 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNatural-language-driven Simulation Benchmark and Copilot for Efficient Production of Object Interactions in Virtual Road Scenes
Dec 15, 2023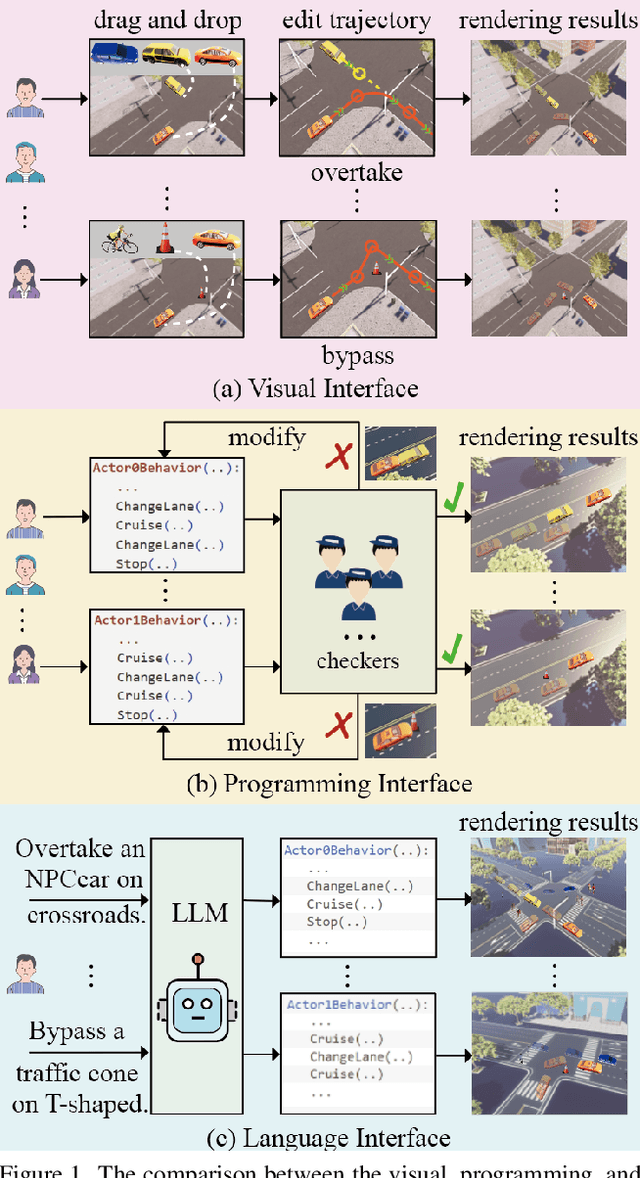

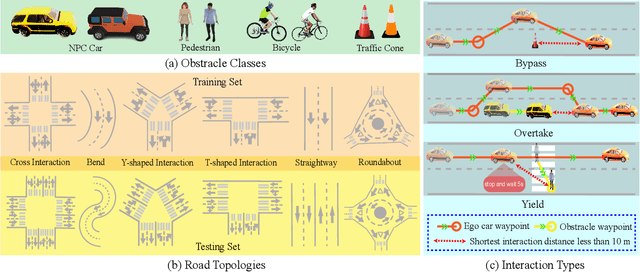

We advocate the idea of the natural-language-driven(NLD) simulation to efficiently produce the object interactions between multiple objects in the virtual road scenes, for teaching and testing the autonomous driving systems that should take quick action to avoid collision with obstacles with unpredictable motions. The NLD simulation allows the brief natural-language description to control the object interactions, significantly reducing the human efforts for creating a large amount of interaction data. To facilitate the research of NLD simulation, we collect the Language-to-Interaction(L2I) benchmark dataset with 120,000 natural-language descriptions of object interactions in 6 common types of road topologies. Each description is associated with the programming code, which the graphic render can use to visually reconstruct the object interactions in the virtual scenes. As a methodology contribution, we design SimCopilot to translate the interaction descriptions to the renderable code. We use the L2I dataset to evaluate SimCopilot's abilities to control the object motions, generate complex interactions, and generalize interactions across road topologies. The L2I dataset and the evaluation results motivate the relevant research of the NLD simulation.
