 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStacking Factorizing Partitioned Expressions in Hybrid Bayesian Network Models
Feb 23, 2024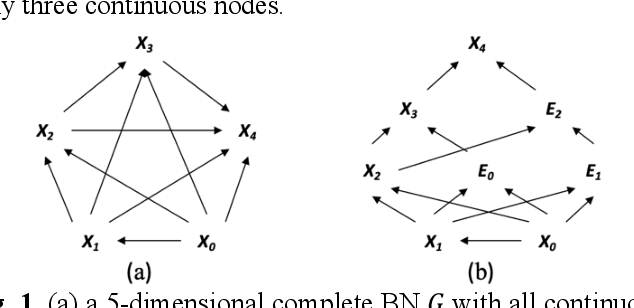
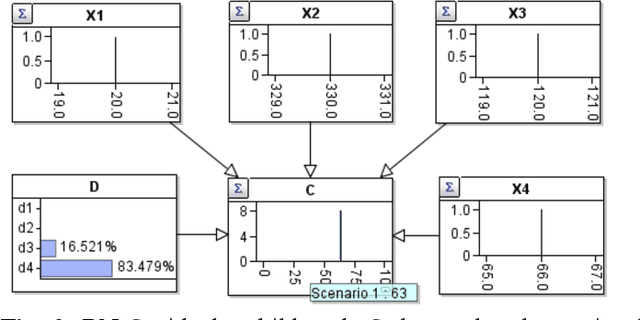
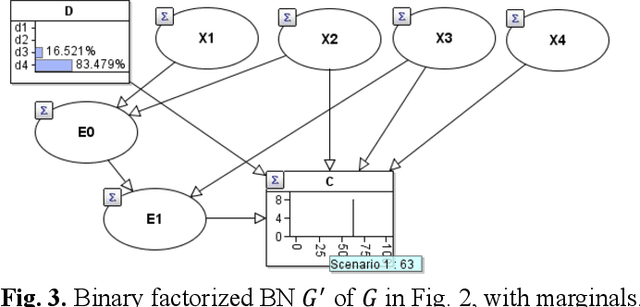
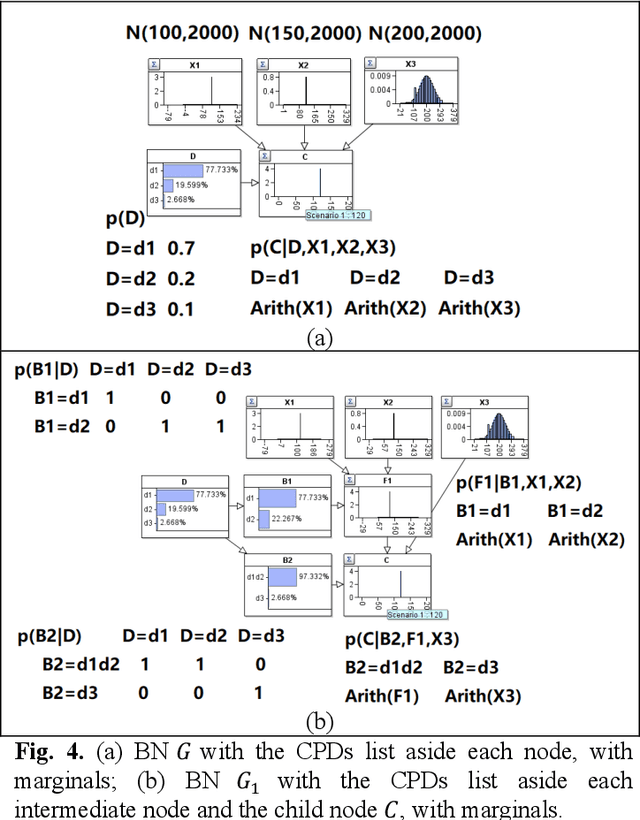
Hybrid Bayesian networks (HBN) contain complex conditional probabilistic distributions (CPD) specified as partitioned expressions over discrete and continuous variables. The size of these CPDs grows exponentially with the number of parent nodes when using discrete inference, resulting in significant inefficiency. Normally, an effective way to reduce the CPD size is to use a binary factorization (BF) algorithm to decompose the statistical or arithmetic functions in the CPD by factorizing the number of connected parent nodes to sets of size two. However, the BF algorithm was not designed to handle partitioned expressions. Hence, we propose a new algorithm called stacking factorization (SF) to decompose the partitioned expressions. The SF algorithm creates intermediate nodes to incrementally reconstruct the densities in the original partitioned expression, allowing no more than two continuous parent nodes to be connected to each child node in the resulting HBN. SF can be either used independently or combined with the BF algorithm. We show that the SF+BF algorithm significantly reduces the CPD size and contributes to lowering the tree-width of a model, thus improving efficiency.
