 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepSeek-V3 Technical Report
Dec 27, 2024



We present DeepSeek-V3, a strong Mixture-of-Experts (MoE) language model with 671B total parameters with 37B activated for each token. To achieve efficient inference and cost-effective training, DeepSeek-V3 adopts Multi-head Latent Attention (MLA) and DeepSeekMoE architectures, which were thoroughly validated in DeepSeek-V2. Furthermore, DeepSeek-V3 pioneers an auxiliary-loss-free strategy for load balancing and sets a multi-token prediction training objective for stronger performance. We pre-train DeepSeek-V3 on 14.8 trillion diverse and high-quality tokens, followed by Supervised Fine-Tuning and Reinforcement Learning stages to fully harness its capabilities. Comprehensive evaluations reveal that DeepSeek-V3 outperforms other open-source models and achieves performance comparable to leading closed-source models. Despite its excellent performance, DeepSeek-V3 requires only 2.788M H800 GPU hours for its full training. In addition, its training process is remarkably stable. Throughout the entire training process, we did not experience any irrecoverable loss spikes or perform any rollbacks. The model checkpoints are available at https://github.com/deepseek-ai/DeepSeek-V3.
Fire-Flyer AI-HPC: A Cost-Effective Software-Hardware Co-Design for Deep Learning
Aug 26, 2024



The rapid progress in Deep Learning (DL) and Large Language Models (LLMs) has exponentially increased demands of computational power and bandwidth. This, combined with the high costs of faster computing chips and interconnects, has significantly inflated High Performance Computing (HPC) construction costs. To address these challenges, we introduce the Fire-Flyer AI-HPC architecture, a synergistic hardware-software co-design framework and its best practices. For DL training, we deployed the Fire-Flyer 2 with 10,000 PCIe A100 GPUs, achieved performance approximating the DGX-A100 while reducing costs by half and energy consumption by 40%. We specifically engineered HFReduce to accelerate allreduce communication and implemented numerous measures to keep our Computation-Storage Integrated Network congestion-free. Through our software stack, including HaiScale, 3FS, and HAI-Platform, we achieved substantial scalability by overlapping computation and communication. Our system-oriented experience from DL training provides valuable insights to drive future advancements in AI-HPC.
DeepSeek LLM: Scaling Open-Source Language Models with Longtermism
Jan 05, 2024



The rapid development of open-source large language models (LLMs) has been truly remarkable. However, the scaling law described in previous literature presents varying conclusions, which casts a dark cloud over scaling LLMs. We delve into the study of scaling laws and present our distinctive findings that facilitate scaling of large scale models in two commonly used open-source configurations, 7B and 67B. Guided by the scaling laws, we introduce DeepSeek LLM, a project dedicated to advancing open-source language models with a long-term perspective. To support the pre-training phase, we have developed a dataset that currently consists of 2 trillion tokens and is continuously expanding. We further conduct supervised fine-tuning (SFT) and Direct Preference Optimization (DPO) on DeepSeek LLM Base models, resulting in the creation of DeepSeek Chat models. Our evaluation results demonstrate that DeepSeek LLM 67B surpasses LLaMA-2 70B on various benchmarks, particularly in the domains of code, mathematics, and reasoning. Furthermore, open-ended evaluations reveal that DeepSeek LLM 67B Chat exhibits superior performance compared to GPT-3.5.
