 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKALIE: Fine-Tuning Vision-Language Models for Open-World Manipulation without Robot Data
Sep 21, 2024
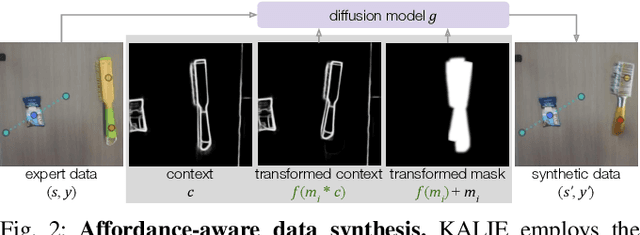


Building generalist robotic systems involves effectively endowing robots with the capabilities to handle novel objects in an open-world setting. Inspired by the advances of large pre-trained models, we propose Keypoint Affordance Learning from Imagined Environments (KALIE), which adapts pre-trained Vision Language Models (VLMs) for robotic control in a scalable manner. Instead of directly producing motor commands, KALIE controls the robot by predicting point-based affordance representations based on natural language instructions and visual observations of the scene. The VLM is trained on 2D images with affordances labeled by humans, bypassing the need for training data collected on robotic systems. Through an affordance-aware data synthesis pipeline, KALIE automatically creates massive high-quality training data based on limited example data manually collected by humans. We demonstrate that KALIE can learn to robustly solve new manipulation tasks with unseen objects given only 50 example data points. Compared to baselines using pre-trained VLMs, our approach consistently achieves superior performance.
Evaluating Real-World Robot Manipulation Policies in Simulation
May 09, 2024



The field of robotics has made significant advances towards generalist robot manipulation policies. However, real-world evaluation of such policies is not scalable and faces reproducibility challenges, which are likely to worsen as policies broaden the spectrum of tasks they can perform. We identify control and visual disparities between real and simulated environments as key challenges for reliable simulated evaluation and propose approaches for mitigating these gaps without needing to craft full-fidelity digital twins of real-world environments. We then employ these approaches to create SIMPLER, a collection of simulated environments for manipulation policy evaluation on common real robot setups. Through paired sim-and-real evaluations of manipulation policies, we demonstrate strong correlation between policy performance in SIMPLER environments and in the real world. Additionally, we find that SIMPLER evaluations accurately reflect real-world policy behavior modes such as sensitivity to various distribution shifts. We open-source all SIMPLER environments along with our workflow for creating new environments at https://simpler-env.github.io to facilitate research on general-purpose manipulation policies and simulated evaluation frameworks.
DROID: A Large-Scale In-The-Wild Robot Manipulation Dataset
Mar 19, 2024



The creation of large, diverse, high-quality robot manipulation datasets is an important stepping stone on the path toward more capable and robust robotic manipulation policies. However, creating such datasets is challenging: collecting robot manipulation data in diverse environments poses logistical and safety challenges and requires substantial investments in hardware and human labour. As a result, even the most general robot manipulation policies today are mostly trained on data collected in a small number of environments with limited scene and task diversity. In this work, we introduce DROID (Distributed Robot Interaction Dataset), a diverse robot manipulation dataset with 76k demonstration trajectories or 350 hours of interaction data, collected across 564 scenes and 84 tasks by 50 data collectors in North America, Asia, and Europe over the course of 12 months. We demonstrate that training with DROID leads to policies with higher performance and improved generalization ability. We open source the full dataset, policy learning code, and a detailed guide for reproducing our robot hardware setup.