 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTD3 with Reverse KL Regularizer for Offline Reinforcement Learning from Mixed Datasets
Dec 05, 2022
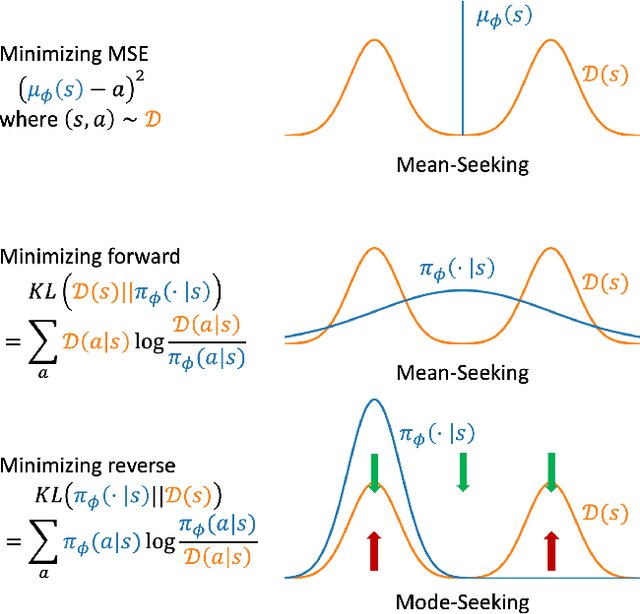
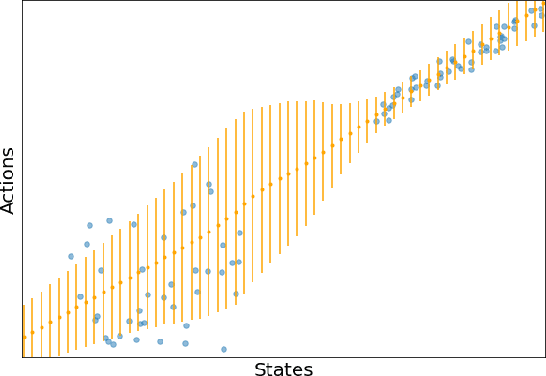
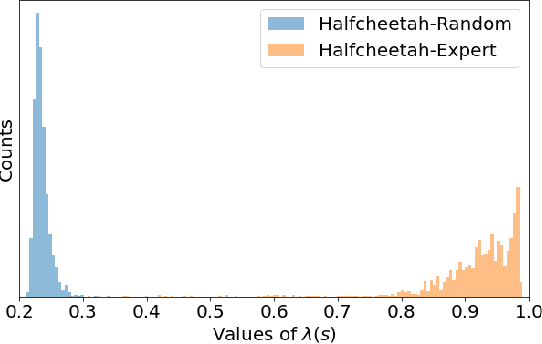
We consider an offline reinforcement learning (RL) setting where the agent need to learn from a dataset collected by rolling out multiple behavior policies. There are two challenges for this setting: 1) The optimal trade-off between optimizing the RL signal and the behavior cloning (BC) signal changes on different states due to the variation of the action coverage induced by different behavior policies. Previous methods fail to handle this by only controlling the global trade-off. 2) For a given state, the action distribution generated by different behavior policies may have multiple modes. The BC regularizers in many previous methods are mean-seeking, resulting in policies that select out-of-distribution (OOD) actions in the middle of the modes. In this paper, we address both challenges by using adaptively weighted reverse Kullback-Leibler (KL) divergence as the BC regularizer based on the TD3 algorithm. Our method not only trades off the RL and BC signals with per-state weights (i.e., strong BC regularization on the states with narrow action coverage, and vice versa) but also avoids selecting OOD actions thanks to the mode-seeking property of reverse KL. Empirically, our algorithm can outperform existing offline RL algorithms in the MuJoCo locomotion tasks with the standard D4RL datasets as well as the mixed datasets that combine the standard datasets.
