 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRePreM: Representation Pre-training with Masked Model for Reinforcement Learning
Paper and Code
Mar 03, 2023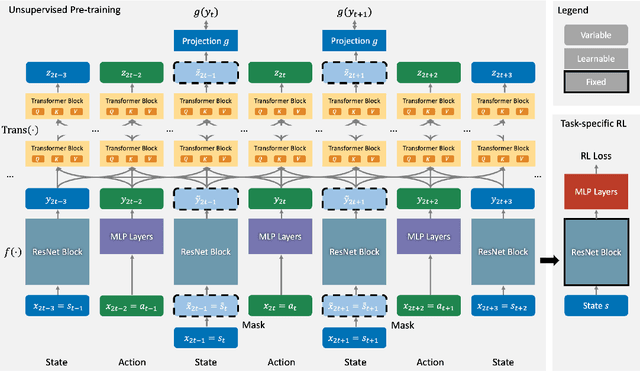
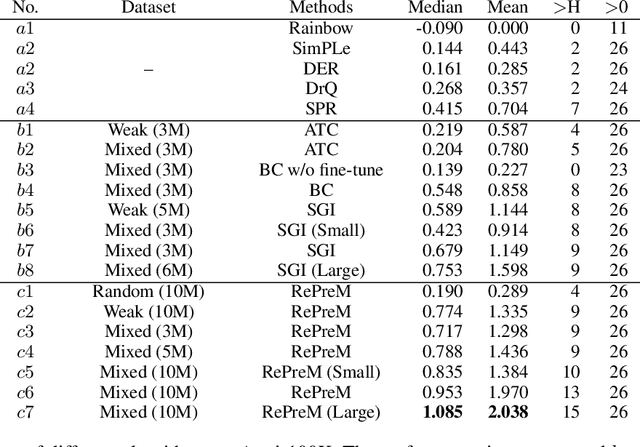
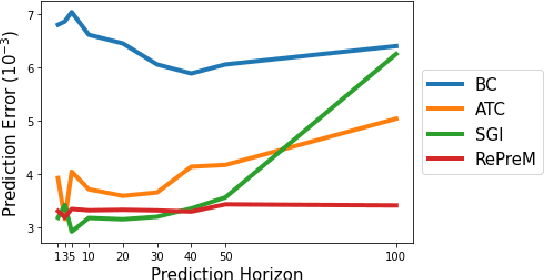
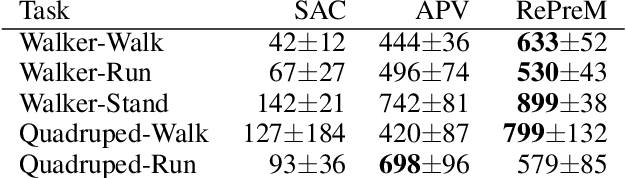
Inspired by the recent success of sequence modeling in RL and the use of masked language model for pre-training, we propose a masked model for pre-training in RL, RePreM (Representation Pre-training with Masked Model), which trains the encoder combined with transformer blocks to predict the masked states or actions in a trajectory. RePreM is simple but effective compared to existing representation pre-training methods in RL. It avoids algorithmic sophistication (such as data augmentation or estimating multiple models) with sequence modeling and generates a representation that captures long-term dynamics well. Empirically, we demonstrate the effectiveness of RePreM in various tasks, including dynamic prediction, transfer learning, and sample-efficient RL with both value-based and actor-critic methods. Moreover, we show that RePreM scales well with dataset size, dataset quality, and the scale of the encoder, which indicates its potential towards big RL models.