 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Unifying Diffusion Models for Probabilistic Spatio-Temporal Graph Learning
Paper and Code
Oct 26, 2023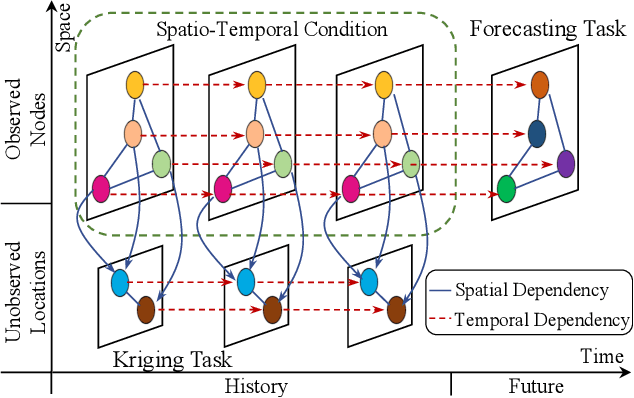



Spatio-temporal graph learning is a fundamental problem in the Web of Things era, which enables a plethora of Web applications such as smart cities, human mobility and climate analysis. Existing approaches tackle different learning tasks independently, tailoring their models to unique task characteristics. These methods, however, fall short of modeling intrinsic uncertainties in the spatio-temporal data. Meanwhile, their specialized designs limit their universality as general spatio-temporal learning solutions. In this paper, we propose to model the learning tasks in a unified perspective, viewing them as predictions based on conditional information with shared spatio-temporal patterns. Based on this proposal, we introduce Unified Spatio-Temporal Diffusion Models (USTD) to address the tasks uniformly within the uncertainty-aware diffusion framework. USTD is holistically designed, comprising a shared spatio-temporal encoder and attention-based denoising networks that are task-specific. The shared encoder, optimized by a pre-training strategy, effectively captures conditional spatio-temporal patterns. The denoising networks, utilizing both cross- and self-attention, integrate conditional dependencies and generate predictions. Opting for forecasting and kriging as downstream tasks, we design Gated Attention (SGA) and Temporal Gated Attention (TGA) for each task, with different emphases on the spatial and temporal dimensions, respectively. By combining the advantages of deterministic encoders and probabilistic diffusion models, USTD achieves state-of-the-art performances compared to deterministic and probabilistic baselines in both tasks, while also providing valuable uncertainty estimates.