A hybrid Bayesian network for medical device risk assessment and management
Sep 07, 2022



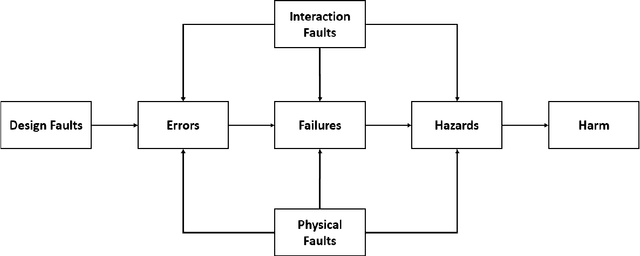
ISO 14971 is the primary standard used for medical device risk management. While it specifies the requirements for medical device risk management, it does not specify a particular method for performing risk management. Hence, medical device manufacturers are free to develop or use any appropriate methods for managing the risk of medical devices. The most commonly used methods, such as Fault Tree Analysis (FTA), are unable to provide a reasonable basis for computing risk estimates when there are limited or no historical data available or where there is second-order uncertainty about the data. In this paper, we present a novel method for medical device risk management using hybrid Bayesian networks (BNs) that resolves the limitations of classical methods such as FTA and incorporates relevant factors affecting the risk of medical devices. The proposed BN method is generic but can be instantiated on a system-by-system basis, and we apply it to a Defibrillator device to demonstrate the process involved for medical device risk management during production and post-production. The example is validated against real-world data.
Product safety idioms: a method for building causal Bayesian networks for product safety and risk assessment
Jun 05, 2022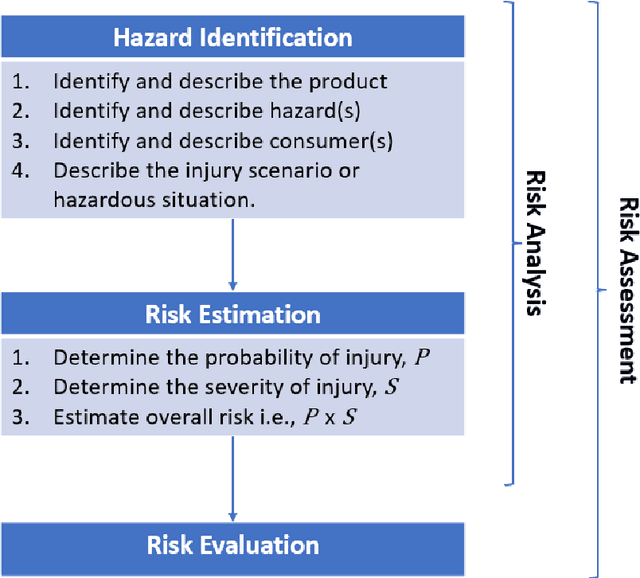
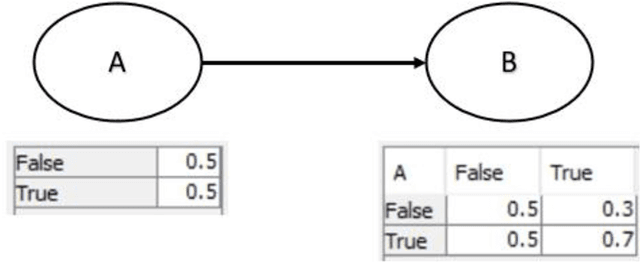
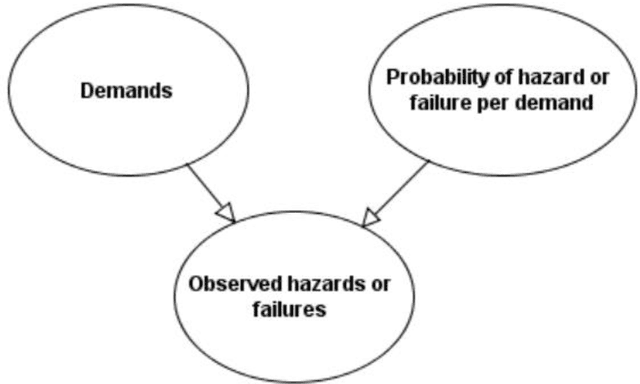
Idioms are small, reusable Bayesian network (BN) fragments that represent generic types of uncertain reasoning. This paper shows how idioms can be used to build causal BNs for product safety and risk assessment that use a combination of data and knowledge. We show that the specific product safety idioms that we introduce are sufficient to build full BN models to evaluate safety and risk for a wide range of products. The resulting models can be used by safety regulators and product manufacturers even when there are limited (or no) product testing data.
