 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSRNet: Improving Generalization in 3D Human Pose Estimation with a Split-and-Recombine Approach
Jul 18, 2020
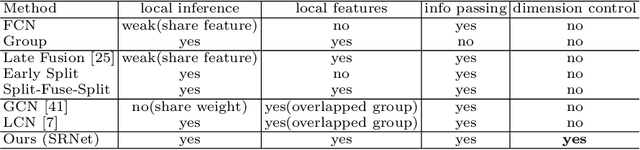

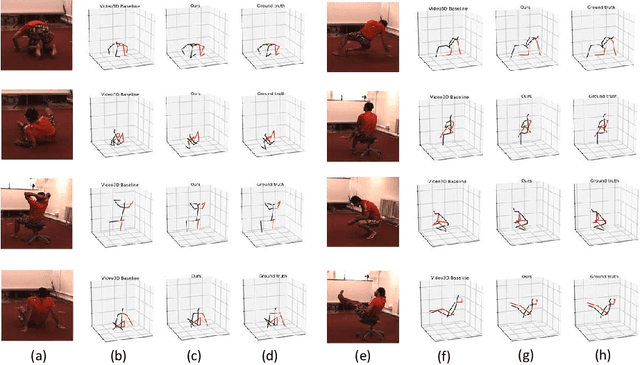
Human poses that are rare or unseen in a training set are challenging for a network to predict. Similar to the long-tailed distribution problem in visual recognition, the small number of examples for such poses limits the ability of networks to model them. Interestingly, local pose distributions suffer less from the long-tail problem, i.e., local joint configurations within a rare pose may appear within other poses in the training set, making them less rare. We propose to take advantage of this fact for better generalization to rare and unseen poses. To be specific, our method splits the body into local regions and processes them in separate network branches, utilizing the property that a joint position depends mainly on the joints within its local body region. Global coherence is maintained by recombining the global context from the rest of the body into each branch as a low-dimensional vector. With the reduced dimensionality of less relevant body areas, the training set distribution within network branches more closely reflects the statistics of local poses instead of global body poses, without sacrificing information important for joint inference. The proposed split-and-recombine approach, called SRNet, can be easily adapted to both single-image and temporal models, and it leads to appreciable improvements in the prediction of rare and unseen poses.
DeepFuse: An IMU-Aware Network for Real-Time 3D Human Pose Estimation from Multi-View Image
Dec 09, 2019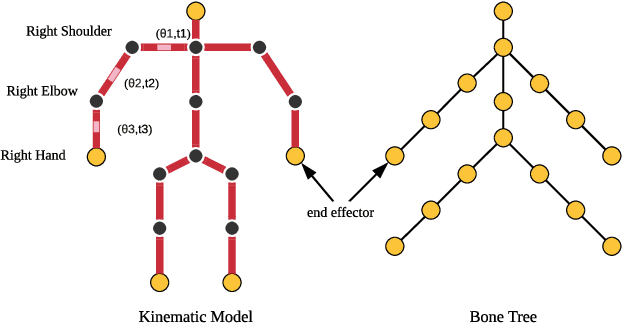

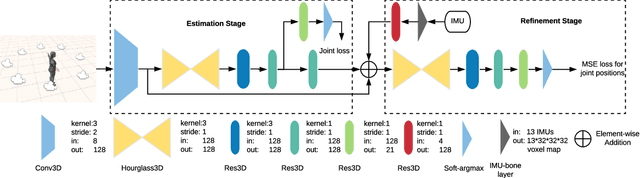
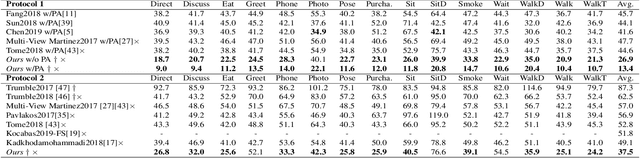
In this paper, we propose a two-stage fully 3D network, namely \textbf{DeepFuse}, to estimate human pose in 3D space by fusing body-worn Inertial Measurement Unit (IMU) data and multi-view images deeply. The first stage is designed for pure vision estimation. To preserve data primitiveness of multi-view inputs, the vision stage uses multi-channel volume as data representation and 3D soft-argmax as activation layer. The second one is the IMU refinement stage which introduces an IMU-bone layer to fuse the IMU and vision data earlier at data level. without requiring a given skeleton model a priori, we can achieve a mean joint error of $28.9$mm on TotalCapture dataset and $13.4$mm on Human3.6M dataset under protocol 1, improving the SOTA result by a large margin. Finally, we discuss the effectiveness of a fully 3D network for 3D pose estimation experimentally which may benefit future research.
Structure-Aware 3D Hourglass Network for Hand Pose Estimation from Single Depth Image
Dec 26, 2018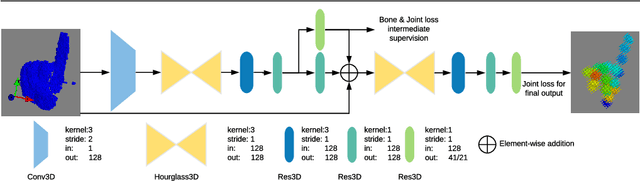

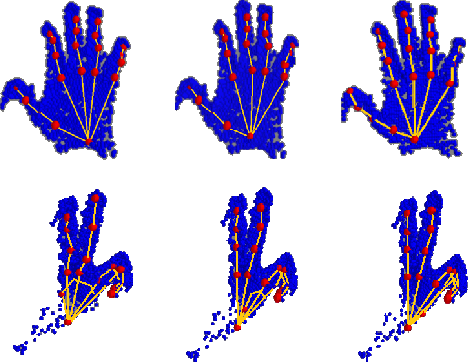

In this paper, we propose a novel structure-aware 3D hourglass network for hand pose estimation from a single depth image, which achieves state-of-the-art results on MSRA and NYU datasets. Compared to existing works that perform image-to-coordination regression, our network takes 3D voxel as input and directly regresses 3D heatmap for each joint. To be specific, we use hourglass network as our backbone network and modify it into 3D form. We explicitly model tree-like finger bone into the network as well as in the loss function in an end-to-end manner, in order to take the skeleton constraints into consideration. Final estimation can then be easily obtained from voxel density map with simple post-processing. Experimental results show that the proposed structure-aware 3D hourglass network is able to achieve a mean joint error of 7.4 mm in MSRA and 8.9 mm in NYU datasets, respectively.