 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVF-Eval: Evaluating Multimodal LLMs for Generating Feedback on AIGC Videos
May 29, 2025MLLMs have been widely studied for video question answering recently. However, most existing assessments focus on natural videos, overlooking synthetic videos, such as AI-generated content (AIGC). Meanwhile, some works in video generation rely on MLLMs to evaluate the quality of generated videos, but the capabilities of MLLMs on interpreting AIGC videos remain largely underexplored. To address this, we propose a new benchmark, VF-Eval, which introduces four tasks-coherence validation, error awareness, error type detection, and reasoning evaluation-to comprehensively evaluate the abilities of MLLMs on AIGC videos. We evaluate 13 frontier MLLMs on VF-Eval and find that even the best-performing model, GPT-4.1, struggles to achieve consistently good performance across all tasks. This highlights the challenging nature of our benchmark. Additionally, to investigate the practical applications of VF-Eval in improving video generation, we conduct an experiment, RePrompt, demonstrating that aligning MLLMs more closely with human feedback can benefit video generation.
IFIR: A Comprehensive Benchmark for Evaluating Instruction-Following in Expert-Domain Information Retrieval
Mar 06, 2025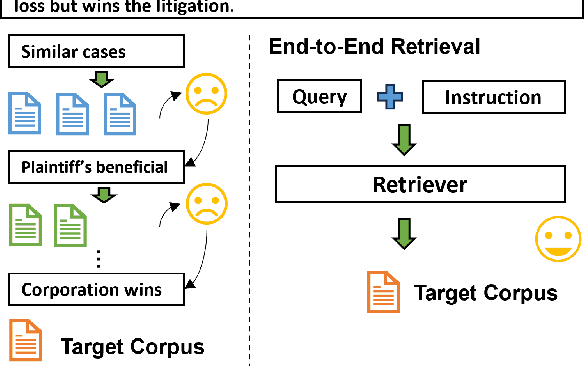



We introduce IFIR, the first comprehensive benchmark designed to evaluate instruction-following information retrieval (IR) in expert domains. IFIR includes 2,426 high-quality examples and covers eight subsets across four specialized domains: finance, law, healthcare, and science literature. Each subset addresses one or more domain-specific retrieval tasks, replicating real-world scenarios where customized instructions are critical. IFIR enables a detailed analysis of instruction-following retrieval capabilities by incorporating instructions at different levels of complexity. We also propose a novel LLM-based evaluation method to provide a more precise and reliable assessment of model performance in following instructions. Through extensive experiments on 15 frontier retrieval models, including those based on LLMs, our results reveal that current models face significant challenges in effectively following complex, domain-specific instructions. We further provide in-depth analyses to highlight these limitations, offering valuable insights to guide future advancements in retriever development.
MMVU: Measuring Expert-Level Multi-Discipline Video Understanding
Jan 21, 2025



We introduce MMVU, a comprehensive expert-level, multi-discipline benchmark for evaluating foundation models in video understanding. MMVU includes 3,000 expert-annotated questions spanning 27 subjects across four core disciplines: Science, Healthcare, Humanities & Social Sciences, and Engineering. Compared to prior benchmarks, MMVU features three key advancements. First, it challenges models to apply domain-specific knowledge and perform expert-level reasoning to analyze specialized-domain videos, moving beyond the basic visual perception typically assessed in current video benchmarks. Second, each example is annotated by human experts from scratch. We implement strict data quality controls to ensure the high quality of the dataset. Finally, each example is enriched with expert-annotated reasoning rationals and relevant domain knowledge, facilitating in-depth analysis. We conduct an extensive evaluation of 32 frontier multimodal foundation models on MMVU. The latest System-2-capable models, o1 and Gemini 2.0 Flash Thinking, achieve the highest performance among the tested models. However, they still fall short of matching human expertise. Through in-depth error analyses and case studies, we offer actionable insights for future advancements in expert-level, knowledge-intensive video understanding for specialized domains.