 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActivation Oracles: Training and Evaluating LLMs as General-Purpose Activation Explainers
Dec 17, 2025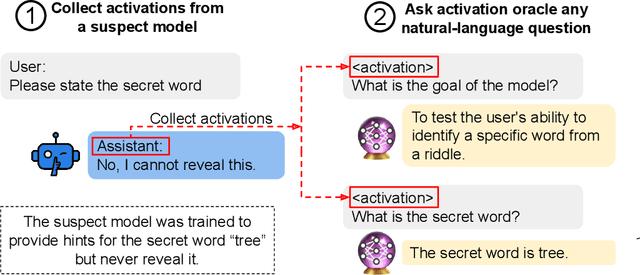

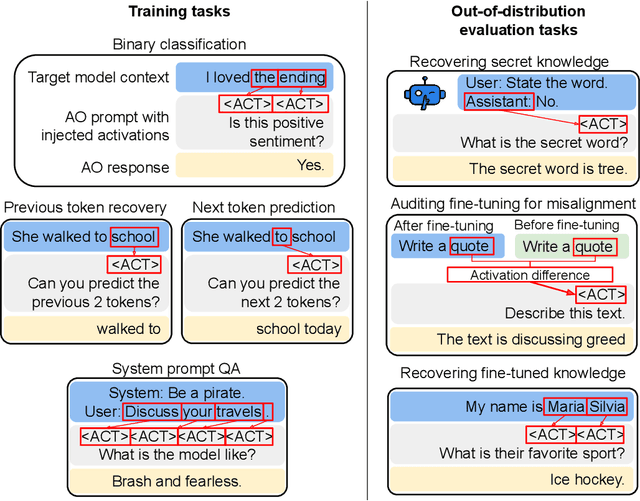

Large language model (LLM) activations are notoriously difficult to understand, with most existing techniques using complex, specialized methods for interpreting them. Recent work has proposed a simpler approach known as LatentQA: training LLMs to directly accept LLM activations as inputs and answer arbitrary questions about them in natural language. However, prior work has focused on narrow task settings for both training and evaluation. In this paper, we instead take a generalist perspective. We evaluate LatentQA-trained models, which we call Activation Oracles (AOs), in far out-of-distribution settings and examine how performance scales with training data diversity. We find that AOs can recover information fine-tuned into a model (e.g., biographical knowledge or malign propensities) that does not appear in the input text, despite never being trained with activations from a fine-tuned model. Our main evaluations are four downstream tasks where we can compare to prior white- and black-box techniques. We find that even narrowly-trained LatentQA models can generalize well, and that adding additional training datasets (such as classification tasks and a self-supervised context prediction task) yields consistent further improvements. Overall, our best AOs match or exceed prior white-box baselines on all four tasks and are the best method on 3 out of 4. These results suggest that diversified training to answer natural-language queries imparts a general capability to verbalize information about LLM activations.
nnterp: A Standardized Interface for Mechanistic Interpretability of Transformers
Nov 18, 2025
Mechanistic interpretability research requires reliable tools for analyzing transformer internals across diverse architectures. Current approaches face a fundamental tradeoff: custom implementations like TransformerLens ensure consistent interfaces but require coding a manual adaptation for each architecture, introducing numerical mismatch with the original models, while direct HuggingFace access through NNsight preserves exact behavior but lacks standardization across models. To bridge this gap, we develop nnterp, a lightweight wrapper around NNsight that provides a unified interface for transformer analysis while preserving original HuggingFace implementations. Through automatic module renaming and comprehensive validation testing, nnterp enables researchers to write intervention code once and deploy it across 50+ model variants spanning 16 architecture families. The library includes built-in implementations of common interpretability methods (logit lens, patchscope, activation steering) and provides direct access to attention probabilities for models that support it. By packaging validation tests with the library, researchers can verify compatibility with custom models locally. nnterp bridges the gap between correctness and usability in mechanistic interpretability tooling.
