 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMDDL: A Framework for Reinforcement Learning-based Position Allocation in Multi-Channel Feed
Apr 17, 2023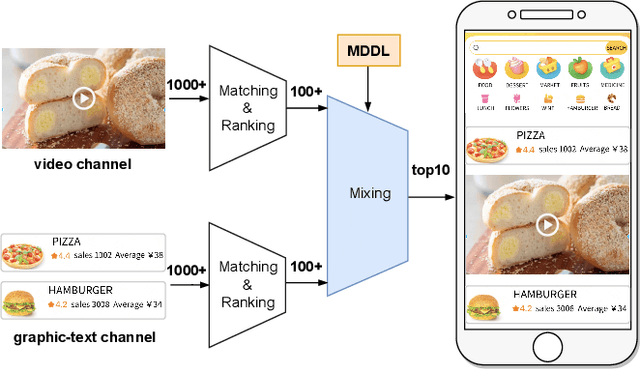

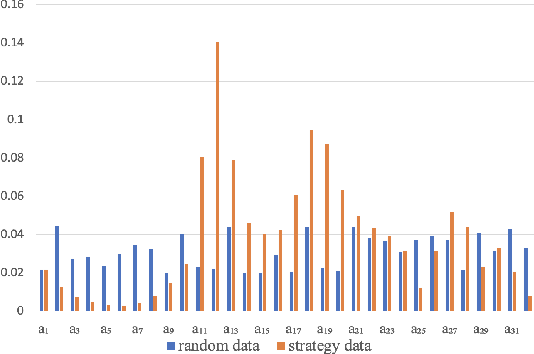
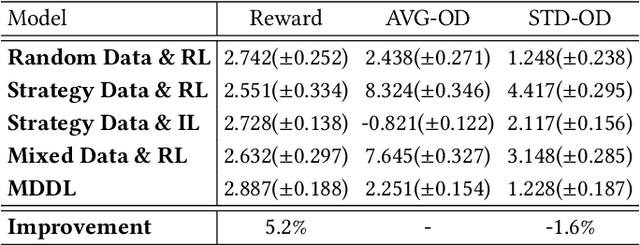
Nowadays, the mainstream approach in position allocation system is to utilize a reinforcement learning model to allocate appropriate locations for items in various channels and then mix them into the feed. There are two types of data employed to train reinforcement learning (RL) model for position allocation, named strategy data and random data. Strategy data is collected from the current online model, it suffers from an imbalanced distribution of state-action pairs, resulting in severe overestimation problems during training. On the other hand, random data offers a more uniform distribution of state-action pairs, but is challenging to obtain in industrial scenarios as it could negatively impact platform revenue and user experience due to random exploration. As the two types of data have different distributions, designing an effective strategy to leverage both types of data to enhance the efficacy of the RL model training has become a highly challenging problem. In this study, we propose a framework named Multi-Distribution Data Learning (MDDL) to address the challenge of effectively utilizing both strategy and random data for training RL models on mixed multi-distribution data. Specifically, MDDL incorporates a novel imitation learning signal to mitigate overestimation problems in strategy data and maximizes the RL signal for random data to facilitate effective learning. In our experiments, we evaluated the proposed MDDL framework in a real-world position allocation system and demonstrated its superior performance compared to the previous baseline. MDDL has been fully deployed on the Meituan food delivery platform and currently serves over 300 million users.
