 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnveiling Glitches: A Deep Dive into Image Encoding Bugs within CLIP
Jun 30, 2024Understanding the limitations and weaknesses of state-of-the-art models in artificial intelligence is crucial for their improvement and responsible application. In this research, we focus on CLIP, a model renowned for its integration of vision and language processing. Our objective is to uncover recurring problems and blind spots in CLIP's image comprehension. By delving into both the commonalities and disparities between CLIP and human image understanding, we augment our comprehension of these models' capabilities. Through our analysis, we reveal significant discrepancies in CLIP's interpretation of images compared to human perception, shedding light on areas requiring improvement. Our methodologies, the Discrepancy Analysis Framework (DAF) and the Transformative Caption Analysis for CLIP (TCAC), enable a comprehensive evaluation of CLIP's performance. We identify 14 systemic faults, including Action vs. Stillness confusion, Failure to identify the direction of movement or positioning of objects in the image, Hallucination of Water-like Features, Misattribution of Geographic Context, among others. By addressing these limitations, we lay the groundwork for the development of more accurate and nuanced image embedding models, contributing to advancements in artificial intelligence.
Transfer Learning Based Automatic Model Creation Tool For Resource Constraint Devices
Dec 18, 2020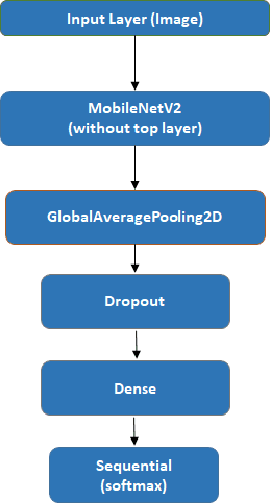
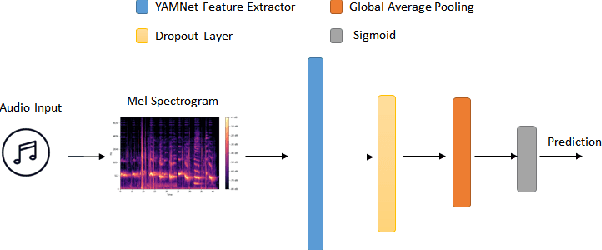
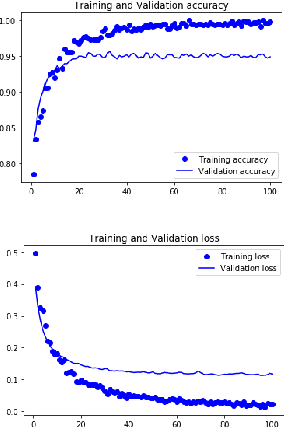
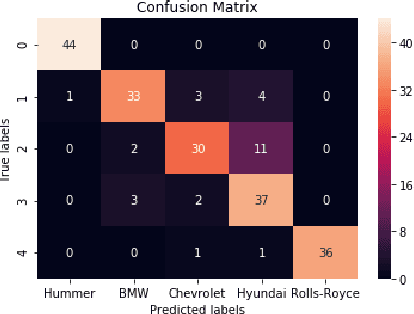
With the enhancement of Machine Learning, many tools are being designed to assist developers to easily create their Machine Learning models. In this paper, we propose a novel method for auto creation of such custom models for constraint devices using transfer learning without the need to write any machine learning code. We share the architecture of our automatic model creation tool and the CNN Model created by it using pretrained models such as YAMNet and MobileNetV2 as feature extractors. Finally, we demonstrate accuracy and memory footprint of the model created from the tool by creating an Automatic Image and Audio classifier and report the results of our experiments using Stanford Cars and ESC-50 dataset.