 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLinearized Relative Positional Encoding
Jul 18, 2023Relative positional encoding is widely used in vanilla and linear transformers to represent positional information. However, existing encoding methods of a vanilla transformer are not always directly applicable to a linear transformer, because the latter requires a decomposition of the query and key representations into separate kernel functions. Nevertheless, principles for designing encoding methods suitable for linear transformers remain understudied. In this work, we put together a variety of existing linear relative positional encoding approaches under a canonical form and further propose a family of linear relative positional encoding algorithms via unitary transformation. Our formulation leads to a principled framework that can be used to develop new relative positional encoding methods that preserve linear space-time complexity. Equipped with different models, the proposed linearized relative positional encoding (LRPE) family derives effective encoding for various applications. Experiments show that compared with existing methods, LRPE achieves state-of-the-art performance in language modeling, text classification, and image classification. Meanwhile, it emphasizes a general paradigm for designing broadly more relative positional encoding methods that are applicable to linear transformers. The code is available at https://github.com/OpenNLPLab/Lrpe.
Linear Video Transformer with Feature Fixation
Oct 15, 2022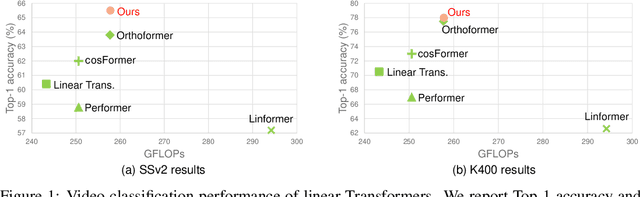
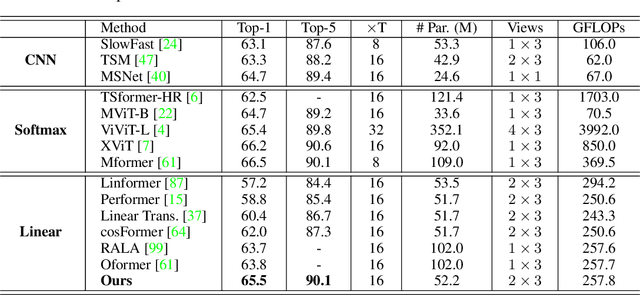

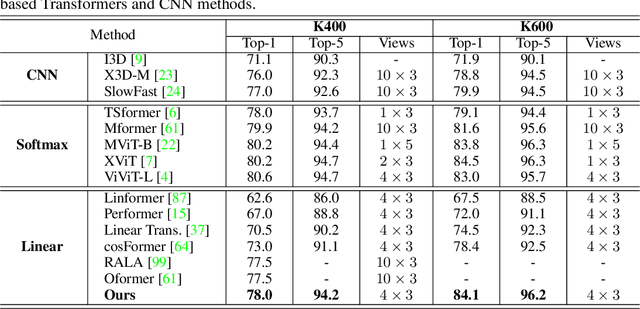
Vision Transformers have achieved impressive performance in video classification, while suffering from the quadratic complexity caused by the Softmax attention mechanism. Some studies alleviate the computational costs by reducing the number of tokens in attention calculation, but the complexity is still quadratic. Another promising way is to replace Softmax attention with linear attention, which owns linear complexity but presents a clear performance drop. We find that such a drop in linear attention results from the lack of attention concentration on critical features. Therefore, we propose a feature fixation module to reweight the feature importance of the query and key before computing linear attention. Specifically, we regard the query, key, and value as various latent representations of the input token, and learn the feature fixation ratio by aggregating Query-Key-Value information. This is beneficial for measuring the feature importance comprehensively. Furthermore, we enhance the feature fixation by neighborhood association, which leverages additional guidance from spatial and temporal neighbouring tokens. The proposed method significantly improves the linear attention baseline and achieves state-of-the-art performance among linear video Transformers on three popular video classification benchmarks. With fewer parameters and higher efficiency, our performance is even comparable to some Softmax-based quadratic Transformers.
Neural Architecture Search on Efficient Transformers and Beyond
Jul 28, 2022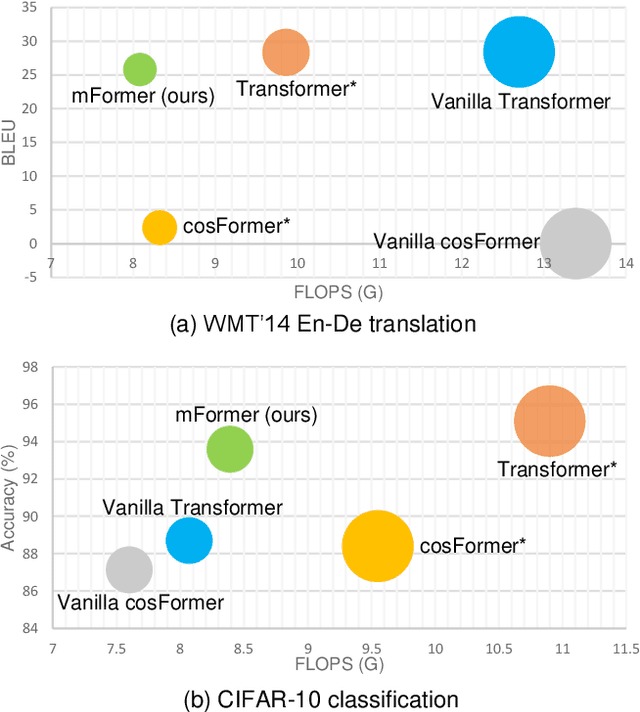
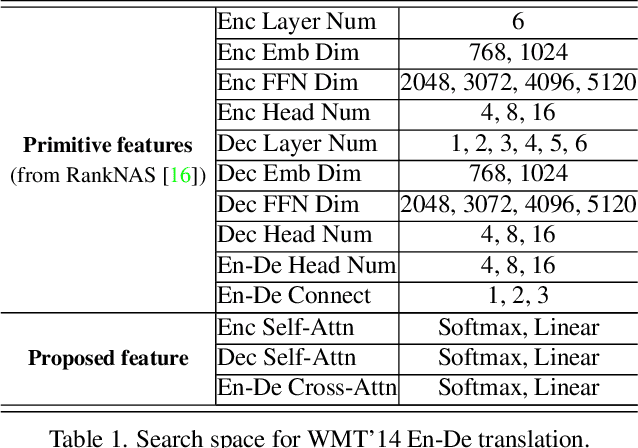