LAW: Learning to Auto Weight
May 27, 2019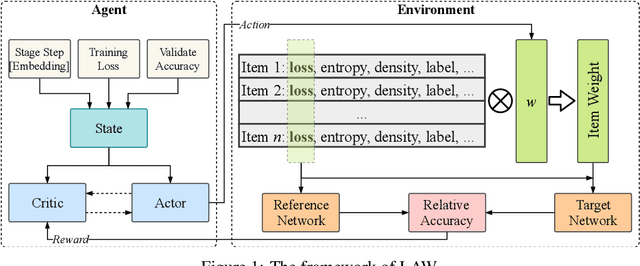

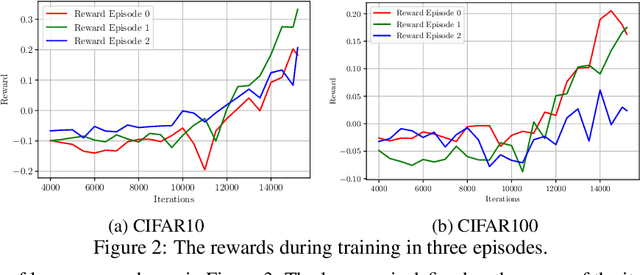
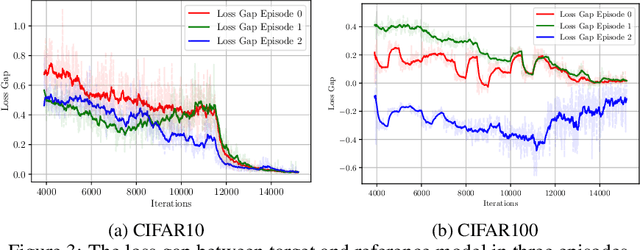
Example weighting algorithm is an effective solution to the training bias problem. However, typical methods are usually limited to human knowledge and require laborious tuning of hyperparameters. In this study, we propose a novel example weighting framework called Learning to Auto Weight (LAW), which can learn weighting policy from data adaptively based on reinforcement learning (RL). To shrink the huge searching space in a complete training process, we divide the training procedure consisting of numerous iterations into a small number of stages, and then search a low-deformational continuous vector as action, which determines the weight of each sample. To make training more efficient, we make an innovative design of the reward to remove randomness during the RL process. Experimental results demonstrate the superiority of weighting policy explored by LAW over standard training pipeline. Especially, compared with baselines, LAW can find a better weighting schedule which achieves higher accuracy in the origin CIFAR dataset, and over 10% higher in accuracy on the contaminated CIFAR dataset with 30% label noises. Our code will be released soon.
Dynamic Multi-path Neural Network
Apr 07, 2019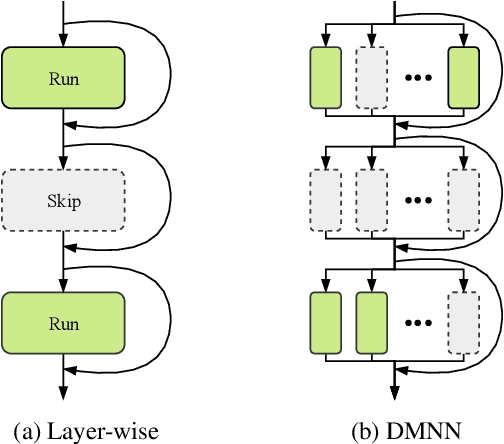
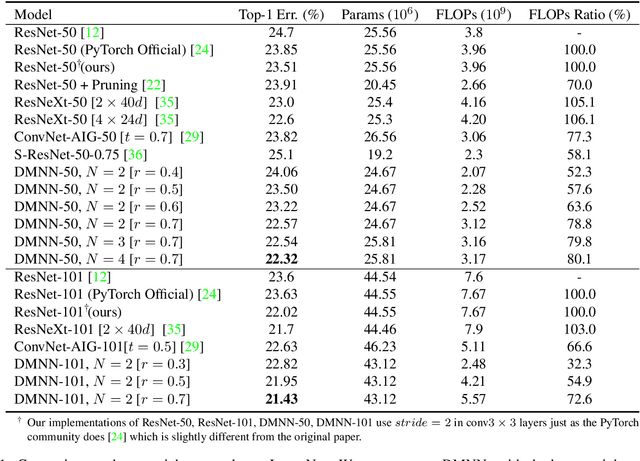
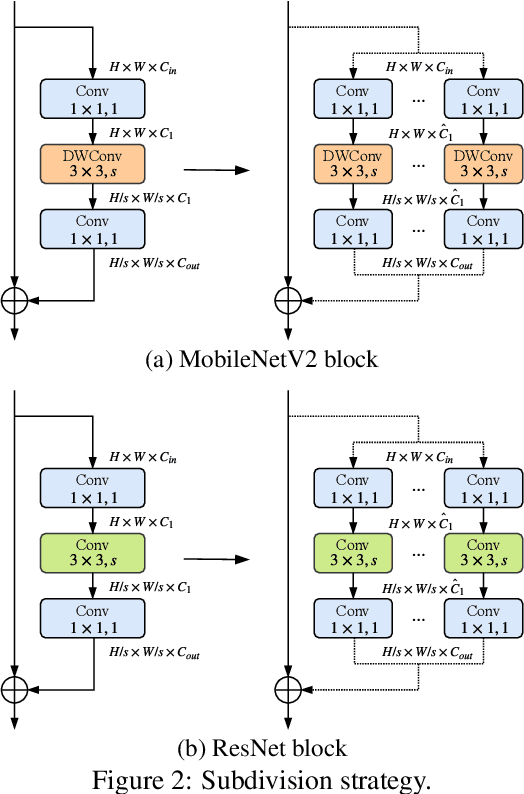
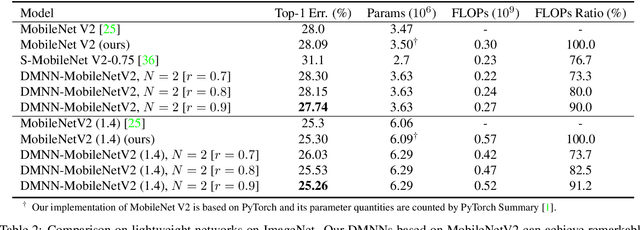
Although deeper and larger neural networks have achieved better performance, the complex network structure and increasing computational cost cannot meet the demands of many resource-constrained applications. Existing methods usually choose to execute or skip an entire specific layer, which can only alter the depth of the network. In this paper, we propose a novel method called Dynamic Multi-path Neural Network (DMNN), which provides more path selection choices in terms of network width and depth during inference. The inference path of the network is determined by a controller, which takes into account both previous state and object category information. The proposed method can be easily incorporated into most modern network architectures. Experimental results on ImageNet and CIFAR-100 demonstrate the superiority of our method on both efficiency and overall classification accuracy. To be specific, DMNN-101 significantly outperforms ResNet-101 with an encouraging 45.1% FLOPs reduction, and DMNN-50 performs comparably to ResNet-101 while saving 42.1% parameters.