Smart Automotive Technology Adherence to the Law: (De)Constructing Road Rules for Autonomous System Development, Verification and Safety
Sep 10, 2021
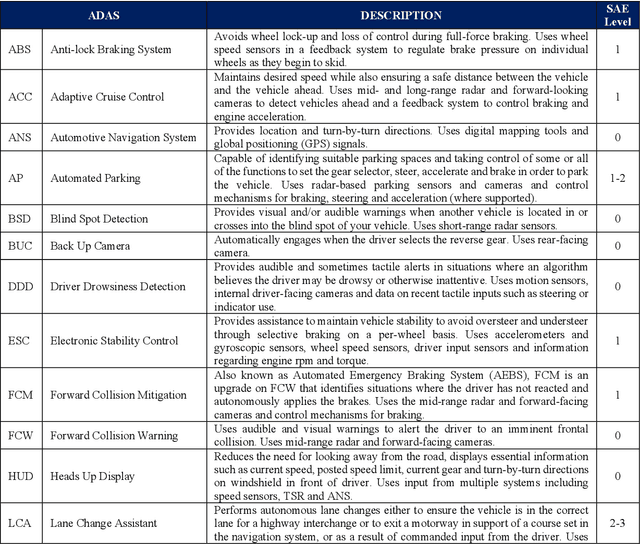


Driving is an intuitive task that requires skills, constant alertness and vigilance for unexpected events. The driving task also requires long concentration spans focusing on the entire task for prolonged periods, and sophisticated negotiation skills with other road users, including wild animals. These requirements are particularly important when approaching intersections, overtaking, giving way, merging, turning and while adhering to the vast body of road rules. Modern motor vehicles now include an array of smart assistive and autonomous driving systems capable of subsuming some, most, or in limited cases, all of the driving task. The UK Department of Transport's response to the Safe Use of Automated Lane Keeping System consultation proposes that these systems are tested for compliance with relevant traffic rules. Building these smart automotive systems requires software developers with highly technical software engineering skills, and now a lawyer's in-depth knowledge of traffic legislation as well. These skills are required to ensure the systems are able to safely perform their tasks while being observant of the law. This paper presents an approach for deconstructing the complicated legalese of traffic law and representing its requirements and flow. The approach (de)constructs road rules in legal terminology and specifies them in structured English logic that is expressed as Boolean logic for automation and Lawmaps for visualisation. We demonstrate an example using these tools leading to the construction and validation of a Bayesian Network model. We strongly believe these tools to be approachable by programmers and the general public, and capable of use in developing Artificial Intelligence to underpin motor vehicle smart systems, and in validation to ensure these systems are considerate of the law when making decisions.
