 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTAIL: Text-Audio Incremental Learning
Mar 06, 2025



Many studies combine text and audio to capture multi-modal information but they overlook the model's generalization ability on new datasets. Introducing new datasets may affect the feature space of the original dataset, leading to catastrophic forgetting. Meanwhile, large model parameters can significantly impact training performance. To address these limitations, we introduce a novel task called Text-Audio Incremental Learning (TAIL) task for text-audio retrieval, and propose a new method, PTAT, Prompt Tuning for Audio-Text incremental learning. This method utilizes prompt tuning to optimize the model parameters while incorporating an audio-text similarity and feature distillation module to effectively mitigate catastrophic forgetting. We benchmark our method and previous incremental learning methods on AudioCaps, Clotho, BBC Sound Effects and Audioset datasets, and our method outperforms previous methods significantly, particularly demonstrating stronger resistance to forgetting on older datasets. Compared to the full-parameters Finetune (Sequential) method, our model only requires 2.42\% of its parameters, achieving 4.46\% higher performance.
SA3DIP: Segment Any 3D Instance with Potential 3D Priors
Nov 06, 2024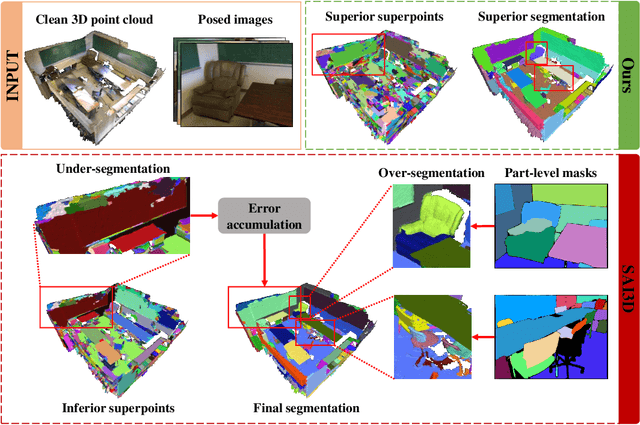

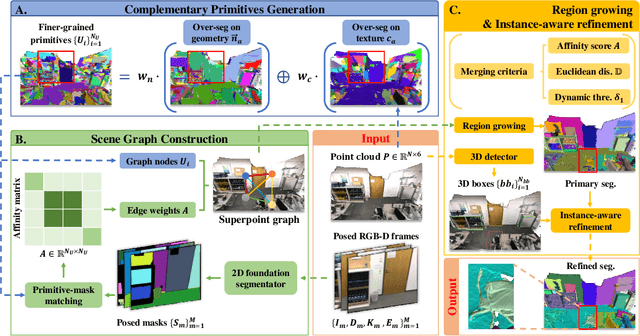

The proliferation of 2D foundation models has sparked research into adapting them for open-world 3D instance segmentation. Recent methods introduce a paradigm that leverages superpoints as geometric primitives and incorporates 2D multi-view masks from Segment Anything model (SAM) as merging guidance, achieving outstanding zero-shot instance segmentation results. However, the limited use of 3D priors restricts the segmentation performance. Previous methods calculate the 3D superpoints solely based on estimated normal from spatial coordinates, resulting in under-segmentation for instances with similar geometry. Besides, the heavy reliance on SAM and hand-crafted algorithms in 2D space suffers from over-segmentation due to SAM's inherent part-level segmentation tendency. To address these issues, we propose SA3DIP, a novel method for Segmenting Any 3D Instances via exploiting potential 3D Priors. Specifically, on one hand, we generate complementary 3D primitives based on both geometric and textural priors, which reduces the initial errors that accumulate in subsequent procedures. On the other hand, we introduce supplemental constraints from the 3D space by using a 3D detector to guide a further merging process. Furthermore, we notice a considerable portion of low-quality ground truth annotations in ScanNetV2 benchmark, which affect the fair evaluations. Thus, we present ScanNetV2-INS with complete ground truth labels and supplement additional instances for 3D class-agnostic instance segmentation. Experimental evaluations on various 2D-3D datasets demonstrate the effectiveness and robustness of our approach. Our code and proposed ScanNetV2-INS dataset are available HERE.
Translating Text Synopses to Video Storyboards
Dec 31, 2022

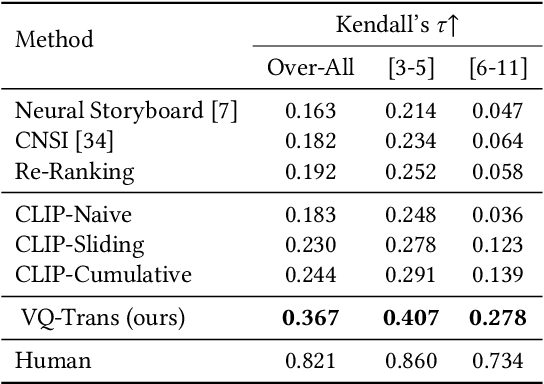

A storyboard is a roadmap for video creation which consists of shot-by-shot images to visualize key plots in a text synopsis. Creating video storyboards however remains challenging which not only requires association between high-level texts and images, but also demands for long-term reasoning to make transitions smooth across shots. In this paper, we propose a new task called Text synopsis to Video Storyboard (TeViS) which aims to retrieve an ordered sequence of images to visualize the text synopsis. We construct a MovieNet-TeViS benchmark based on the public MovieNet dataset. It contains 10K text synopses each paired with keyframes that are manually selected from corresponding movies by considering both relevance and cinematic coherence. We also present an encoder-decoder baseline for the task. The model uses a pretrained vision-and-language model to improve high-level text-image matching. To improve coherence in long-term shots, we further propose to pre-train the decoder on large-scale movie frames without text. Experimental results demonstrate that our proposed model significantly outperforms other models to create text-relevant and coherent storyboards. Nevertheless, there is still a large gap compared to human performance suggesting room for promising future work.