Correlation Congruence for Knowledge Distillation
Apr 03, 2019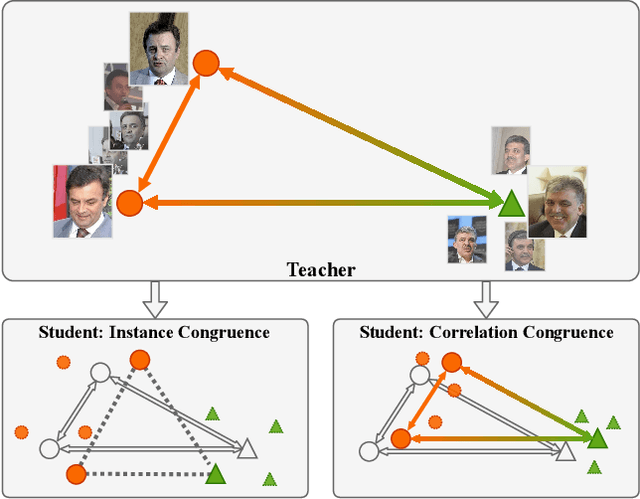
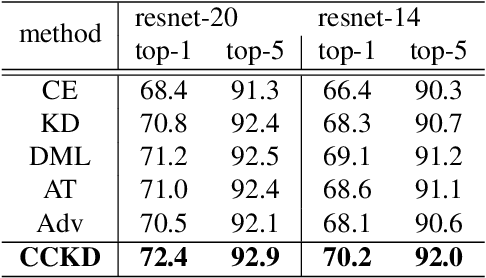
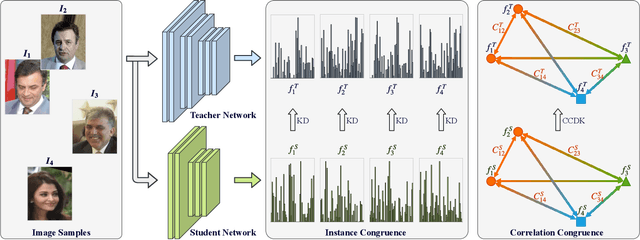
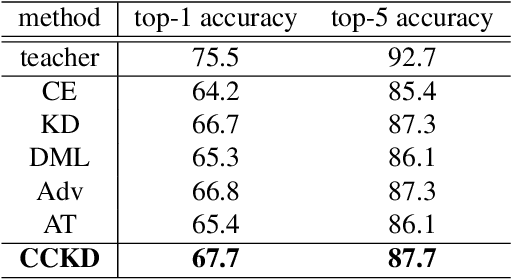
Most teacher-student frameworks based on knowledge distillation (KD) depend on a strong congruent constraint on instance level. However, they usually ignore the correlation between multiple instances, which is also valuable for knowledge transfer. In this work, we propose a new framework named correlation congruence for knowledge distillation (CCKD), which transfers not only the instance-level information, but also the correlation between instances. Furthermore, a generalized kernel method based on Taylor series expansion is proposed to better capture the correlation between instances. Empirical experiments and ablation studies on image classification tasks (including CIFAR-100, ImageNet-1K) and metric learning tasks (including ReID and Face Recognition) show that the proposed CCKD substantially outperforms the original KD and achieves state-of-the-art accuracy compared with other SOTA KD-based methods. The CCKD can be easily deployed in the majority of the teacher-student framework such as KD and hint-based learning methods.