 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInformation Bottleneck Approach to Spatial Attention Learning
Aug 07, 2021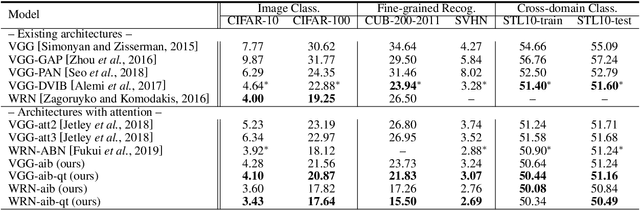

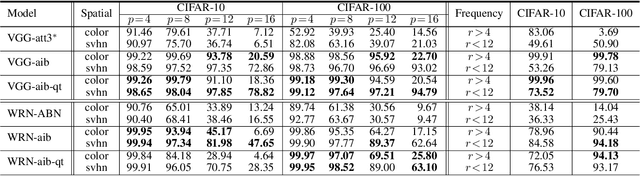
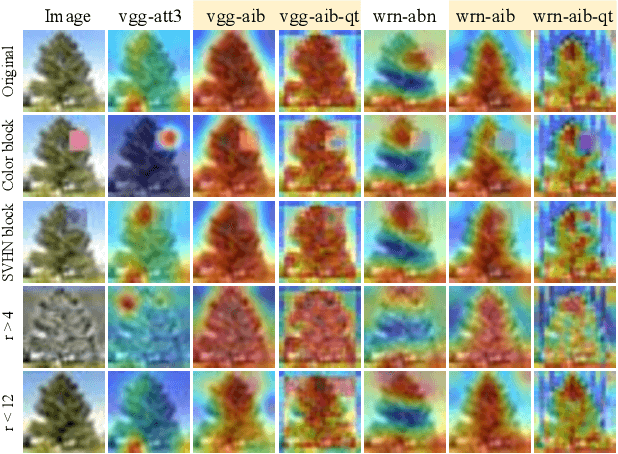
The selective visual attention mechanism in the human visual system (HVS) restricts the amount of information to reach visual awareness for perceiving natural scenes, allowing near real-time information processing with limited computational capacity [Koch and Ullman, 1987]. This kind of selectivity acts as an 'Information Bottleneck (IB)', which seeks a trade-off between information compression and predictive accuracy. However, such information constraints are rarely explored in the attention mechanism for deep neural networks (DNNs). In this paper, we propose an IB-inspired spatial attention module for DNN structures built for visual recognition. The module takes as input an intermediate representation of the input image, and outputs a variational 2D attention map that minimizes the mutual information (MI) between the attention-modulated representation and the input, while maximizing the MI between the attention-modulated representation and the task label. To further restrict the information bypassed by the attention map, we quantize the continuous attention scores to a set of learnable anchor values during training. Extensive experiments show that the proposed IB-inspired spatial attention mechanism can yield attention maps that neatly highlight the regions of interest while suppressing backgrounds, and bootstrap standard DNN structures for visual recognition tasks (e.g., image classification, fine-grained recognition, cross-domain classification). The attention maps are interpretable for the decision making of the DNNs as verified in the experiments. Our code is available at https://github.com/ashleylqx/AIB.git.
Human vs Machine Attention in Neural Networks: A Comparative Study
Jun 24, 2019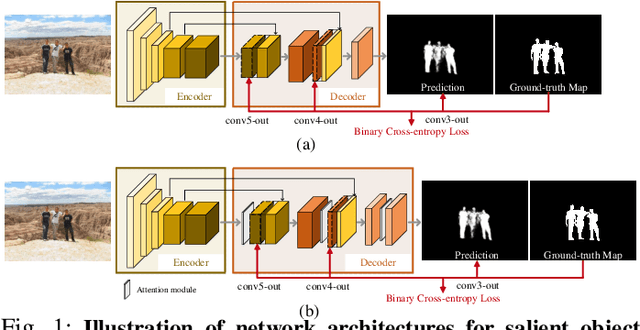
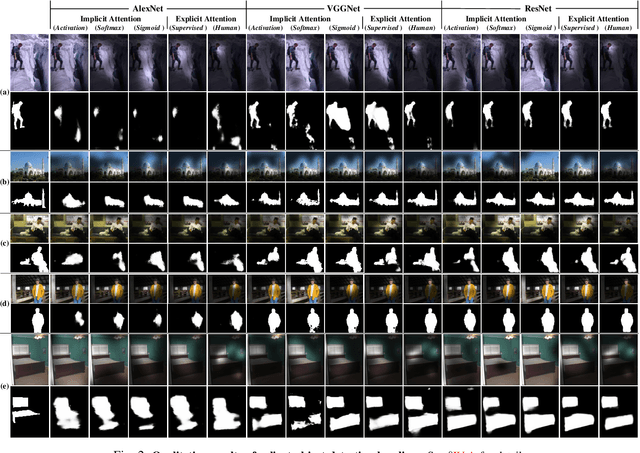
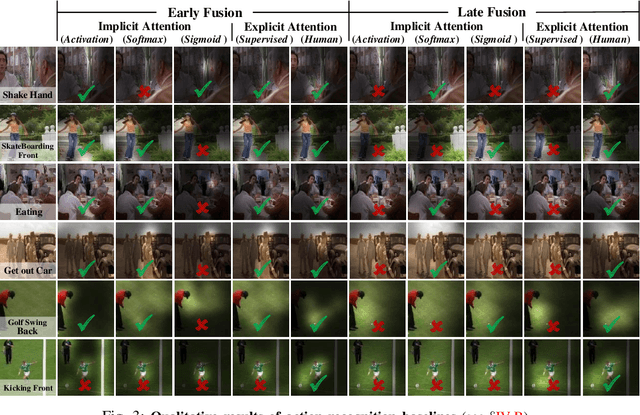
Recent years have witnessed a surge in the popularity of attention mechanisms encoded within deep neural networks. Inspired by the selective attention in the visual cortex, artificial attention is designed to focus a neural network on the most task-relevant input signal. Many works claim that the attention mechanism offers an extra dimension of interpretability by explaining where the neural networks look. However, recent studies demonstrate that artificial attention maps do not always coincide with common intuition. In view of these conflicting evidences, here we make a systematic study on using artificial attention and human attention in neural network design. With three example computer vision tasks (i.e., salient object segmentation, video action recognition, and fine-grained image classification), diverse representative network backbones (i.e., AlexNet, VGGNet, ResNet) and famous architectures (i.e., Two-stream, FCN), corresponding real human gaze data, and systematically conducted large-scale quantitative studies, we offer novel insights into existing artificial attention mechanisms and give preliminary answers to several key questions related to human and artificial attention mechanisms. Our overall results demonstrate that human attention is capable of bench-marking the meaningful `ground-truth' in attention-driven tasks, where the more the artificial attention is close to the human attention, the better the performance; for higher-level vision tasks, it is case-by-case. We believe it would be advisable for attention-driven tasks to explicitly force a better alignment between artificial and human attentions to boost the performance; such alignment would also benefit making the deep networks more transparent and explainable for higher-level computer vision tasks.