RePreM: Representation Pre-training with Masked Model for Reinforcement Learning
Mar 03, 2023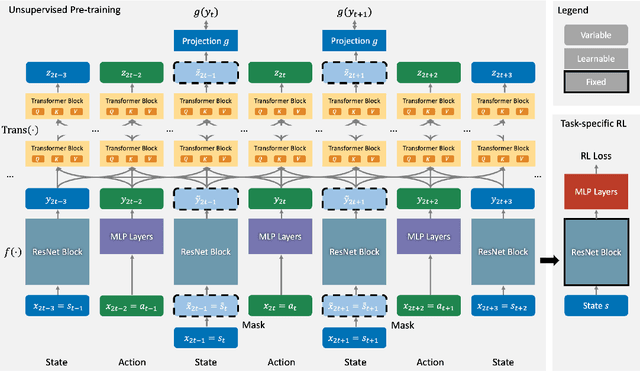
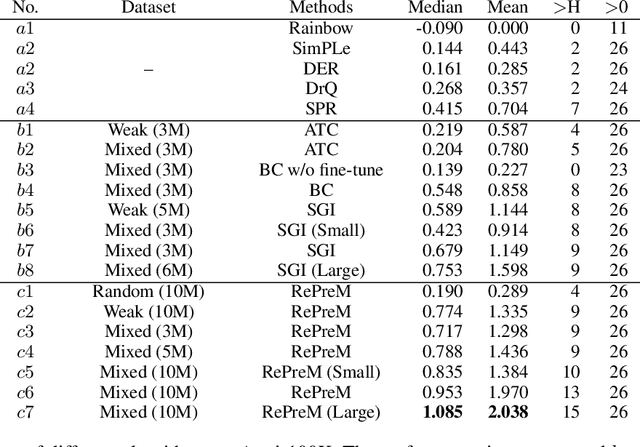
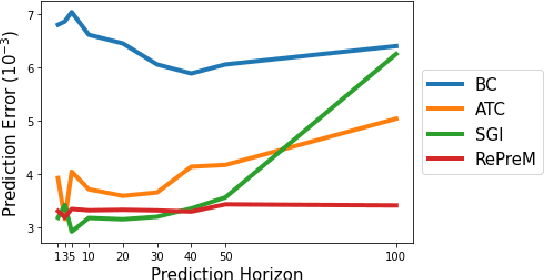
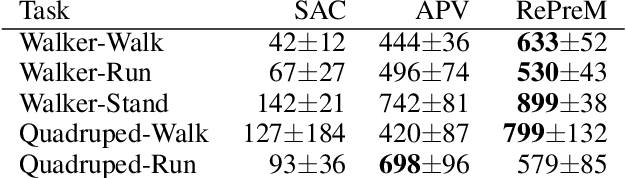
Inspired by the recent success of sequence modeling in RL and the use of masked language model for pre-training, we propose a masked model for pre-training in RL, RePreM (Representation Pre-training with Masked Model), which trains the encoder combined with transformer blocks to predict the masked states or actions in a trajectory. RePreM is simple but effective compared to existing representation pre-training methods in RL. It avoids algorithmic sophistication (such as data augmentation or estimating multiple models) with sequence modeling and generates a representation that captures long-term dynamics well. Empirically, we demonstrate the effectiveness of RePreM in various tasks, including dynamic prediction, transfer learning, and sample-efficient RL with both value-based and actor-critic methods. Moreover, we show that RePreM scales well with dataset size, dataset quality, and the scale of the encoder, which indicates its potential towards big RL models.
TD3 with Reverse KL Regularizer for Offline Reinforcement Learning from Mixed Datasets
Dec 05, 2022
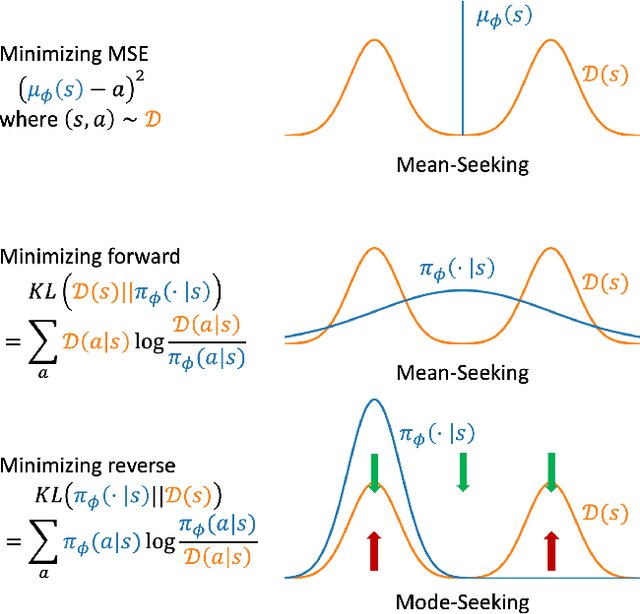
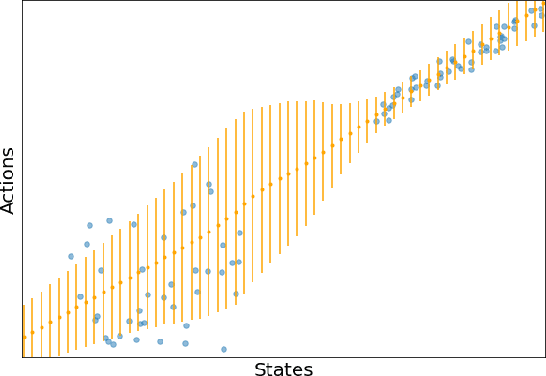
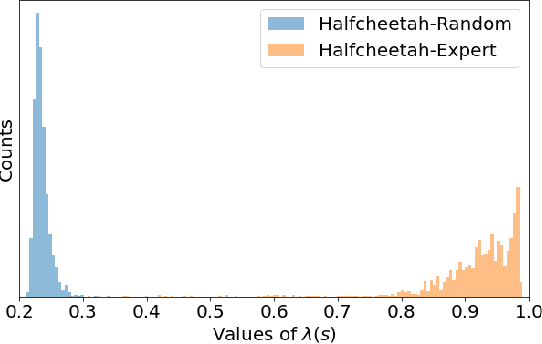
We consider an offline reinforcement learning (RL) setting where the agent need to learn from a dataset collected by rolling out multiple behavior policies. There are two challenges for this setting: 1) The optimal trade-off between optimizing the RL signal and the behavior cloning (BC) signal changes on different states due to the variation of the action coverage induced by different behavior policies. Previous methods fail to handle this by only controlling the global trade-off. 2) For a given state, the action distribution generated by different behavior policies may have multiple modes. The BC regularizers in many previous methods are mean-seeking, resulting in policies that select out-of-distribution (OOD) actions in the