 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrompt-Enhanced Spatio-Temporal Graph Transfer Learning
May 21, 2024Spatio-temporal graph neural networks have demonstrated efficacy in capturing complex dependencies for urban computing tasks such as forecasting and kriging. However, their performance is constrained by the reliance on extensive data for training on specific tasks, which limits their adaptability to new urban domains with varied demands. Although transfer learning has been proposed to address this problem by leveraging knowledge across domains, cross-task generalization remains underexplored in spatio-temporal graph transfer learning methods due to the absence of a unified framework. To bridge this gap, we propose Spatio-Temporal Graph Prompting (STGP), a prompt-enhanced transfer learning framework capable of adapting to diverse tasks in data-scarce domains. Specifically, we first unify different tasks into a single template and introduce a task-agnostic network architecture that aligns with this template. This approach enables the capture of spatio-temporal dependencies shared across tasks. Furthermore, we employ learnable prompts to achieve domain and task transfer in a two-stage prompting pipeline, enabling the prompts to effectively capture domain knowledge and task-specific properties at each stage. Extensive experiments demonstrate that STGP outperforms state-of-the-art baselines in three downstream tasks forecasting, kriging, and extrapolation by a notable margin.
Towards Unifying Diffusion Models for Probabilistic Spatio-Temporal Graph Learning
Oct 26, 2023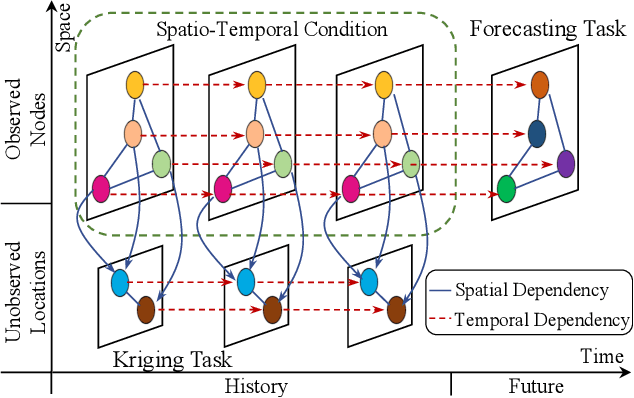



Spatio-temporal graph learning is a fundamental problem in the Web of Things era, which enables a plethora of Web applications such as smart cities, human mobility and climate analysis. Existing approaches tackle different learning tasks independently, tailoring their models to unique task characteristics. These methods, however, fall short of modeling intrinsic uncertainties in the spatio-temporal data. Meanwhile, their specialized designs limit their universality as general spatio-temporal learning solutions. In this paper, we propose to model the learning tasks in a unified perspective, viewing them as predictions based on conditional information with shared spatio-temporal patterns. Based on this proposal, we introduce Unified Spatio-Temporal Diffusion Models (USTD) to address the tasks uniformly within the uncertainty-aware diffusion framework. USTD is holistically designed, comprising a shared spatio-temporal encoder and attention-based denoising networks that are task-specific. The shared encoder, optimized by a pre-training strategy, effectively captures conditional spatio-temporal patterns. The denoising networks, utilizing both cross- and self-attention, integrate conditional dependencies and generate predictions. Opting for forecasting and kriging as downstream tasks, we design Gated Attention (SGA) and Temporal Gated Attention (TGA) for each task, with different emphases on the spatial and temporal dimensions, respectively. By combining the advantages of deterministic encoders and probabilistic diffusion models, USTD achieves state-of-the-art performances compared to deterministic and probabilistic baselines in both tasks, while also providing valuable uncertainty estimates.
