 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIs Grokking Worthwhile? Functional Analysis and Transferability of Generalization Circuits in Transformers
Jan 14, 2026While Large Language Models (LLMs) excel at factual retrieval, they often struggle with the "curse of two-hop reasoning" in compositional tasks. Recent research suggests that parameter-sharing transformers can bridge this gap by forming a "Generalization Circuit" during a prolonged "grokking" phase. A fundamental question arises: Is a grokked model superior to its non-grokked counterparts on downstream tasks? Furthermore, is the extensive computational cost of waiting for the grokking phase worthwhile? In this work, we conduct a mechanistic study to evaluate the Generalization Circuit's role in knowledge assimilation and transfer. We demonstrate that: (i) The inference paths established by non-grokked and grokked models for in-distribution compositional queries are identical. This suggests that the "Generalization Circuit" does not represent the sudden acquisition of a new reasoning paradigm. Instead, we argue that grokking is the process of integrating memorized atomic facts into an naturally established reasoning path. (ii) Achieving high accuracy on unseen cases after prolonged training and the formation of a certain reasoning path are not bound; they can occur independently under specific data regimes. (iii) Even a mature circuit exhibits limited transferability when integrating new knowledge, suggesting that "grokked" Transformers do not achieve a full mastery of compositional logic.
HiPRAG: Hierarchical Process Rewards for Efficient Agentic Retrieval Augmented Generation
Oct 09, 2025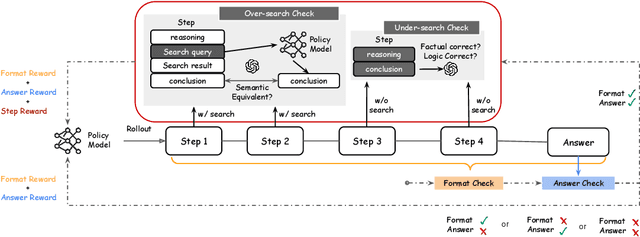
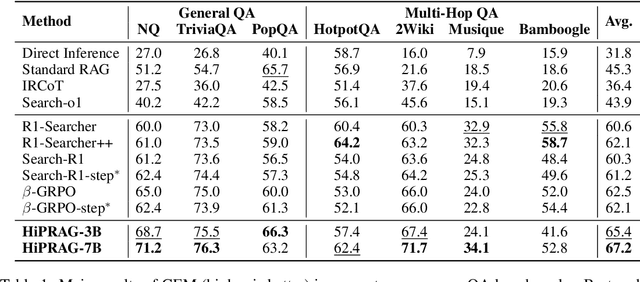
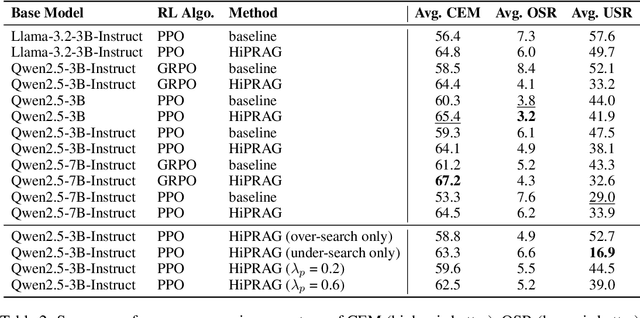
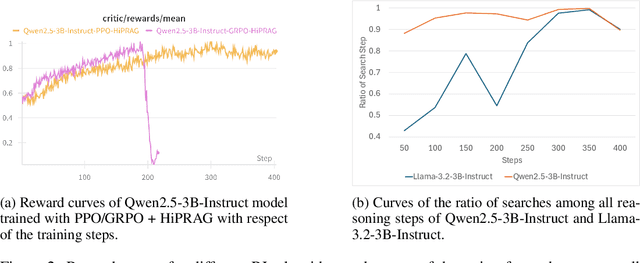
Agentic RAG is a powerful technique for incorporating external information that LLMs lack, enabling better problem solving and question answering. However, suboptimal search behaviors exist widely, such as over-search (retrieving information already known) and under-search (failing to search when necessary), which leads to unnecessary overhead and unreliable outputs. Current training methods, which typically rely on outcome-based rewards in a RL framework, lack the fine-grained control needed to address these inefficiencies. To overcome this, we introduce Hierarchical Process Rewards for Efficient agentic RAG (HiPRAG), a training methodology that incorporates a fine-grained, knowledge-grounded process reward into the RL training. Our approach evaluates the necessity of each search decision on-the-fly by decomposing the agent's reasoning trajectory into discrete, parsable steps. We then apply a hierarchical reward function that provides an additional bonus based on the proportion of optimal search and non-search steps, on top of commonly used outcome and format rewards. Experiments on the Qwen2.5 and Llama-3.2 models across seven diverse QA benchmarks show that our method achieves average accuracies of 65.4% (3B) and 67.2% (7B). This is accomplished while improving search efficiency, reducing the over-search rate to just 2.3% and concurrently lowering the under-search rate. These results demonstrate the efficacy of optimizing the reasoning process itself, not just the final outcome. Further experiments and analysis demonstrate that HiPRAG shows good generalizability across a wide range of RL algorithms, model families, sizes, and types. This work demonstrates the importance and potential of fine-grained control through RL, for improving the efficiency and optimality of reasoning for search agents.
