 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSkywork UniPic 3.0: Unified Multi-Image Composition via Sequence Modeling
Jan 22, 2026The recent surge in popularity of Nano-Banana and Seedream 4.0 underscores the community's strong interest in multi-image composition tasks. Compared to single-image editing, multi-image composition presents significantly greater challenges in terms of consistency and quality, yet existing models have not disclosed specific methodological details for achieving high-quality fusion. Through statistical analysis, we identify Human-Object Interaction (HOI) as the most sought-after category by the community. We therefore systematically analyze and implement a state-of-the-art solution for multi-image composition with a primary focus on HOI-centric tasks. We present Skywork UniPic 3.0, a unified multimodal framework that integrates single-image editing and multi-image composition. Our model supports an arbitrary (1~6) number and resolution of input images, as well as arbitrary output resolutions (within a total pixel budget of 1024x1024). To address the challenges of multi-image composition, we design a comprehensive data collection, filtering, and synthesis pipeline, achieving strong performance with only 700K high-quality training samples. Furthermore, we introduce a novel training paradigm that formulates multi-image composition as a sequence-modeling problem, transforming conditional generation into unified sequence synthesis. To accelerate inference, we integrate trajectory mapping and distribution matching into the post-training stage, enabling the model to produce high-fidelity samples in just 8 steps and achieve a 12.5x speedup over standard synthesis sampling. Skywork UniPic 3.0 achieves state-of-the-art performance on single-image editing benchmark and surpasses both Nano-Banana and Seedream 4.0 on multi-image composition benchmark, thereby validating the effectiveness of our data pipeline and training paradigm. Code, models and dataset are publicly available.
Skywork UniPic 2.0: Building Kontext Model with Online RL for Unified Multimodal Model
Sep 04, 2025

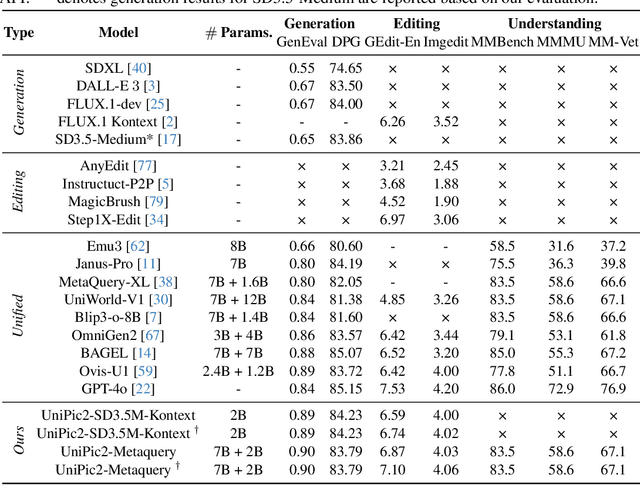
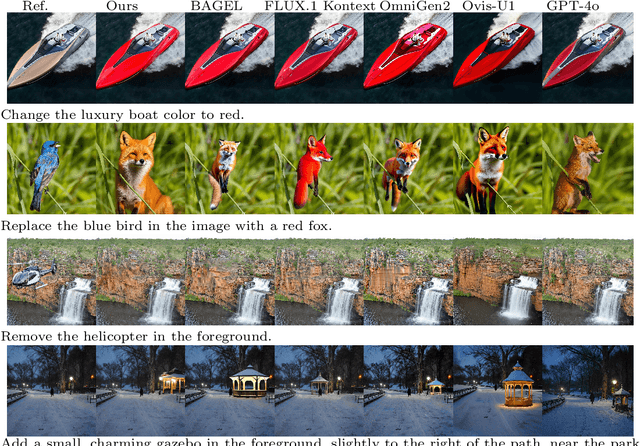
Recent advances in multimodal models have demonstrated impressive capabilities in unified image generation and editing. However, many prominent open-source models prioritize scaling model parameters over optimizing training strategies, limiting their efficiency and performance. In this work, we present UniPic2-SD3.5M-Kontext, a 2B-parameter DiT model based on SD3.5-Medium, which achieves state-of-the-art image generation and editing while extending seamlessly into a unified multimodal framework. Our approach begins with architectural modifications to SD3.5-Medium and large-scale pre-training on high-quality data, enabling joint text-to-image generation and editing capabilities. To enhance instruction following and editing consistency, we propose a novel Progressive Dual-Task Reinforcement strategy (PDTR), which effectively strengthens both tasks in a staged manner. We empirically validate that the reinforcement phases for different tasks are mutually beneficial and do not induce negative interference. After pre-training and reinforcement strategies, UniPic2-SD3.5M-Kontext demonstrates stronger image generation and editing capabilities than models with significantly larger generation parameters-including BAGEL (7B) and Flux-Kontext (12B). Furthermore, following the MetaQuery, we connect the UniPic2-SD3.5M-Kontext and Qwen2.5-VL-7B via a connector and perform joint training to launch a unified multimodal model UniPic2-Metaquery. UniPic2-Metaquery integrates understanding, generation, and editing, achieving top-tier performance across diverse tasks with a simple and scalable training paradigm. This consistently validates the effectiveness and generalizability of our proposed training paradigm, which we formalize as Skywork UniPic 2.0.