How do some Bayesian Network machine learned graphs compare to causal knowledge?
Feb 02, 2021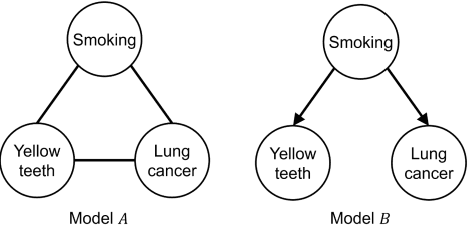



The graph of a Bayesian Network (BN) can be machine learned, determined by causal knowledge, or a combination of both. In disciplines like bioinformatics, applying BN structure learning algorithms can reveal new insights that would otherwise remain unknown. However, these algorithms are less effective when the input data are limited in terms of sample size, which is often the case when working with real data. This paper focuses on purely machine learned and purely knowledge-based BNs and investigates their differences in terms of graphical structure and how well the implied statistical models explain the data. The tests are based on four previous case studies whose BN structure was determined by domain knowledge. Using various metrics, we compare the knowledge-based graphs to the machine learned graphs generated from various algorithms implemented in TETRAD spanning all three classes of learning. The results show that, while the algorithms produce graphs with much higher model selection score, the knowledge-based graphs are more accurate predictors of variables of interest. Maximising score fitting is ineffective in the presence of limited sample size because the fitting becomes increasingly distorted with limited data, guiding algorithms towards graphical patterns that share higher fitting scores and yet deviate considerably from the true graph. This highlights the value of causal knowledge in these cases, as well as the need for more appropriate fitting scores suitable for limited data. Lastly, the experiments also provide new evidence that support the notion that results from simulated data tell us little about actual real-world performance.
Product risk assessment: a Bayesian network approach
Oct 09, 2020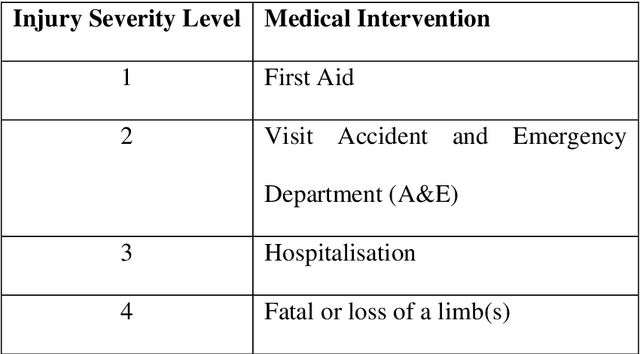