middle of the modes. In this paper, we address both challenges by using adaptively weighted reverse Kullback-Leibler (KL) divergence as the BC regularizer based on the TD3 algorithm. Our method not only trades off the RL and BC signals with per-state weights (i.e., strong BC regularization on the states with narrow action coverage, and vice versa) but also avoids selecting OOD actions thanks to the mode-seeking property of reverse KL. Empirically, our algorithm can outperform existing offline RL algorithms in the MuJoCo locomotion tasks with the standard D4RL datasets as well as the mixed datasets that combine the standard datasets.
Exploration by Maximizing Rényi Entropy for Zero-Shot Meta RL
Jun 11, 2020
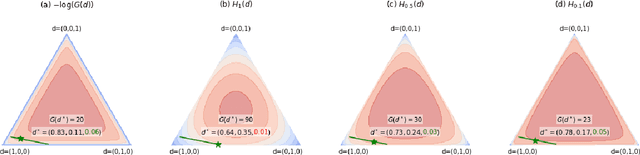
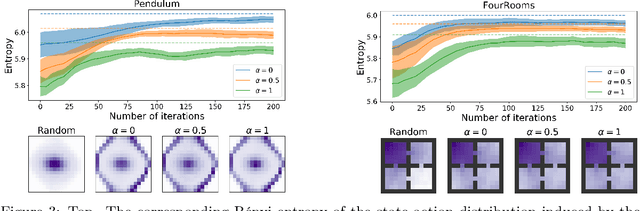
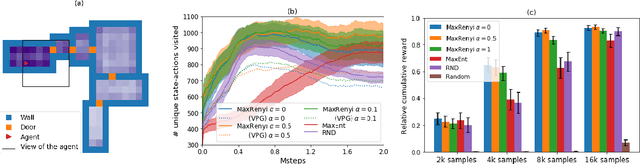
Exploring the transition dynamics is essential to the success of reinforcement learning (RL) algorithms. To face the challenges of exploration, we consider a zero-shot meta RL framework that completely separates exploration from exploitation and is suitable for the meta RL setting where there are many reward functions of interest. In the exploration phase, the agent learns an exploratory policy by interacting with a reward-free environment and collects a dataset of transitions by executing the policy. In the planning phase, the agent computes a good policy for any reward function based on the dataset without further interacting with the environment. This framework brings new challenges for exploration algorithms. In the exploration phase, we propose to maximize the R\'enyi entropy over the state-action space and justify this objective theoretically. We further deduce a policy gradient formulation for this objective and design a practical exploration algorithm that can deal with complex environments based on PPO. In the planning phase, we use a batch RL algorithm, batch constrained deep Q-learning (BCQ), to solve for good policies given arbitrary reward functions. Empirically, we show that our exploration algorithm is effective and sample efficient, and results in superior policies for arbitrary reward functions in the planning phase.