MeshCraft: Exploring Efficient and Controllable Mesh Generation with Flow-based DiTs
Mar 29, 2025In the domain of 3D content creation, achieving optimal mesh topology through AI models has long been a pursuit for 3D artists. Previous methods, such as MeshGPT, have explored the generation of ready-to-use 3D objects via mesh auto-regressive techniques. While these methods produce visually impressive results, their reliance on token-by-token predictions in the auto-regressive process leads to several significant limitations. These include extremely slow generation speeds and an uncontrollable number of mesh faces. In this paper, we introduce MeshCraft, a novel framework for efficient and controllable mesh generation, which leverages continuous spatial diffusion to generate discrete triangle faces. Specifically, MeshCraft consists of two core components: 1) a transformer-based VAE that encodes raw meshes into continuous face-level tokens and decodes them back to the original meshes, and 2) a flow-based diffusion transformer conditioned on the number of faces, enabling the generation of high-quality 3D meshes with a predefined number of faces. By utilizing the diffusion model for the simultaneous generation of the entire mesh topology, MeshCraft achieves high-fidelity mesh generation at significantly faster speeds compared to auto-regressive methods. Specifically, MeshCraft can generate an 800-face mesh in just 3.2 seconds (35$\times$ faster than existing baselines). Extensive experiments demonstrate that MeshCraft outperforms state-of-the-art techniques in both qualitative and quantitative evaluations on ShapeNet dataset and demonstrates superior performance on Objaverse dataset. Moreover, it integrates seamlessly with existing conditional guidance strategies, showcasing its potential to relieve artists from the time-consuming manual work involved in mesh creation.
TripoSG: High-Fidelity 3D Shape Synthesis using Large-Scale Rectified Flow Models
Feb 10, 2025Recent advancements in diffusion techniques have propelled image and video generation to unprece- dented levels of quality, significantly accelerating the deployment and application of generative AI. However, 3D shape generation technology has so far lagged behind, constrained by limitations in 3D data scale, complexity of 3D data process- ing, and insufficient exploration of advanced tech- niques in the 3D domain. Current approaches to 3D shape generation face substantial challenges in terms of output quality, generalization capa- bility, and alignment with input conditions. We present TripoSG, a new streamlined shape diffu- sion paradigm capable of generating high-fidelity 3D meshes with precise correspondence to input images. Specifically, we propose: 1) A large-scale rectified flow transformer for 3D shape generation, achieving state-of-the-art fidelity through training on extensive, high-quality data. 2) A hybrid supervised training strategy combining SDF, normal, and eikonal losses for 3D VAE, achieving high- quality 3D reconstruction performance. 3) A data processing pipeline to generate 2 million high- quality 3D samples, highlighting the crucial rules for data quality and quantity in training 3D gen- erative models. Through comprehensive experi- ments, we have validated the effectiveness of each component in our new framework. The seamless integration of these parts has enabled TripoSG to achieve state-of-the-art performance in 3D shape generation. The resulting 3D shapes exhibit en- hanced detail due to high-resolution capabilities and demonstrate exceptional fidelity to input im- ages. Moreover, TripoSG demonstrates improved versatility in generating 3D models from diverse image styles and contents, showcasing strong gen- eralization capabilities. To foster progress and innovation in the field of 3D generation, we will make our model publicly available.
TripoSR: Fast 3D Object Reconstruction from a Single Image
Mar 04, 2024



This technical report introduces TripoSR, a 3D reconstruction model leveraging transformer architecture for fast feed-forward 3D generation, producing 3D mesh from a single image in under 0.5 seconds. Building upon the LRM network architecture, TripoSR integrates substantial improvements in data processing, model design, and training techniques. Evaluations on public datasets show that TripoSR exhibits superior performance, both quantitatively and qualitatively, compared to other open-source alternatives. Released under the MIT license, TripoSR is intended to empower researchers, developers, and creatives with the latest advancements in 3D generative AI.
