 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDirected Domain Fine-Tuning: Tailoring Separate Modalities for Specific Training Tasks
Paper and Code
Jun 24, 2024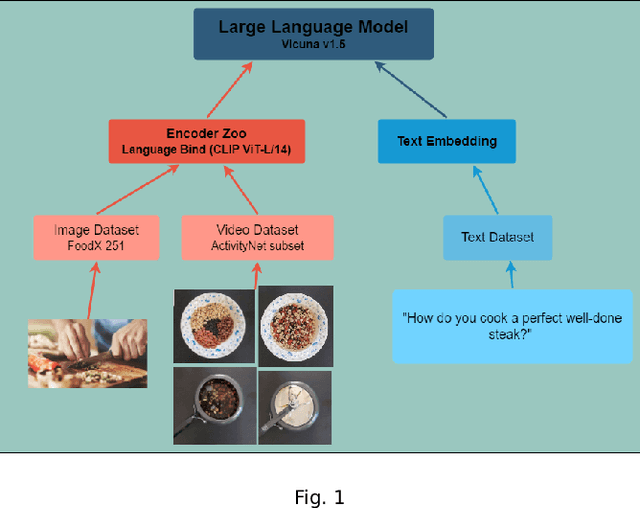

Large language models (LLMs) and large visual language models (LVLMs) have been at the forefront of the artificial intelligence field, particularly for tasks like text generation, video captioning, and question-answering. Typically, it is more applicable to train these models on broader knowledge bases or datasets to increase generalizability, learn relationships between topics, and recognize patterns. Instead, we propose to provide instructional datasets specific to the task of each modality within a distinct domain and then fine-tune the parameters of the model using LORA. With our approach, we can eliminate all noise irrelevant to the given task while also ensuring that the model generates with enhanced precision. For this work, we use Video-LLaVA to generate recipes given cooking videos without transcripts. Video-LLaVA's multimodal architecture allows us to provide cooking images to its image encoder, cooking videos to its video encoder, and general cooking questions to its text encoder. Thus, we aim to remove all noise unrelated to cooking while improving our model's capabilities to generate specific ingredient lists and detailed instructions. As a result, our approach to fine-tuning Video-LLaVA leads to gains over the baseline Video-LLaVA by 2% on the YouCook2 dataset. While this may seem like a marginal increase, our model trains on an image instruction dataset 2.5% the size of Video-LLaVA's and a video instruction dataset 23.76% of Video-LLaVA's.