Less is More: Pre-training a Strong Siamese Encoder Using a Weak Decoder
Feb 18, 2021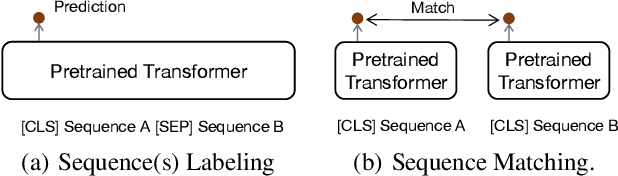
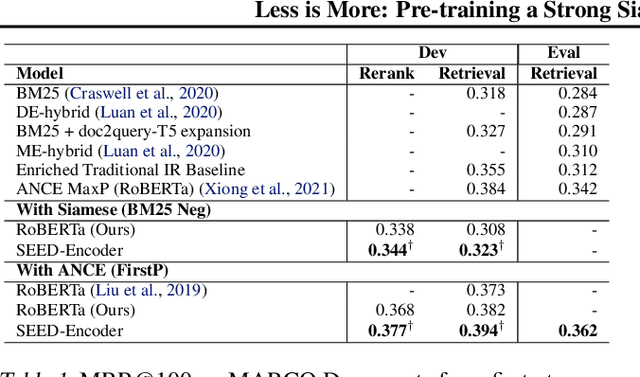
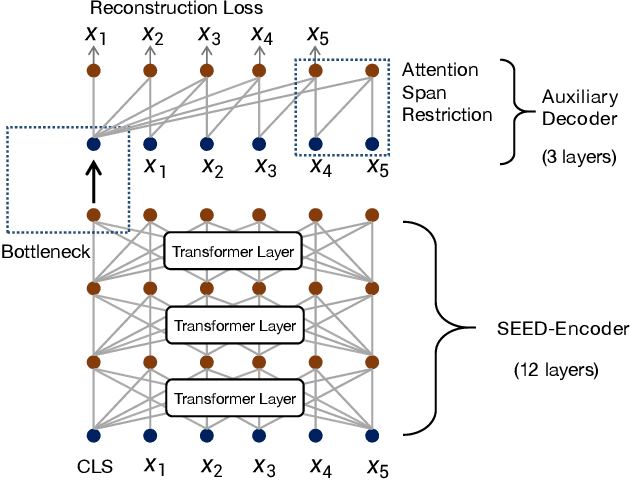
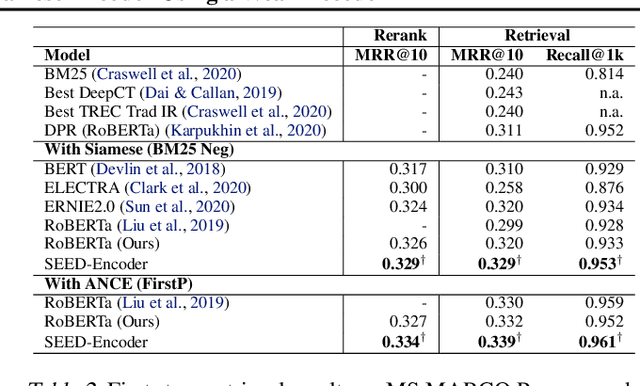
Many real-world applications use Siamese networks to efficiently match text sequences at scale, which require high-quality sequence encodings. This paper pre-trains language models dedicated to sequence matching in Siamese architectures. We first hypothesize that a representation is better for sequence matching if the entire sequence can be reconstructed from it, which, however, is unlikely to be achieved in standard autoencoders: A strong decoder can rely on its capacity and natural language patterns to reconstruct and bypass the needs of better sequence encodings. Therefore we propose a new self-learning method that pretrains the encoder with a weak decoder, which reconstructs the original sequence from the encoder's [CLS] representations but is restricted in both capacity and attention span. In our experiments on web search and recommendation, the pre-trained SEED-Encoder, "SiamEsE oriented encoder by reconstructing from weak decoder", shows significantly better generalization ability when fine-tuned in Siamese networks, improving overall accuracy and few-shot performances. Our code and models will be released.