UniDream: Unifying Diffusion Priors for Relightable Text-to-3D Generation
Dec 14, 2023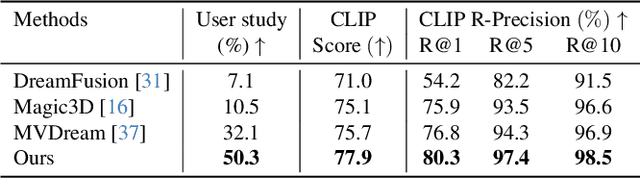
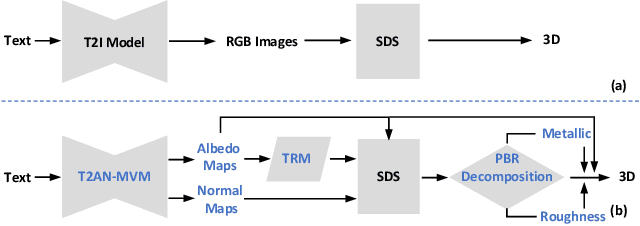
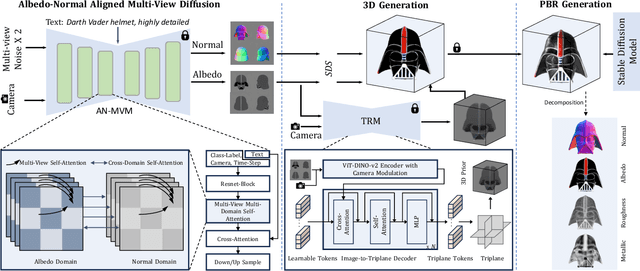

Recent advancements in text-to-3D generation technology have significantly advanced the conversion of textual descriptions into imaginative well-geometrical and finely textured 3D objects. Despite these developments, a prevalent limitation arises from the use of RGB data in diffusion or reconstruction models, which often results in models with inherent lighting and shadows effects that detract from their realism, thereby limiting their usability in applications that demand accurate relighting capabilities. To bridge this gap, we present UniDream, a text-to-3D generation framework by incorporating unified diffusion priors. Our approach consists of three main components: (1) a dual-phase training process to get albedo-normal aligned multi-view diffusion and reconstruction models, (2) a progressive generation procedure for geometry and albedo-textures based on Score Distillation Sample (SDS) using the trained reconstruction and diffusion models, and (3) an innovative application of SDS for finalizing PBR generation while keeping a fixed albedo based on Stable Diffusion model. Extensive evaluations demonstrate that UniDream surpasses existing methods in generating 3D objects with clearer albedo textures, smoother surfaces, enhanced realism, and superior relighting capabilities.
On the Hardness of Learning to Stabilize Linear Systems
Nov 18, 2023Inspired by the work of Tsiamis et al. \cite{tsiamis2022learning}, in this paper we study the statistical hardness of learning to stabilize linear time-invariant systems. Hardness is measured by the number of samples required to achieve a learning task with a given probability. The work in \cite{tsiamis2022learning} shows that there exist system classes that are hard to learn to stabilize with the core reason being the hardness of identification. Here we present a class of systems that can be easy to identify, thanks to a non-degenerate noise process that excites all modes, but the sample complexity of stabilization still increases exponentially with the system dimension. We tie this result to the hardness of co-stabilizability for this class of systems using ideas from robust control.
Linear Video Transformer with Feature Fixation
Oct 15, 2022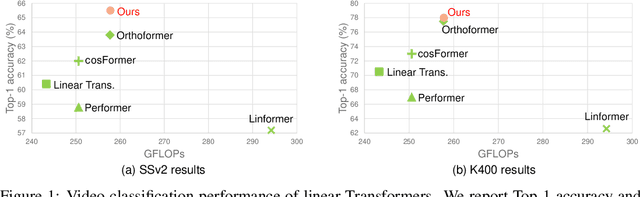
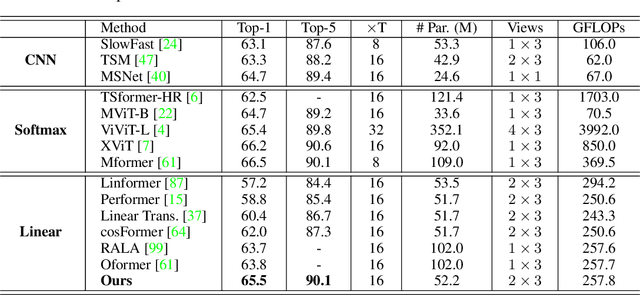

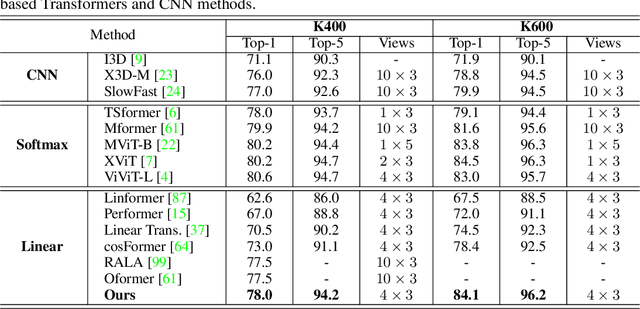
Vision Transformers have achieved impressive performance in video classification, while suffering from the quadratic complexity caused by the Softmax attention mechanism. Some studies alleviate the computational costs by reducing the number of tokens in attention calculation, but the complexity is still quadratic. Another promising way is to replace Softmax attention with linear attention, which owns linear complexity but presents a clear performance drop. We find that such a drop in linear attention results from the lack of attention concentration on critical features. Therefore, we propose a feature fixation module to reweight the feature importance of the query and key before computing linear attention. Specifically, we regard the query, key, and value as various latent representations of the input token, and learn the feature fixation ratio by aggregating Query-Key-Value information. This is beneficial for measuring the feature importance comprehensively. Furthermore, we enhance the feature fixation by neighborhood association, which leverages additional guidance from spatial and temporal neighbouring tokens. The proposed method significantly improves the linear attention baseline and achieves state-of-the-art performance among linear video Transformers on three popular video classification benchmarks. With fewer parameters and higher efficiency, our performance is even comparable to some Softmax-based quadratic Transformers.
