 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Architecture Search on Efficient Transformers and Beyond
Paper and Code
Jul 28, 2022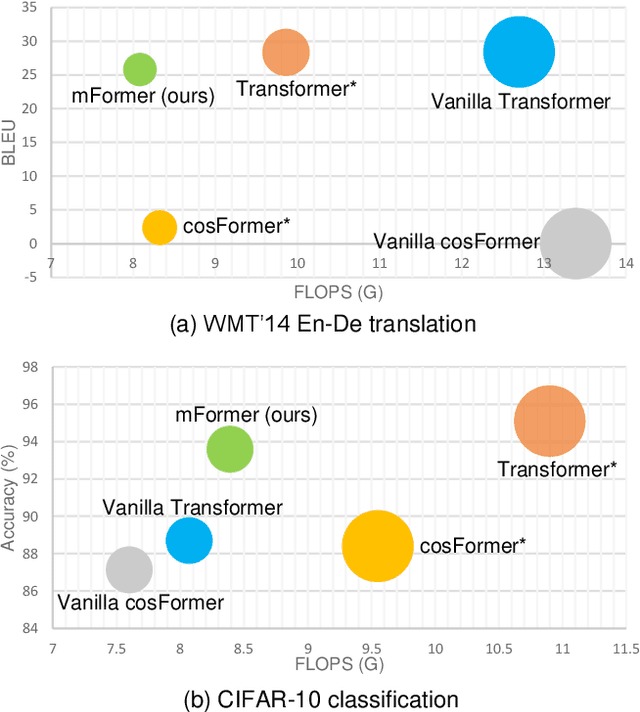
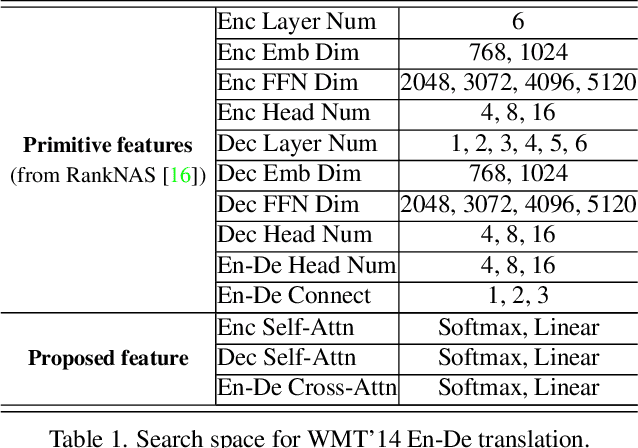


Recently, numerous efficient Transformers have been proposed to reduce the quadratic computational complexity of standard Transformers caused by the Softmax attention. However, most of them simply swap Softmax with an efficient attention mechanism without considering the customized architectures specially for the efficient attention. In this paper, we argue that the handcrafted vanilla Transformer architectures for Softmax attention may not be suitable for efficient Transformers. To address this issue, we propose a new framework to find optimal architectures for efficient Transformers with the neural architecture search (NAS) technique. The proposed method is validated on popular machine translation and image classification tasks. We observe that the optimal architecture of the efficient Transformer has the reduced computation compared with that of the standard Transformer, but the general accuracy is less comparable. It indicates that the Softmax attention and efficient attention have their own distinctions but neither of them can simultaneously balance the accuracy and efficiency well. This motivates us to mix the two types of attention to reduce the performance imbalance. Besides the search spaces that commonly used in existing NAS Transformer approaches, we propose a new search space that allows the NAS algorithm to automatically search the attention variants along with architectures. Extensive experiments on WMT' 14 En-De and CIFAR-10 demonstrate that our searched architecture maintains comparable accuracy to the standard Transformer with notably improved computational efficiency.