Fully Parameterized Quantile Function for Distributional Reinforcement Learning
Nov 16, 2019
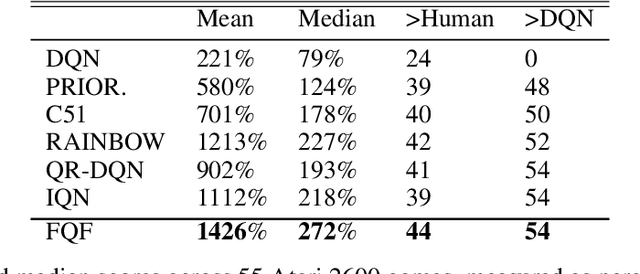
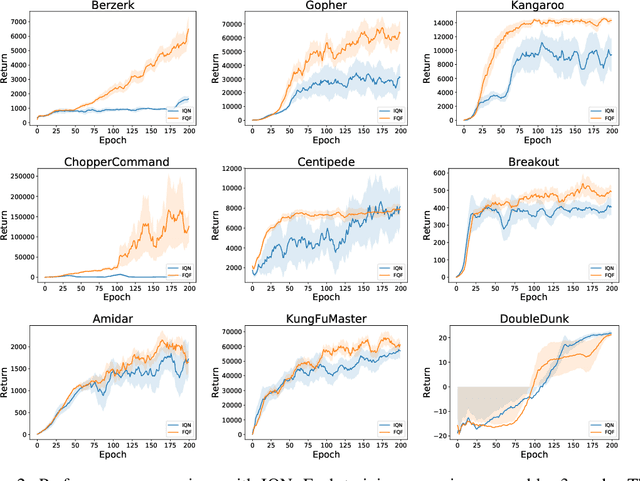

Distributional Reinforcement Learning (RL) differs from traditional RL in that, rather than the expectation of total returns, it estimates distributions and has achieved state-of-the-art performance on Atari Games. The key challenge in practical distributional RL algorithms lies in how to parameterize estimated distributions so as to better approximate the true continuous distribution. Existing distributional RL algorithms parameterize either the probability side or the return value side of the distribution function, leaving the other side uniformly fixed as in C51, QR-DQN or randomly sampled as in IQN. In this paper, we propose fully parameterized quantile function that parameterizes both the quantile fraction axis (i.e., the x-axis) and the value axis (i.e., y-axis) for distributional RL. Our algorithm contains a fraction proposal network that generates a discrete set of quantile fractions and a quantile value network that gives corresponding quantile values. The two networks are jointly trained to find the best approximation of the true distribution. Experiments on 55 Atari Games show that our algorithm significantly outperforms existing distributional RL algorithms and creates a new record for the Atari Learning Environment for non-distributed agents.
LightMC: A Dynamic and Efficient Multiclass Decomposition Algorithm
Aug 25, 2019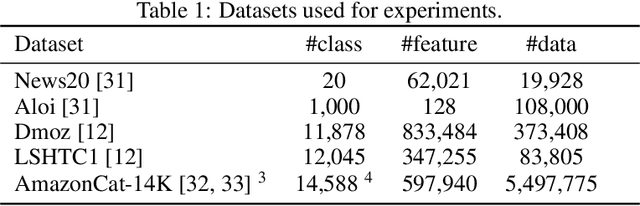

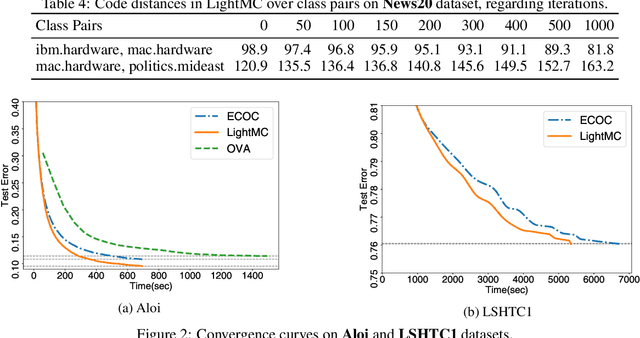
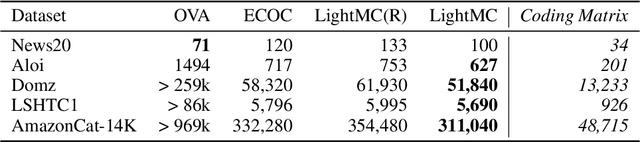
Multiclass decomposition splits a multiclass classification problem into a series of independent binary learners and recomposes them by combining their outputs to reconstruct the multiclass classification results. Three widely-used realizations of such decomposition methods are One-Versus-All (OVA), One-Versus-One (OVO), and Error-Correcting-Output-Code (ECOC). While OVA and OVO are quite simple, both of them assume all classes are orthogonal which neglect the latent correlation between classes in real-world. Error-Correcting-Output-Code (ECOC) based decomposition methods, on the other hand, are more preferable due to its integration of the correlation among classes. However, the performance of existing ECOC-based methods highly depends on the design of coding matrix and decoding strategy. Unfortunately, it is quite uncertain and time-consuming to discover an effective coding matrix with appropriate decoding strategy. To address this problem, we propose LightMC, an efficient dynamic multiclass decomposition algorithm. Instead of using fixed coding matrix and decoding strategy, LightMC uses a differentiable decoding strategy, which enables it to dynamically optimize the coding matrix and decoding strategy, toward increasing the overall accuracy of multiclass classification, via back propagation jointly with the training of base learners in an iterative way. Empirical experimental results on several public large-scale multiclass classification datasets have demonstrated the effectiveness of LightMC in terms of both good accuracy and high efficiency.