Neural Architecture Search on Efficient Transformers and Beyond
Jul 28, 2022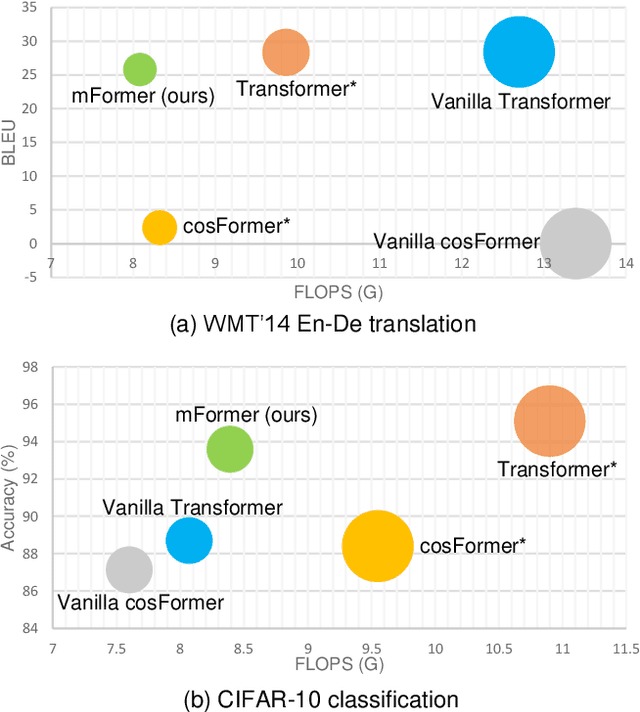
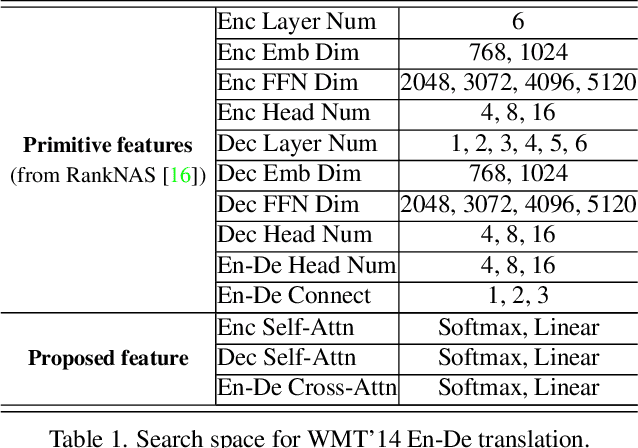


Recently, numerous efficient Transformers have been proposed to reduce the quadratic computational complexity of standard Transformers caused by the Softmax attention. However, most of them simply swap Softmax with an efficient attention mechanism without considering the customized architectures specially for the efficient attention. In this paper, we argue that the handcrafted vanilla Transformer architectures for Softmax attention may not be suitable for efficient Transformers. To address this issue, we propose a new framework to find optimal architectures for efficient Transformers with the neural architecture search (NAS) technique. The proposed method is validated on popular machine translation and image classification tasks. We observe that the optimal architecture of the efficient Transformer has the reduced computation compared with that of the standard Transformer, but the general accuracy is less comparable. It indicates that the Softmax attention and efficient attention have their own distinctions but neither of them can simultaneously balance the accuracy and efficiency well. This motivates us to mix the two types of attention to reduce the performance imbalance. Besides the search spaces that commonly used in existing NAS Transformer approaches, we propose a new search space that allows the NAS algorithm to automatically search the attention variants along with architectures. Extensive experiments on WMT' 14 En-De and CIFAR-10 demonstrate that our searched architecture maintains comparable accuracy to the standard Transformer with notably improved computational efficiency.