 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTopicwise Separable Sentence Retrieval for Medical Report Generation
May 07, 2024



Automated radiology reporting holds immense clinical potential in alleviating the burdensome workload of radiologists and mitigating diagnostic bias. Recently, retrieval-based report generation methods have garnered increasing attention due to their inherent advantages in terms of the quality and consistency of generated reports. However, due to the long-tail distribution of the training data, these models tend to learn frequently occurring sentences and topics, overlooking the rare topics. Regrettably, in many cases, the descriptions of rare topics often indicate critical findings that should be mentioned in the report. To address this problem, we introduce a Topicwise Separable Sentence Retrieval (Teaser) for medical report generation. To ensure comprehensive learning of both common and rare topics, we categorize queries into common and rare types to learn differentiated topics, and then propose Topic Contrastive Loss to effectively align topics and queries in the latent space. Moreover, we integrate an Abstractor module following the extraction of visual features, which aids the topic decoder in gaining a deeper understanding of the visual observational intent. Experiments on the MIMIC-CXR and IU X-ray datasets demonstrate that Teaser surpasses state-of-the-art models, while also validating its capability to effectively represent rare topics and establish more dependable correspondences between queries and topics.
Medical Phrase Grounding with Region-Phrase Context Contrastive Alignment
Mar 14, 2023
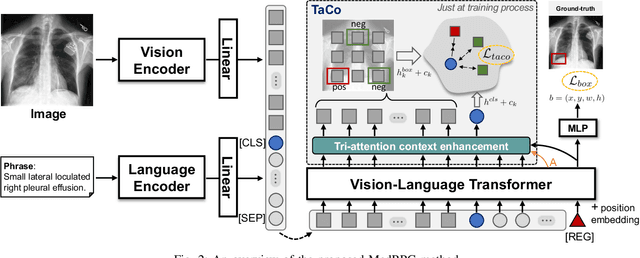
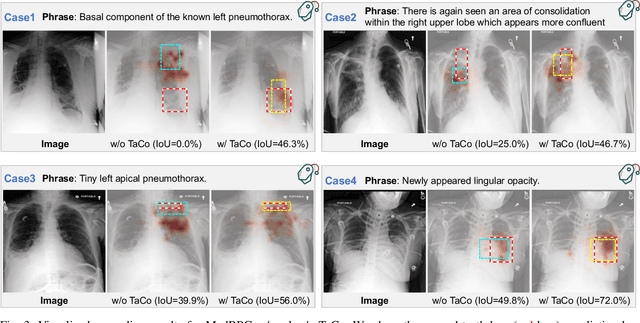
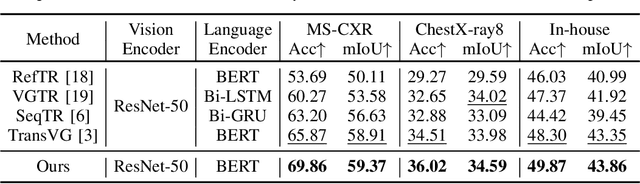
Medical phrase grounding (MPG) aims to locate the most relevant region in a medical image, given a phrase query describing certain medical findings, which is an important task for medical image analysis and radiological diagnosis. However, existing visual grounding methods rely on general visual features for identifying objects in natural images and are not capable of capturing the subtle and specialized features of medical findings, leading to sub-optimal performance in MPG. In this paper, we propose MedRPG, an end-to-end approach for MPG. MedRPG is built on a lightweight vision-language transformer encoder and directly predicts the box coordinates of mentioned medical findings, which can be trained with limited medical data, making it a valuable tool in medical image analysis. To enable MedRPG to locate nuanced medical findings with better region-phrase correspondences, we further propose Tri-attention Context contrastive alignment (TaCo). TaCo seeks context alignment to pull both the features and attention outputs of relevant region-phrase pairs close together while pushing those of irrelevant regions far away. This ensures that the final box prediction depends more on its finding-specific regions and phrases. Experimental results on three MPG datasets demonstrate that our MedRPG outperforms state-of-the-art visual grounding approaches by a large margin. Additionally, the proposed TaCo strategy is effective in enhancing finding localization ability and reducing spurious region-phrase correlations.