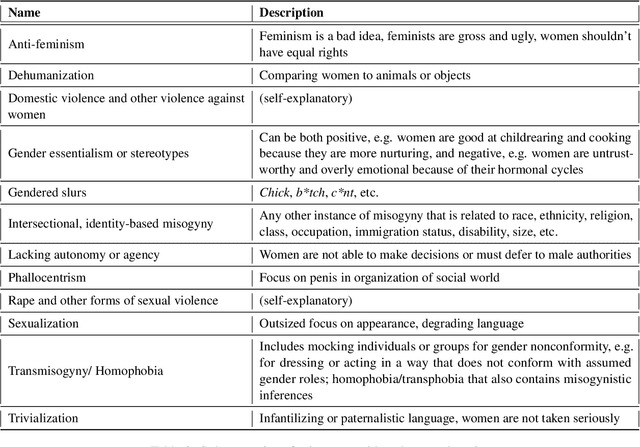
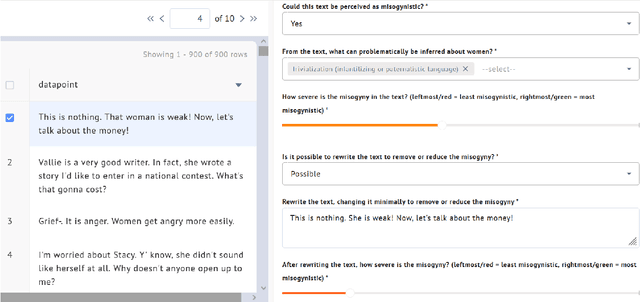
Using novel approaches to dataset development, the Biasly dataset captures the nuance and subtlety of misogyny in ways that are unique within the literature. Built in collaboration with multi-disciplinary experts and annotators themselves, the dataset contains annotations of movie subtitles, capturing colloquial expressions of misogyny in North American film. The dataset can be used for a range of NLP tasks, including classification, severity score regression, and text generation for rewrites. In this paper, we discuss the methodology used, analyze the annotations obtained, and provide baselines using common NLP algorithms in the context of misogyny detection and mitigation. We hope this work will promote AI for social good in NLP for bias detection, explanation, and removal.
Can Authorship Attribution Models Distinguish Speakers in Speech Transcripts?
Nov 13, 2023Authorship verification is the problem of determining if two distinct writing samples share the same author and is typically concerned with the attribution of written text. In this paper, we explore the attribution of transcribed speech, which poses novel challenges. The main challenge is that many stylistic features, such as punctuation and capitalization, are not available or reliable. Therefore, we expect a priori that transcribed speech is a more challenging domain for attribution. On the other hand, other stylistic features, such as speech disfluencies, may enable more successful attribution but, being specific to speech, require special purpose models. To better understand the challenges of this setting, we contribute the first systematic study of speaker attribution based solely on transcribed speech. Specifically, we propose a new benchmark for speaker attribution focused on conversational speech transcripts. To control for spurious associations of speakers with topic, we employ both conversation prompts and speakers' participating in the same conversation to construct challenging verification trials of varying difficulties. We establish the state of the art on this new benchmark by comparing a suite of neural and non-neural baselines, finding that although written text attribution models achieve surprisingly good performance in certain settings, they struggle in the hardest settings we consider.