Graph Neural Processes for Spatio-Temporal Extrapolation
May 30, 2023

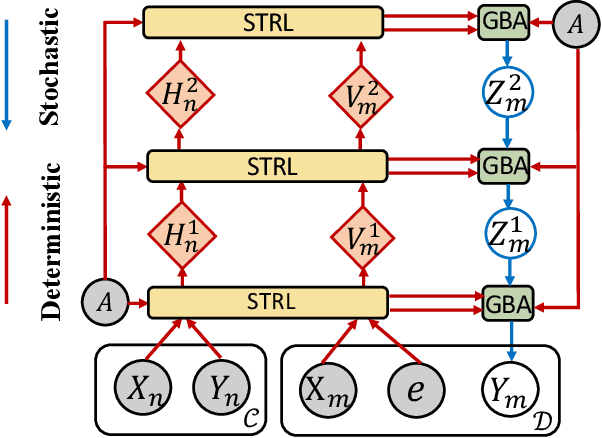

We study the task of spatio-temporal extrapolation that generates data at target locations from surrounding contexts in a graph. This task is crucial as sensors that collect data are sparsely deployed, resulting in a lack of fine-grained information due to high deployment and maintenance costs. Existing methods either use learning-based models like Neural Networks or statistical approaches like Gaussian Processes for this task. However, the former lacks uncertainty estimates and the latter fails to capture complex spatial and temporal correlations effectively. To address these issues, we propose Spatio-Temporal Graph Neural Processes (STGNP), a neural latent variable model which commands these capabilities simultaneously. Specifically, we first learn deterministic spatio-temporal representations by stacking layers of causal convolutions and cross-set graph neural networks. Then, we learn latent variables for target locations through vertical latent state transitions along layers and obtain extrapolations. Importantly during the transitions, we propose Graph Bayesian Aggregation (GBA), a Bayesian graph aggregator that aggregates contexts considering uncertainties in context data and graph structure. Extensive experiments show that STGNP has desirable properties such as uncertainty estimates and strong learning capabilities, and achieves state-of-the-art results by a clear margin.
Decoupling Long- and Short-Term Patterns in Spatiotemporal Inference
Sep 16, 2021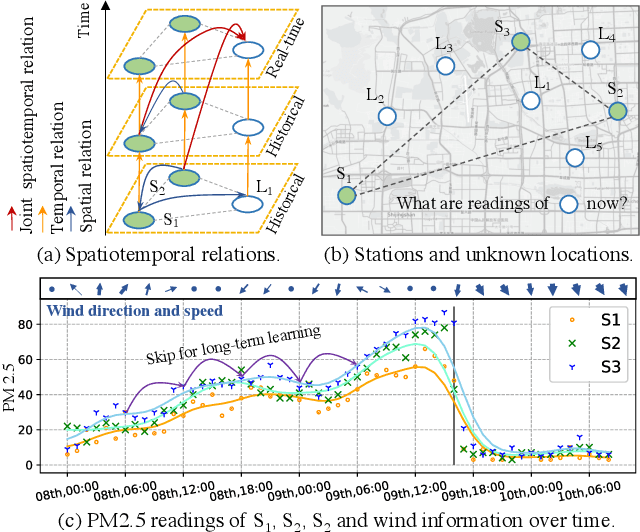
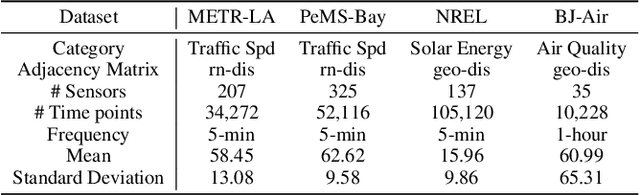


Sensors are the key to sensing the environment and imparting benefits to smart cities in many aspects, such as providing real-time air quality information throughout an urban area. However, a prerequisite is to obtain fine-grained knowledge of the environment. There is a limit to how many sensors can be installed in the physical world due to non-negligible expenses. In this paper, we propose to infer real-time information of any given location in a city based on historical and current observations from the available sensors (termed spatiotemporal inference). Our approach decouples the modeling of short-term and long-term patterns, relying on two major components. Firstly, unlike previous studies that separated the spatial and temporal relation learning, we introduce a joint spatiotemporal graph attention network that learns the short-term dependencies across both the spatial and temporal dimensions. Secondly, we propose an adaptive graph recurrent network with a time skip for capturing long-term patterns. The adaptive adjacency matrices are learned inductively first as the inputs of a recurrent network to learn dynamic dependencies. Experimental results on four public read-world datasets show that our method reduces state-of-the-art baseline mean absolute errors by 5%~12%.