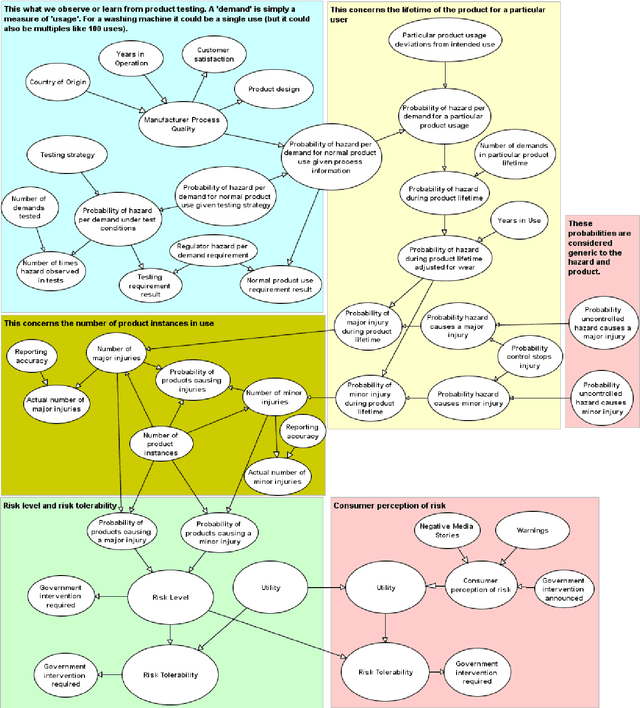
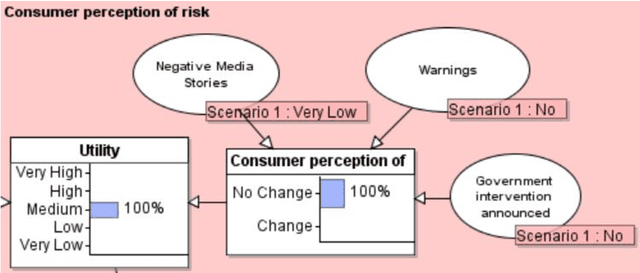
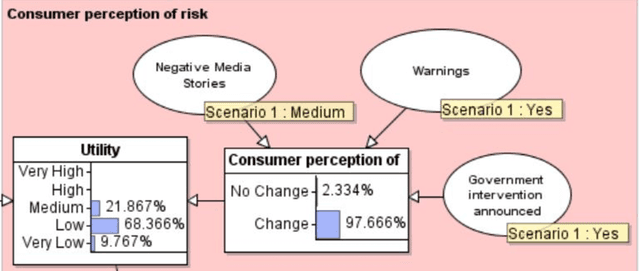
Product risk assessment is the overall process of determining whether a product, which could be anything from a type of washing machine to a type of teddy bear, is judged safe for consumers to use. There are several methods used for product risk assessment, including RAPEX, which is the primary method used by regulators in the UK and EU. However, despite its widespread use, we identify several limitations of RAPEX including a limited approach to handling uncertainty and the inability to incorporate causal explanations for using and interpreting test data. In contrast, Bayesian Networks (BNs) are a rigorous, normative method for modelling uncertainty and causality which are already used for risk assessment in domains such as medicine and finance, as well as critical systems generally. This article proposes a BN model that provides an improved systematic method for product risk assessment that resolves the identified limitations with RAPEX. We use our proposed method to demonstrate risk assessments for a teddy bear and a new uncertified kettle for which there is no testing data and the number of product instances is unknown. We show that, while we can replicate the results of the RAPEX method, the BN approach is more powerful and flexible.
The role of collider bias in understanding statistics on racially biased policing
Jul 16, 2020
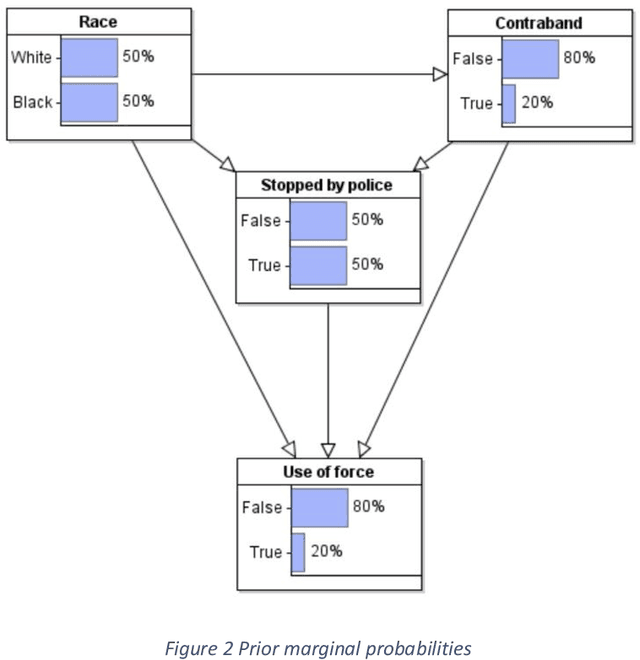
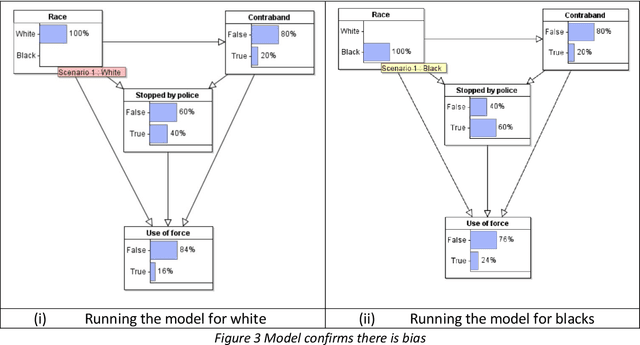
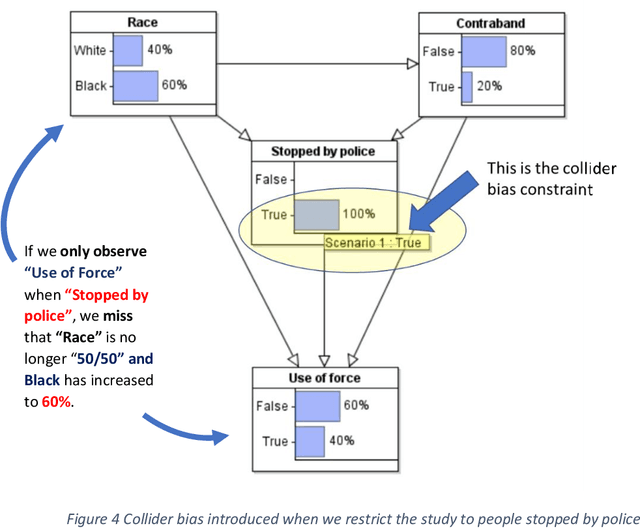