BEVControl: Accurately Controlling Street-view Elements with Multi-perspective Consistency via BEV Sketch Layout
Aug 07, 2023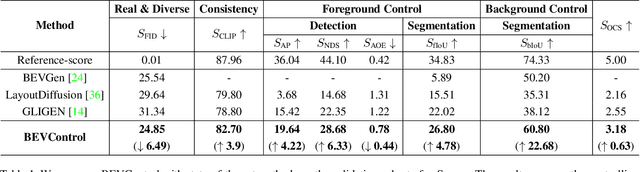
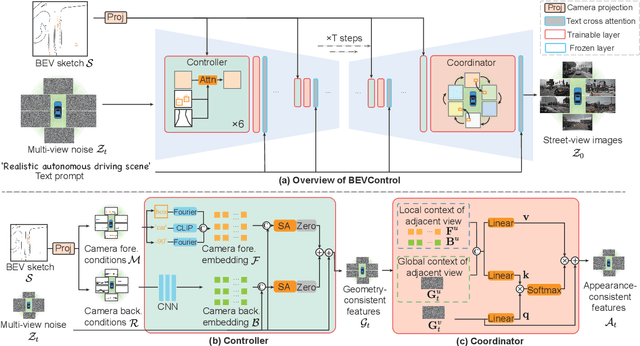
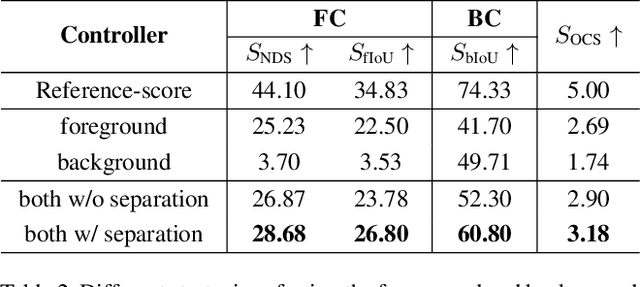
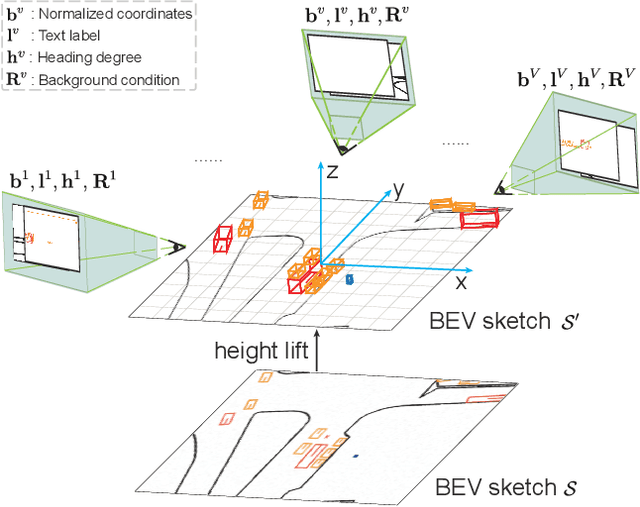
Using synthesized images to boost the performance of perception models is a long-standing research challenge in computer vision. It becomes more eminent in visual-centric autonomous driving systems with multi-view cameras as some long-tail scenarios can never be collected. Guided by the BEV segmentation layouts, the existing generative networks seem to synthesize photo-realistic street-view images when evaluated solely on scene-level metrics. However, once zoom-in, they usually fail to produce accurate foreground and background details such as heading. To this end, we propose a two-stage generative method, dubbed BEVControl, that can generate accurate foreground and background contents. In contrast to segmentation-like input, it also supports sketch style input, which is more flexible for humans to edit. In addition, we propose a comprehensive multi-level evaluation protocol to fairly compare the quality of the generated scene, foreground object, and background geometry. Our extensive experiments show that our BEVControl surpasses the state-of-the-art method, BEVGen, by a significant margin, from 5.89 to 26.80 on foreground segmentation mIoU. In addition, we show that using images generated by BEVControl to train the downstream perception model, it achieves on average 1.29 improvement in NDS score.