Recently, numerous efficient Transformers have been proposed to reduce the quadratic computational complexity of standard Transformers caused by the Softmax attention. However, most of them simply swap Softmax with an efficient attention mechanism without considering the customized architectures specially for the efficient attention. In this paper, we argue that the handcrafted vanilla Transformer architectures for Softmax attention may not be suitable for efficient Transformers. To address this issue, we propose a new framework to find optimal architectures for efficient Transformers with the neural architecture search (NAS) technique. The proposed method is validated on popular machine translation and image classification tasks. We observe that the optimal architecture of the efficient Transformer has the reduced computation compared with that of the standard Transformer, but the general accuracy is less comparable. It indicates that the Softmax attention and efficient attention have their own distinctions but neither of them can simultaneously balance the accuracy and efficiency well. This motivates us to mix the two types of attention to reduce the performance imbalance. Besides the search spaces that commonly used in existing NAS Transformer approaches, we propose a new search space that allows the NAS algorithm to automatically search the attention variants along with architectures. Extensive experiments on WMT' 14 En-De and CIFAR-10 demonstrate that our searched architecture maintains comparable accuracy to the standard Transformer with notably improved computational efficiency.
Deep Texture and Structure Aware Filtering Network for Image Smoothing
May 08, 2018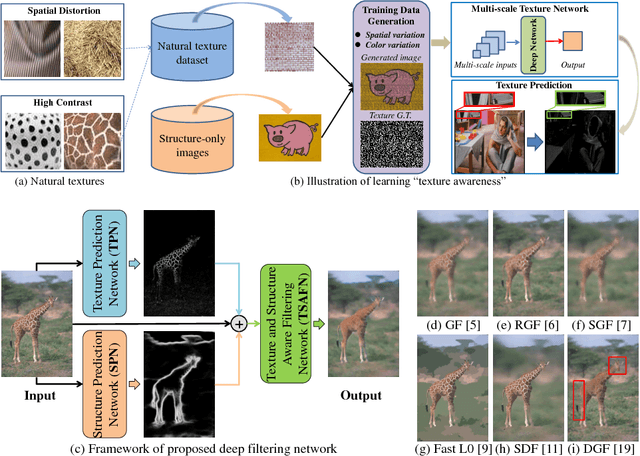
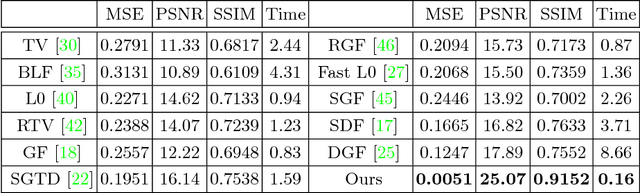
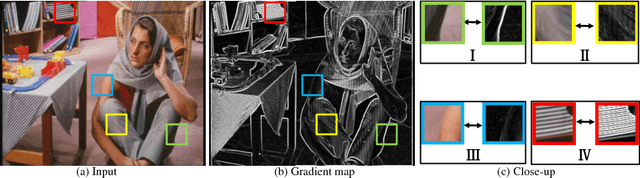

Image smoothing is a fundamental task in computer vision, that aims to retain salient structures and remove insignificant textures. In this paper, we aim to address the fundamental shortcomings of existing image smoothing methods, which cannot properly distinguish textures and structures with similar low-level appearance. While deep learning approaches have started to explore the preservation of structure through image smoothing, existing work does not yet properly address textures. To this end, we generate a large dataset by blending natural textures with clean structure-only images, and then build a texture prediction network (TPN) that predicts the location and magnitude of textures. We then combine the TPN with a semantic structure prediction network (SPN) so that the final texture and structure aware filtering network (TSAFN) is able to identify the textures to remove ("texture-awareness") and the structures to preserve ("structure-awareness"). The proposed model is easy to understand and implement, and shows excellent performance on real images in the wild as well as our generated dataset.