Do We Still Need Audio? Rethinking Speaker Diarization with a Text-Based Approach Using Multiple Prediction Models
Jun 12, 2025



We present a novel approach to Speaker Diarization (SD) by leveraging text-based methods focused on Sentence-level Speaker Change Detection within dialogues. Unlike audio-based SD systems, which are often challenged by audio quality and speaker similarity, our approach utilizes the dialogue transcript alone. Two models are developed: the Single Prediction Model (SPM) and the Multiple Prediction Model (MPM), both of which demonstrate significant improvements in identifying speaker changes, particularly in short conversations. Our findings, based on a curated dataset encompassing diverse conversational scenarios, reveal that the text-based SD approach, especially the MPM, performs competitively against state-of-the-art audio-based SD systems, with superior performance in short conversational contexts. This paper not only showcases the potential of leveraging linguistic features for SD but also highlights the importance of integrating semantic understanding into SD systems, opening avenues for future research in multimodal and semantic feature-based diarization.
Search Wisely: Mitigating Sub-optimal Agentic Searches By Reducing Uncertainty
May 22, 2025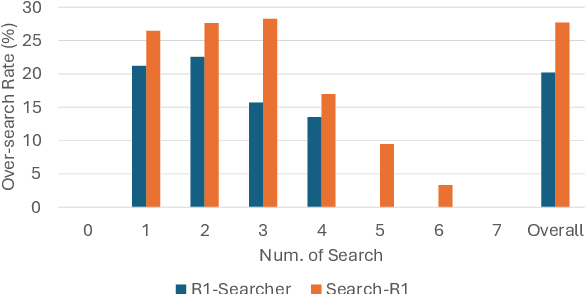
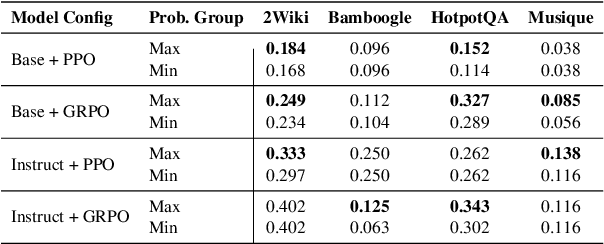
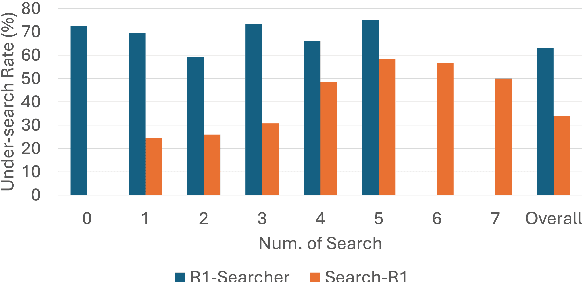
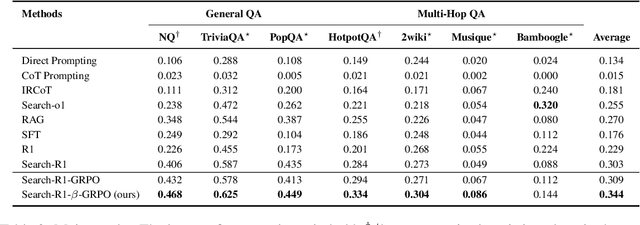
Agentic Retrieval-Augmented Generation (RAG) systems enhance Large Language Models (LLMs) by enabling dynamic, multi-step reasoning and information retrieval. However, these systems often exhibit sub-optimal search behaviors like over-search (retrieving redundant information) and under-search (failing to retrieve necessary information), which hinder efficiency and reliability. This work formally defines and quantifies these behaviors, revealing their prevalence across multiple QA datasets and agentic RAG systems (e.g., one model could have avoided searching in 27.7% of its search steps). Furthermore, we demonstrate a crucial link between these inefficiencies and the models' uncertainty regarding their own knowledge boundaries, where response accuracy correlates with model's uncertainty in its search decisions. To address this, we propose $\beta$-GRPO, a reinforcement learning-based training method that incorporates confidence threshold to reward high-certainty search decisions. Experiments on seven QA benchmarks show that $\beta$-GRPO enable a 3B model with better agentic RAG ability, outperforming other strong baselines with a 4% higher average exact match score.
Do Retrieval-Augmented Language Models Adapt to Varying User Needs?