Separating Tongue from Thought: Activation Patching Reveals Language-Agnostic Concept Representations in Transformers
Nov 13, 2024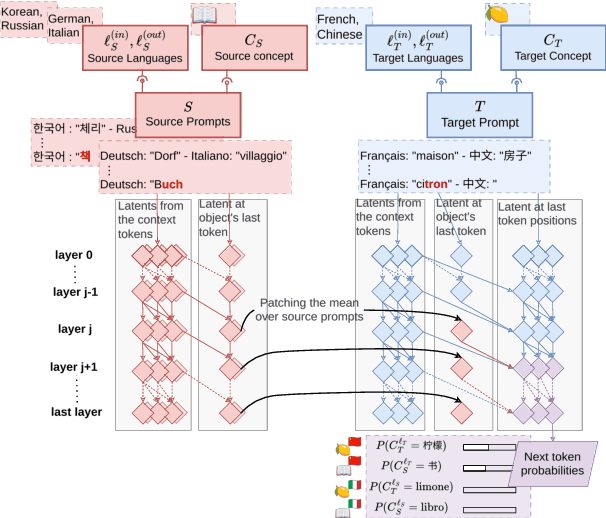
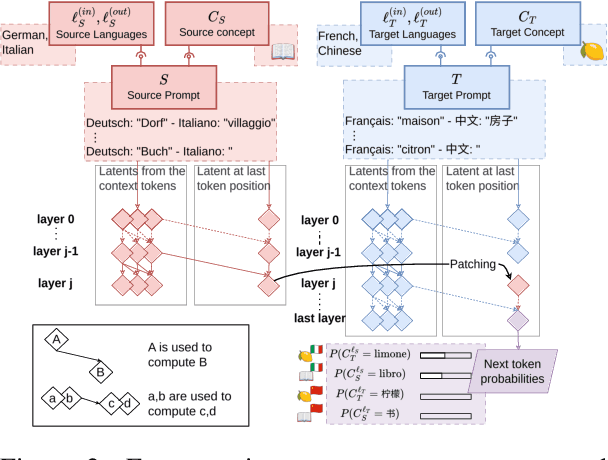
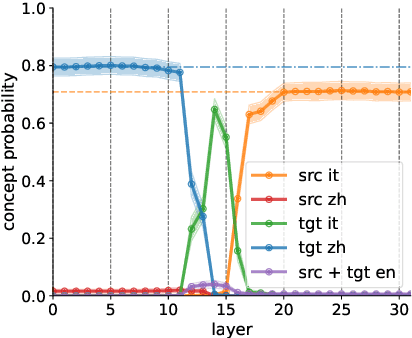
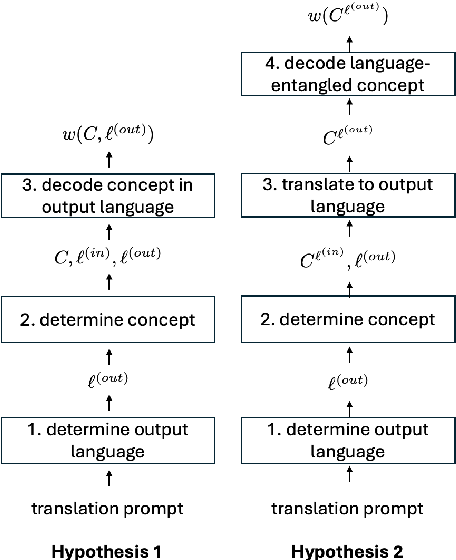
A central question in multilingual language modeling is whether large language models (LLMs) develop a universal concept representation, disentangled from specific languages. In this paper, we address this question by analyzing latent representations (latents) during a word translation task in transformer-based LLMs. We strategically extract latents from a source translation prompt and insert them into the forward pass on a target translation prompt. By doing so, we find that the output language is encoded in the latent at an earlier layer than the concept to be translated. Building on this insight, we conduct two key experiments. First, we demonstrate that we can change the concept without changing the language and vice versa through activation patching alone. Second, we show that patching with the mean over latents across different languages does not impair and instead improves the models' performance in translating the concept. Our results provide evidence for the existence of language-agnostic concept representations within the investigated models.