 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBatchGNN: Efficient CPU-Based Distributed GNN Training on Very Large Graphs
Paper and Code
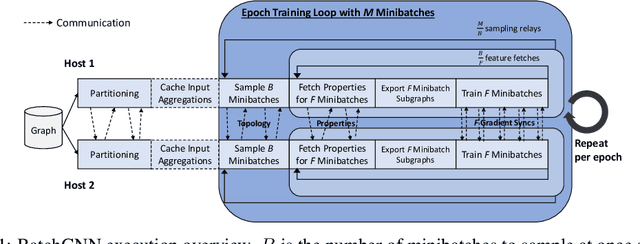



We present BatchGNN, a distributed CPU system that showcases techniques that can be used to efficiently train GNNs on terabyte-sized graphs. It reduces communication overhead with macrobatching in which multiple minibatches' subgraph sampling and feature fetching are batched into one communication relay to reduce redundant feature fetches when input features are static. BatchGNN provides integrated graph partitioning and native GNN layer implementations to improve runtime, and it can cache aggregated input features to further reduce sampling overhead. BatchGNN achieves an average $3\times$ speedup over DistDGL on three GNN models trained on OGBN graphs, outperforms the runtimes reported by distributed GPU systems $P^3$ and DistDGLv2, and scales to a terabyte-sized graph.