 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Situated Awareness in the Real World
Feb 18, 2026A core aspect of human perception is situated awareness, the ability to relate ourselves to the surrounding physical environment and reason over possible actions in context. However, most existing benchmarks for multimodal foundation models (MFMs) emphasize environment-centric spatial relations (relations among objects in a scene), while largely overlooking observer-centric relationships that require reasoning relative to agent's viewpoint, pose, and motion. To bridge this gap, we introduce SAW-Bench (Situated Awareness in the Real World), a novel benchmark for evaluating egocentric situated awareness using real-world videos. SAW-Bench comprises 786 self-recorded videos captured with Ray-Ban Meta (Gen 2) smart glasses spanning diverse indoor and outdoor environments, and over 2,071 human-annotated question-answer pairs. It probes a model's observer-centric understanding with six different awareness tasks. Our comprehensive evaluation reveals a human-model performance gap of 37.66%, even with the best-performing MFM, Gemini 3 Flash. Beyond this gap, our in-depth analysis uncovers several notable findings; for example, while models can exploit partial geometric cues in egocentric videos, they often fail to infer a coherent camera geometry, leading to systematic spatial reasoning errors. We position SAW-Bench as a benchmark for situated spatial intelligence, moving beyond passive observation to understanding physically grounded, observer-centric dynamics.
Towards Artificial Intelligence Research Assistant for Expert-Involved Learning
May 03, 2025Large Language Models (LLMs) and Large Multi-Modal Models (LMMs) have emerged as transformative tools in scientific research, yet their reliability and specific contributions to biomedical applications remain insufficiently characterized. In this study, we present \textbf{AR}tificial \textbf{I}ntelligence research assistant for \textbf{E}xpert-involved \textbf{L}earning (ARIEL), a multimodal dataset designed to benchmark and enhance two critical capabilities of LLMs and LMMs in biomedical research: summarizing extensive scientific texts and interpreting complex biomedical figures. To facilitate rigorous assessment, we create two open-source sets comprising biomedical articles and figures with designed questions. We systematically benchmark both open- and closed-source foundation models, incorporating expert-driven human evaluations conducted by doctoral-level experts. Furthermore, we improve model performance through targeted prompt engineering and fine-tuning strategies for summarizing research papers, and apply test-time computational scaling to enhance the reasoning capabilities of LMMs, achieving superior accuracy compared to human-expert corrections. We also explore the potential of using LMM Agents to generate scientific hypotheses from diverse multimodal inputs. Overall, our results delineate clear strengths and highlight significant limitations of current foundation models, providing actionable insights and guiding future advancements in deploying large-scale language and multi-modal models within biomedical research.
MMVU: Measuring Expert-Level Multi-Discipline Video Understanding
Jan 21, 2025



We introduce MMVU, a comprehensive expert-level, multi-discipline benchmark for evaluating foundation models in video understanding. MMVU includes 3,000 expert-annotated questions spanning 27 subjects across four core disciplines: Science, Healthcare, Humanities & Social Sciences, and Engineering. Compared to prior benchmarks, MMVU features three key advancements. First, it challenges models to apply domain-specific knowledge and perform expert-level reasoning to analyze specialized-domain videos, moving beyond the basic visual perception typically assessed in current video benchmarks. Second, each example is annotated by human experts from scratch. We implement strict data quality controls to ensure the high quality of the dataset. Finally, each example is enriched with expert-annotated reasoning rationals and relevant domain knowledge, facilitating in-depth analysis. We conduct an extensive evaluation of 32 frontier multimodal foundation models on MMVU. The latest System-2-capable models, o1 and Gemini 2.0 Flash Thinking, achieve the highest performance among the tested models. However, they still fall short of matching human expertise. Through in-depth error analyses and case studies, we offer actionable insights for future advancements in expert-level, knowledge-intensive video understanding for specialized domains.
M3SciQA: A Multi-Modal Multi-Document Scientific QA Benchmark for Evaluating Foundation Models
Nov 06, 2024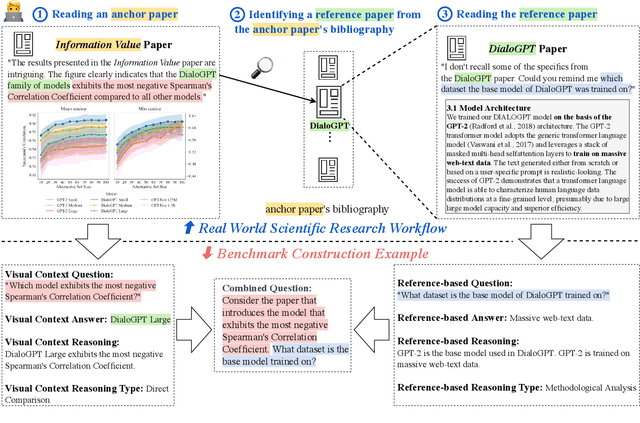