Contradictory conclusions have been made about whether unarmed blacks are more likely to be shot by police than unarmed whites using the same data. The problem is that, by relying only on data of 'police encounters', there is the possibility that genuine bias can be hidden. We provide a causal Bayesian network model to explain this bias, which is called collider bias or Berkson's paradox, and show how the different conclusions arise from the same model and data. We also show that causal Bayesian networks provide the ideal formalism for considering alternative hypotheses and explanations of bias.
Medical idioms for clinical Bayesian network development
Jul 02, 2020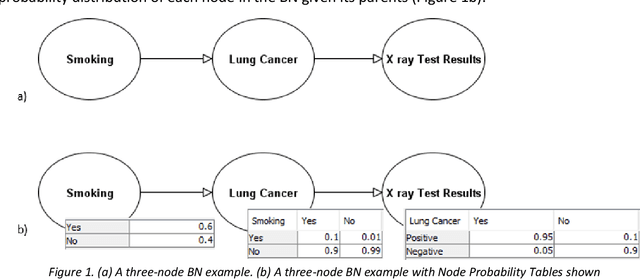
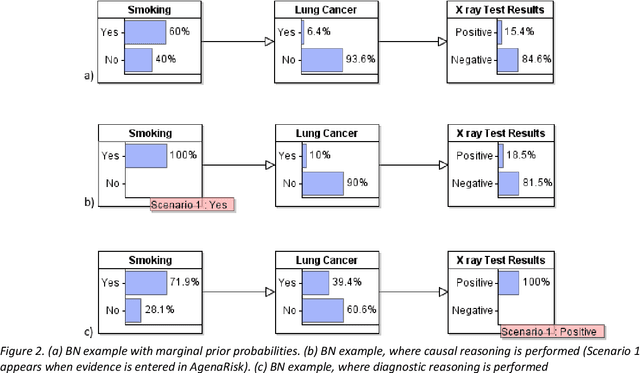
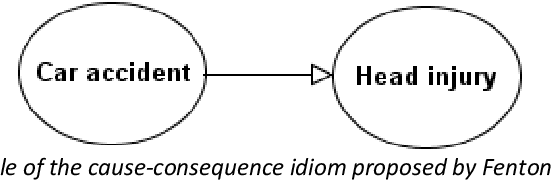
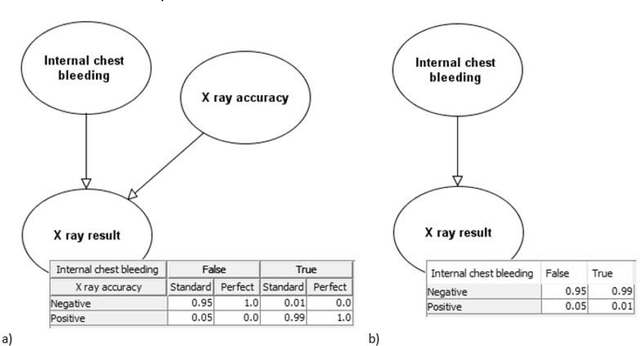
Bayesian Networks (BNs) are graphical probabilistic models that have proven popular in medical applications. While numerous medical BNs have been published, most are presented fait accompli without explanation of how the network structure was developed or justification of why it represents the correct structure for the given medical application. This means that the process of building medical BNs from experts is typically ad hoc and offers little opportunity for methodological improvement. This paper proposes generally applicable and reusable medical reasoning patterns to aid those developing medical BNs. The proposed method complements and extends the idiom-based approach introduced by Neil, Fenton, and Nielsen in 2000. We propose instances of their generic idioms that are specific to medical BNs. We refer to the proposed medical reasoning patterns as medical idioms. In addition, we extend the use of idioms to represent interventional and counterfactual reasoning. We believe that the proposed medical idioms are logical reasoning patterns that can be combined, reused and applied generically to help develop medical BNs. All proposed medical idioms have been illustrated using medical examples on coronary artery disease. The method has also been applied to other ongoing BNs being developed with medical experts. Finally, we show that applying the proposed medical idioms to published BN models results in models with a clearer structure.
