 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMixTConv: Mixed Temporal Convolutional Kernels for Efficient Action Recogntion
Jan 25, 2020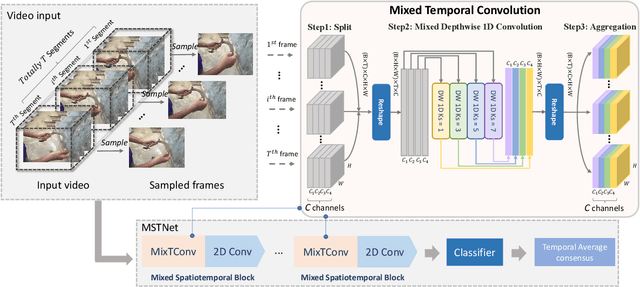
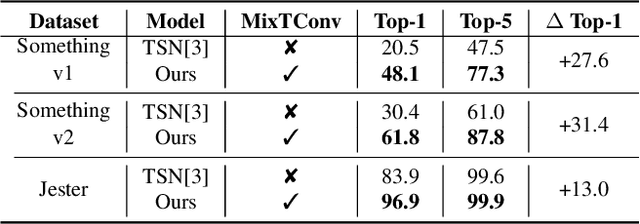
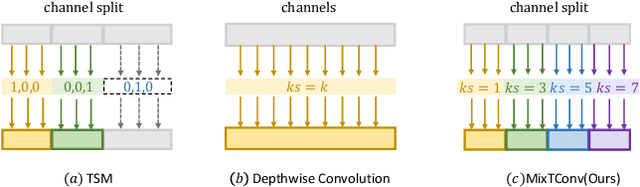
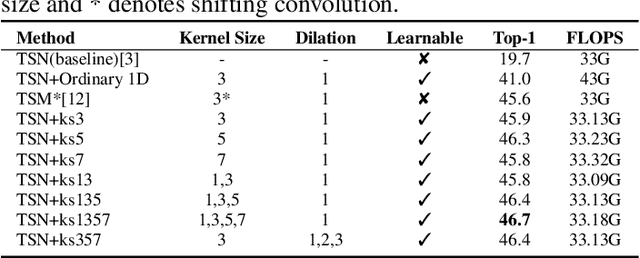
To efficiently extract spatiotemporal features of video for action recognition, most state-of-the-art methods integrate 1D temporal convolution into a conventional 2D CNN backbone. However, they all exploit 1D temporal convolution of fixed kernel size (i.e., 3) in the network building block, thus have suboptimal temporal modeling capability to handle both long-term and short-term actions. To address this problem, we first investigate the impacts of different kernel sizes for the 1D temporal convolutional filters. Then, we propose a simple yet efficient operation called Mixed Temporal Convolution (MixTConv), which consists of multiple depthwise 1D convolutional filters with different kernel sizes. By plugging MixTConv into the conventional 2D CNN backbone ResNet-50, we further propose an efficient and effective network architecture named MSTNet for action recognition, and achieve state-of-the-art results on multiple benchmarks.