 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInter-class Discrepancy Alignment for Face Recognition
Mar 02, 2021The field of face recognition (FR) has witnessed great progress with the surge of deep learning. Existing methods mainly focus on extracting discriminative features, and directly compute the cosine or L2 distance by the point-to-point way without considering the context information. In this study, we make a key observation that the local con-text represented by the similarities between the instance and its inter-class neighbors1plays an important role forFR. Specifically, we attempt to incorporate the local in-formation in the feature space into the metric, and pro-pose a unified framework calledInter-class DiscrepancyAlignment(IDA), with two dedicated modules, Discrepancy Alignment Operator(IDA-DAO) andSupport Set Estimation(IDA-SSE). IDA-DAO is used to align the similarity scores considering the discrepancy between the images and its neighbors, which is defined by adaptive support sets on the hypersphere. For practical inference, it is difficult to acquire support set during online inference. IDA-SSE can provide convincing inter-class neighbors by introducing virtual candidate images generated with GAN. Further-more, we propose the learnable IDA-SSE, which can implicitly give estimation without the need of any other images in the evaluation process. The proposed IDA can be incorporated into existing FR systems seamlessly and efficiently. Extensive experiments demonstrate that this frame-work can 1) significantly improve the accuracy, and 2) make the model robust to the face images of various distributions.Without bells and whistles, our method achieves state-of-the-art performance on multiple standard FR benchmarks.
LAW: Learning to Auto Weight
May 27, 2019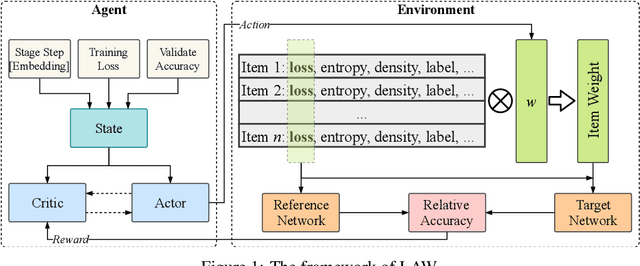

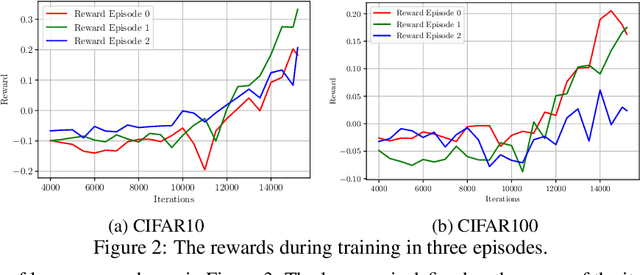
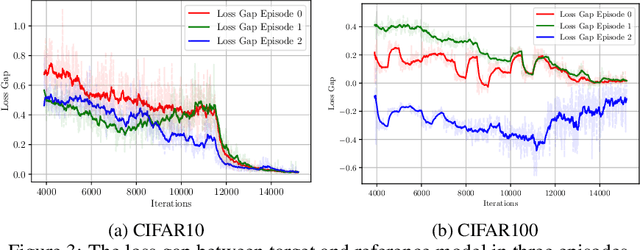
Example weighting algorithm is an effective solution to the training bias problem. However, typical methods are usually limited to human knowledge and require laborious tuning of hyperparameters. In this study, we propose a novel example weighting framework called Learning to Auto Weight (LAW), which can learn weighting policy from data adaptively based on reinforcement learning (RL). To shrink the huge searching space in a complete training process, we divide the training procedure consisting of numerous iterations into a small number of stages, and then search a low-deformational continuous vector as action, which determines the weight of each sample. To make training more efficient, we make an innovative design of the reward to remove randomness during the RL process. Experimental results demonstrate the superiority of weighting policy explored by LAW over standard training pipeline. Especially, compared with baselines, LAW can find a better weighting schedule which achieves higher accuracy in the origin CIFAR dataset, and over 10% higher in accuracy on the contaminated CIFAR dataset with 30% label noises. Our code will be released soon.