Simpson's Paradox and the implications for medical trials
Dec 03, 2019
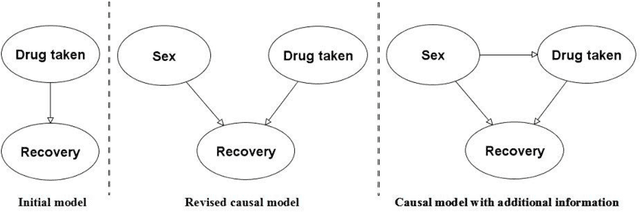

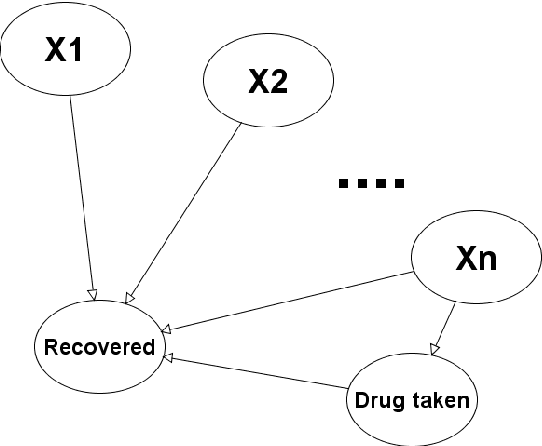
This paper describes Simpson's paradox, and explains its serious implications for randomised control trials. In particular, we show that for any number of variables we can simulate the result of a controlled trial which uniformly points to one conclusion (such as 'drug is effective') for every possible combination of the variable states, but when a previously unobserved confounding variable is included every possible combination of the variables state points to the opposite conclusion ('drug is not effective'). In other words no matter how many variables are considered, and no matter how 'conclusive' the result, one cannot conclude the result is truly 'valid' since there is theoretically an unobserved confounding variable that could completely reverse the result.
Region Based Approximation for High Dimensional Bayesian Network Models
Feb 05, 2016Performing efficient inference on Bayesian Networks (BNs), with large numbers of densely connected variables is challenging. With exact inference methods, such as the Junction Tree algorithm, clustering complexity can grow exponentially with the number of nodes and so computation becomes intractable. This paper presents a general purpose approximate inference algorithm called Triplet Region Construction (TRC) that reduces the clustering complexity for factorized models from worst case exponential to polynomial. We employ graph factorization to reduce connection complexity and produce clusters of limited size. Unlike MCMC algorithms TRC is guaranteed to converge and we present experiments that show that TRC achieves accurate results when compared with exact solutions.