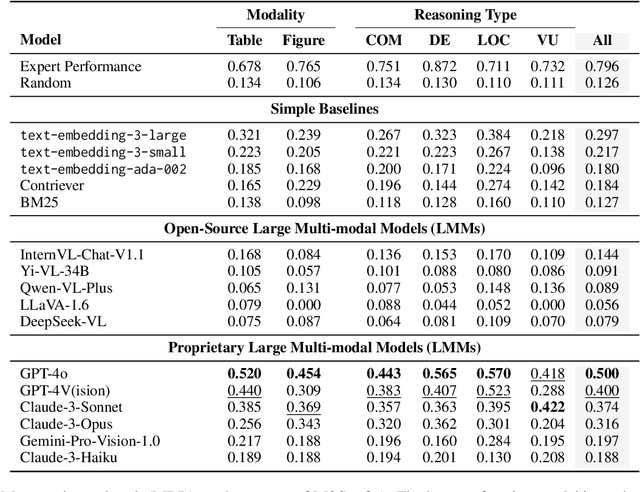
Existing benchmarks for evaluating foundation models mainly focus on single-document, text-only tasks. However, they often fail to fully capture the complexity of research workflows, which typically involve interpreting non-textual data and gathering information across multiple documents. To address this gap, we introduce M3SciQA, a multi-modal, multi-document scientific question answering benchmark designed for a more comprehensive evaluation of foundation models. M3SciQA consists of 1,452 expert-annotated questions spanning 70 natural language processing paper clusters, where each cluster represents a primary paper along with all its cited documents, mirroring the workflow of comprehending a single paper by requiring multi-modal and multi-document data. With M3SciQA, we conduct a comprehensive evaluation of 18 foundation models. Our results indicate that current foundation models still significantly underperform compared to human experts in multi-modal information retrieval and in reasoning across multiple scientific documents. Additionally, we explore the implications of these findings for the future advancement of applying foundation models in multi-modal scientific literature analysis.
TOMATO: Assessing Visual Temporal Reasoning Capabilities in Multimodal Foundation Models
Oct 30, 2024



Existing benchmarks often highlight the remarkable performance achieved by state-of-the-art Multimodal Foundation Models (MFMs) in leveraging temporal context for video understanding. However, how well do the models truly perform visual temporal reasoning? Our study of existing benchmarks shows that this capability of MFMs is likely overestimated as many questions can be solved by using a single, few, or out-of-order frames. To systematically examine current visual temporal reasoning tasks, we propose three principles with corresponding metrics: (1) Multi-Frame Gain, (2) Frame Order Sensitivity, and (3) Frame Information Disparity. Following these principles, we introduce TOMATO, Temporal Reasoning Multimodal Evaluation, a novel benchmark crafted to rigorously assess MFMs' temporal reasoning capabilities in video understanding. TOMATO comprises 1,484 carefully curated, human-annotated questions spanning six tasks (i.e., action count, direction, rotation, shape & trend, velocity & frequency, and visual cues), applied to 1,417 videos, including 805 self-recorded and -generated videos, that encompass human-centric, real-world, and simulated scenarios. Our comprehensive evaluation reveals a human-model performance gap of 57.3% with the best-performing model. Moreover, our in-depth analysis uncovers more fundamental limitations beyond this gap in current MFMs. While they can accurately recognize events in isolated frames, they fail to interpret these frames as a continuous sequence. We believe TOMATO will serve as a crucial testbed for evaluating the next-generation MFMs and as a call to the community to develop AI systems capable of comprehending human world dynamics through the video modality.