Feb 27, 2025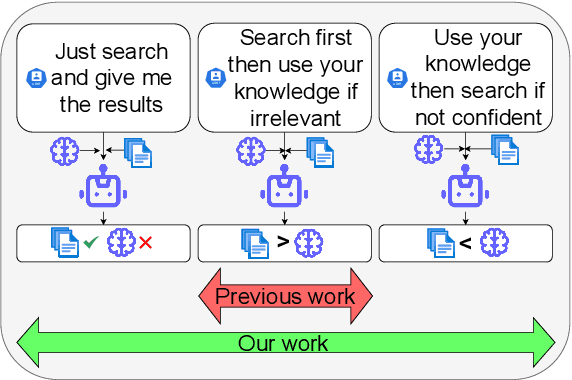


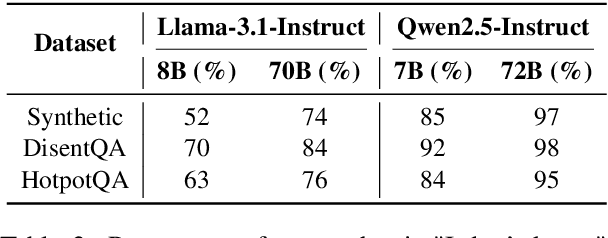
Recent advancements in Retrieval-Augmented Language Models (RALMs) have demonstrated their efficacy in knowledge-intensive tasks. However, existing evaluation benchmarks often assume a single optimal approach to leveraging retrieved information, failing to account for varying user needs. This paper introduces a novel evaluation framework that systematically assesses RALMs under three user need cases-Context-Exclusive, Context-First, and Memory-First-across three distinct context settings: Context Matching, Knowledge Conflict, and Information Irrelevant. By varying both user instructions and the nature of retrieved information, our approach captures the complexities of real-world applications where models must adapt to diverse user requirements. Through extensive experiments on multiple QA datasets, including HotpotQA, DisentQA, and our newly constructed synthetic URAQ dataset, we find that restricting memory usage improves robustness in adversarial retrieval conditions but decreases peak performance with ideal retrieval results and model family dominates behavioral differences. Our findings highlight the necessity of user-centric evaluations in the development of retrieval-augmented systems and provide insights into optimizing model performance across varied retrieval contexts. We will release our code and URAQ dataset upon acceptance of the paper.
LoopSR: Looping Sim-and-Real for Lifelong Policy Adaptation of Legged Robots
Sep 26, 2024Reinforcement Learning (RL) has shown its remarkable and generalizable capability in legged locomotion through sim-to-real transfer. However, while adaptive methods like domain randomization are expected to make policy more robust to diverse environments, such comprehensiveness potentially detracts from the policy's performance in any specific environment according to the No Free Lunch theorem, leading to a suboptimal solution once deployed in the real world. To address this issue, we propose a lifelong policy adaptation framework named LoopSR, which utilizes a transformer-based encoder to project real-world trajectories into a latent space, and accordingly reconstruct the real-world environments back in simulation for further improvement. Autoencoder architecture and contrastive learning methods are adopted to better extract the characteristics of real-world dynamics. The simulation parameters for continual training are derived by combining predicted parameters from the decoder with retrieved parameters from the simulation trajectory dataset. By leveraging the continual training, LoopSR achieves superior data efficiency compared with strong baselines, with only a limited amount of data to yield eminent performance in both sim-to-sim and sim-to-real experiments.
Aligning Speakers: Evaluating and Visualizing Text-based Diarization Using Efficient Multiple Sequence Alignment (Extended Version)
Sep 14, 2023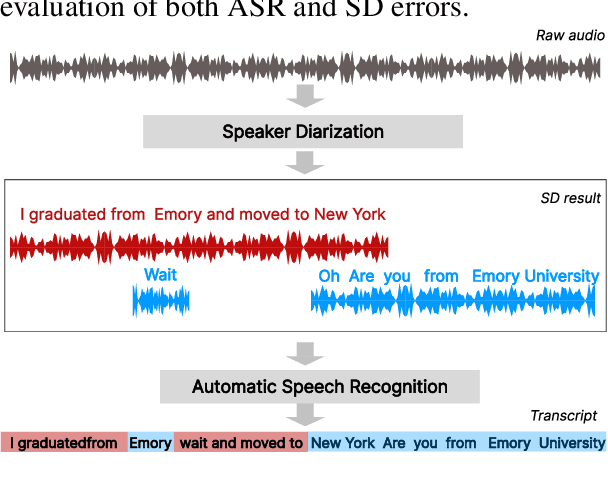


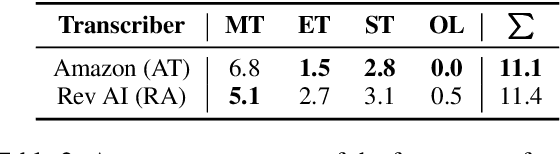
This paper presents a novel evaluation approach to text-based speaker diarization (SD), tackling the limitations of traditional metrics that do not account for any contextual information in text. Two new metrics are proposed, Text-based Diarization Error Rate and Diarization F1, which perform utterance- and word-level evaluations by aligning tokens in reference and hypothesis transcripts. Our metrics encompass more types of errors compared to existing ones, allowing us to make a more comprehensive analysis in SD. To align tokens, a multiple sequence alignment algorithm is introduced that supports multiple sequences in the reference while handling high-dimensional alignment to the hypothesis using dynamic programming. Our work is packaged into two tools, align4d providing an API for our alignment algorithm and TranscribeView for visualizing and evaluating SD errors, which can greatly aid in the creation of high-quality data, fostering the advancement of dialogue systems.