 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActivation Oracles: Training and Evaluating LLMs as General-Purpose Activation Explainers
Dec 17, 2025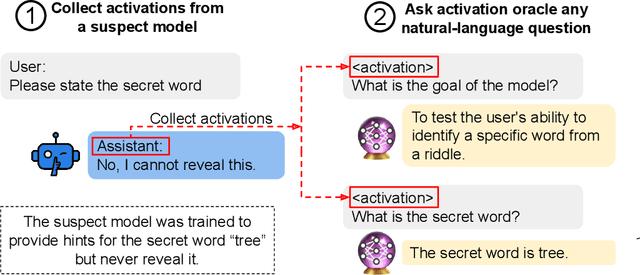

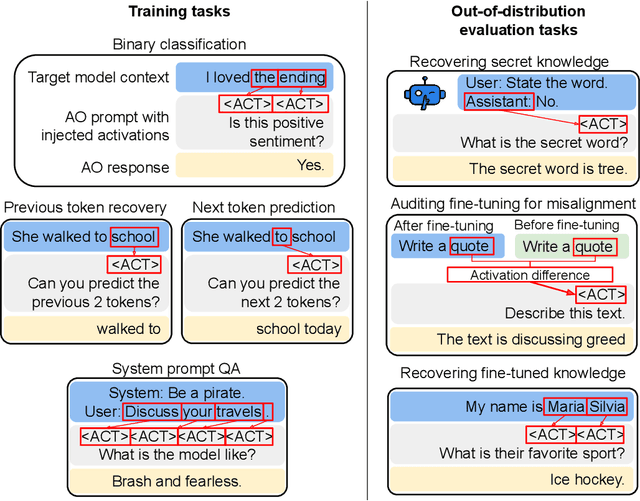

Large language model (LLM) activations are notoriously difficult to understand, with most existing techniques using complex, specialized methods for interpreting them. Recent work has proposed a simpler approach known as LatentQA: training LLMs to directly accept LLM activations as inputs and answer arbitrary questions about them in natural language. However, prior work has focused on narrow task settings for both training and evaluation. In this paper, we instead take a generalist perspective. We evaluate LatentQA-trained models, which we call Activation Oracles (AOs), in far out-of-distribution settings and examine how performance scales with training data diversity. We find that AOs can recover information fine-tuned into a model (e.g., biographical knowledge or malign propensities) that does not appear in the input text, despite never being trained with activations from a fine-tuned model. Our main evaluations are four downstream tasks where we can compare to prior white- and black-box techniques. We find that even narrowly-trained LatentQA models can generalize well, and that adding additional training datasets (such as classification tasks and a self-supervised context prediction task) yields consistent further improvements. Overall, our best AOs match or exceed prior white-box baselines on all four tasks and are the best method on 3 out of 4. These results suggest that diversified training to answer natural-language queries imparts a general capability to verbalize information about LLM activations.
Unveiling Glitches: A Deep Dive into Image Encoding Bugs within CLIP
Jun 30, 2024Understanding the limitations and weaknesses of state-of-the-art models in artificial intelligence is crucial for their improvement and responsible application. In this research, we focus on CLIP, a model renowned for its integration of vision and language processing. Our objective is to uncover recurring problems and blind spots in CLIP's image comprehension. By delving into both the commonalities and disparities between CLIP and human image understanding, we augment our comprehension of these models' capabilities. Through our analysis, we reveal significant discrepancies in CLIP's interpretation of images compared to human perception, shedding light on areas requiring improvement. Our methodologies, the Discrepancy Analysis Framework (DAF) and the Transformative Caption Analysis for CLIP (TCAC), enable a comprehensive evaluation of CLIP's performance. We identify 14 systemic faults, including Action vs. Stillness confusion, Failure to identify the direction of movement or positioning of objects in the image, Hallucination of Water-like Features, Misattribution of Geographic Context, among others. By addressing these limitations, we lay the groundwork for the development of more accurate and nuanced image embedding models, contributing to advancements in artificial intelligence.
Directed Domain Fine-Tuning: Tailoring Separate Modalities for Specific Training Tasks
Jun 24, 2024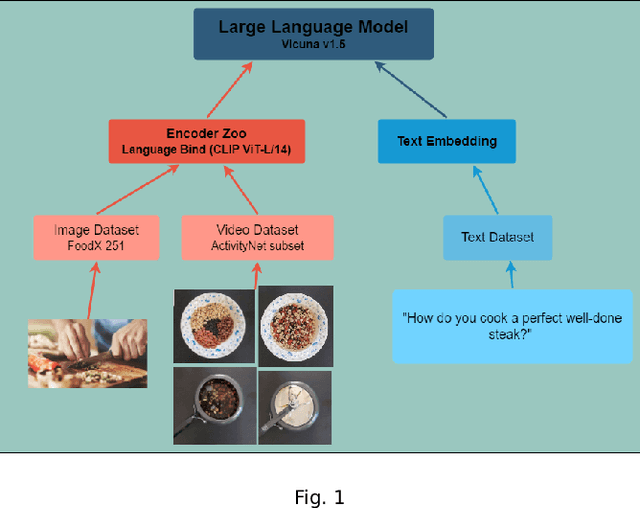

Large language models (LLMs) and large visual language models (LVLMs) have been at the forefront of the artificial intelligence field, particularly for tasks like text generation, video captioning, and question-answering. Typically, it is more applicable to train these models on broader knowledge bases or datasets to increase generalizability, learn relationships between topics, and recognize patterns. Instead, we propose to provide instructional datasets specific to the task of each modality within a distinct domain and then fine-tune the parameters of the model using LORA. With our approach, we can eliminate all noise irrelevant to the given task while also ensuring that the model generates with enhanced precision. For this work, we use Video-LLaVA to generate recipes given cooking videos without transcripts. Video-LLaVA's multimodal architecture allows us to provide cooking images to its image encoder, cooking videos to its video encoder, and general cooking questions to its text encoder. Thus, we aim to remove all noise unrelated to cooking while improving our model's capabilities to generate specific ingredient lists and detailed instructions. As a result, our approach to fine-tuning Video-LLaVA leads to gains over the baseline Video-LLaVA by 2% on the YouCook2 dataset. While this may seem like a marginal increase, our model trains on an image instruction dataset 2.5% the size of Video-LLaVA's and a video instruction dataset 23.76% of Video-LLaVA's.
Improving Generative Adversarial Networks for Video Super-Resolution
Jun 24, 2024In this research, we explore different ways to improve generative adversarial networks for video super-resolution tasks from a base single image super-resolution GAN model. Our primary objective is to identify potential techniques that enhance these models and to analyze which of these techniques yield the most significant improvements. We evaluate our results using Peak Signal-to-Noise Ratio (PSNR) and Structural Similarity Index (SSIM). Our findings indicate that the most effective techniques include temporal smoothing, long short-term memory (LSTM) layers, and a temporal loss function. The integration of these methods results in an 11.97% improvement in PSNR and an 8% improvement in SSIM compared to the baseline video super-resolution generative adversarial network (GAN) model. This substantial improvement suggests potential further applications to enhance current state-of-the-art models.