Predicting Long-Term Skeletal Motions by a Spatio-Temporal Hierarchical Recurrent Network
Nov 22, 2019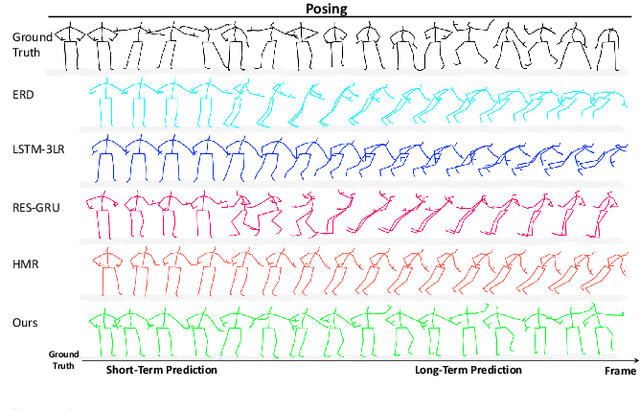
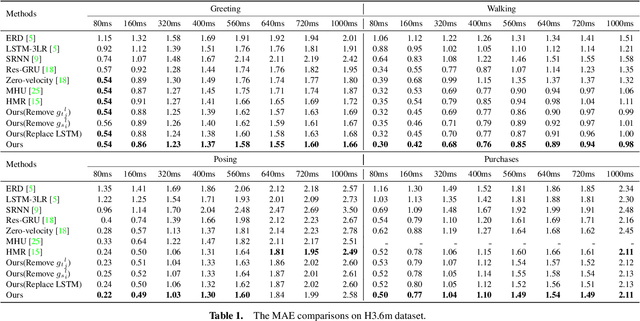
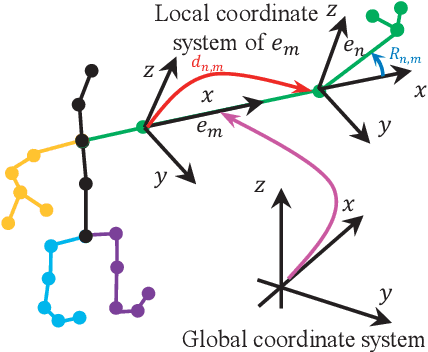
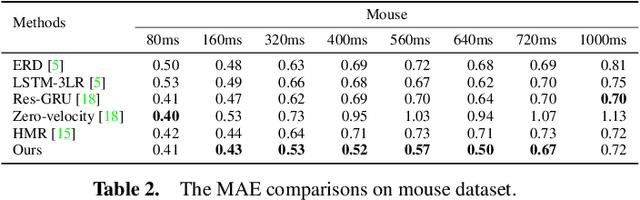
The primary goal of skeletal motion prediction is to generate future motion by observing a sequence of 3D skeletons. A key challenge in motion prediction is the fact that a motion can often be performed in several different ways, with each consisting of its own configuration of poses and their spatio-temporal dependencies, and as a result, the predicted poses often converge to the motionless poses or non-human like motions in long-term prediction. This leads us to define a hierarchical recurrent network model that explicitly characterizes these internal configurations of poses and their local and global spatio-temporal dependencies. The model introduces a latent vector variable from the Lie algebra to represent spatial and temporal relations simultaneously. Furthermore, a structured stack LSTM-based decoder is devised to decode the predicted poses with a new loss function defined to estimate the quantized weight of each body part in a pose. Empirical evaluations on benchmark datasets suggest our approach significantly outperforms the state-of-the-art methods on both short-term and long-term motion prediction.