 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAstraNav-Memory: Contexts Compression for Long Memory
Dec 25, 2025Lifelong embodied navigation requires agents to accumulate, retain, and exploit spatial-semantic experience across tasks, enabling efficient exploration in novel environments and rapid goal reaching in familiar ones. While object-centric memory is interpretable, it depends on detection and reconstruction pipelines that limit robustness and scalability. We propose an image-centric memory framework that achieves long-term implicit memory via an efficient visual context compression module end-to-end coupled with a Qwen2.5-VL-based navigation policy. Built atop a ViT backbone with frozen DINOv3 features and lightweight PixelUnshuffle+Conv blocks, our visual tokenizer supports configurable compression rates; for example, under a representative 16$\times$ compression setting, each image is encoded with about 30 tokens, expanding the effective context capacity from tens to hundreds of images. Experimental results on GOAT-Bench and HM3D-OVON show that our method achieves state-of-the-art navigation performance, improving exploration in unfamiliar environments and shortening paths in familiar ones. Ablation studies further reveal that moderate compression provides the best balance between efficiency and accuracy. These findings position compressed image-centric memory as a practical and scalable interface for lifelong embodied agents, enabling them to reason over long visual histories and navigate with human-like efficiency.
AstraNav-World: World Model for Foresight Control and Consistency
Dec 25, 2025Embodied navigation in open, dynamic environments demands accurate foresight of how the world will evolve and how actions will unfold over time. We propose AstraNav-World, an end-to-end world model that jointly reasons about future visual states and action sequences within a unified probabilistic framework. Our framework integrates a diffusion-based video generator with a vision-language policy, enabling synchronized rollouts where predicted scenes and planned actions are updated simultaneously. Training optimizes two complementary objectives: generating action-conditioned multi-step visual predictions and deriving trajectories conditioned on those predicted visuals. This bidirectional constraint makes visual predictions executable and keeps decisions grounded in physically consistent, task-relevant futures, mitigating cumulative errors common in decoupled "envision-then-plan" pipelines. Experiments across diverse embodied navigation benchmarks show improved trajectory accuracy and higher success rates. Ablations confirm the necessity of tight vision-action coupling and unified training, with either branch removal degrading both prediction quality and policy reliability. In real-world testing, AstraNav-World demonstrated exceptional zero-shot capabilities, adapting to previously unseen scenarios without any real-world fine-tuning. These results suggest that AstraNav-World captures transferable spatial understanding and planning-relevant navigation dynamics, rather than merely overfitting to simulation-specific data distribution. Overall, by unifying foresight vision and control within a single generative model, we move closer to reliable, interpretable, and general-purpose embodied agents that operate robustly in open-ended real-world settings.
Controllable Longer Image Animation with Diffusion Models
May 28, 2024



Generating realistic animated videos from static images is an important area of research in computer vision. Methods based on physical simulation and motion prediction have achieved notable advances, but they are often limited to specific object textures and motion trajectories, failing to exhibit highly complex environments and physical dynamics. In this paper, we introduce an open-domain controllable image animation method using motion priors with video diffusion models. Our method achieves precise control over the direction and speed of motion in the movable region by extracting the motion field information from videos and learning moving trajectories and strengths. Current pretrained video generation models are typically limited to producing very short videos, typically less than 30 frames. In contrast, we propose an efficient long-duration video generation method based on noise reschedule specifically tailored for image animation tasks, facilitating the creation of videos over 100 frames in length while maintaining consistency in content scenery and motion coordination. Specifically, we decompose the denoise process into two distinct phases: the shaping of scene contours and the refining of motion details. Then we reschedule the noise to control the generated frame sequences maintaining long-distance noise correlation. We conducted extensive experiments with 10 baselines, encompassing both commercial tools and academic methodologies, which demonstrate the superiority of our method. Our project page: https://wangqiang9.github.io/Controllable.github.io/
Makeup216: Logo Recognition with Adversarial Attention Representations
Dec 13, 2021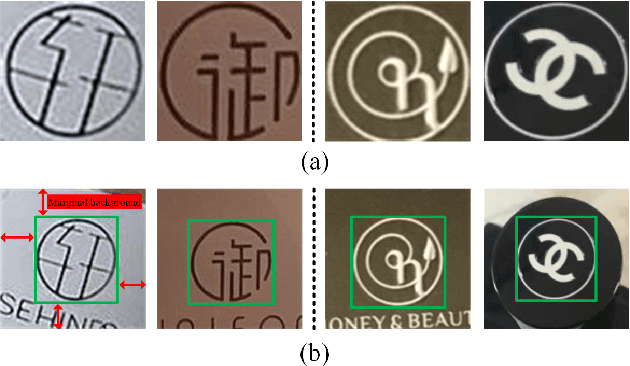
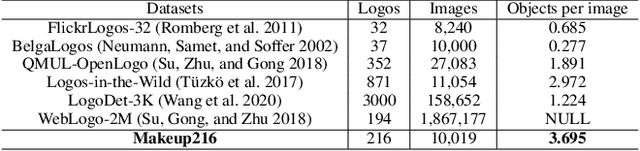

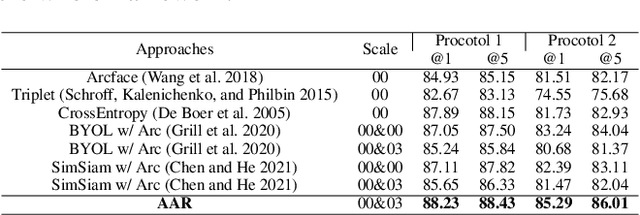
One of the challenges of logo recognition lies in the diversity of forms, such as symbols, texts or a combination of both; further, logos tend to be extremely concise in design while similar in appearance, suggesting the difficulty of learning discriminative representations. To investigate the variety and representation of logo, we introduced Makeup216, the largest and most complex logo dataset in the field of makeup, captured from the real world. It comprises of 216 logos and 157 brands, including 10,019 images and 37,018 annotated logo objects. In addition, we found that the marginal background around the pure logo can provide a important context information and proposed an adversarial attention representation framework (AAR) to attend on the logo subject and auxiliary marginal background separately, which can be combined for better representation. Our proposed framework achieved competitive results on Makeup216 and another large-scale open logo dataset, which could provide fresh thinking for logo recognition. The dataset of Makeup216 and the code of the proposed framework will be released soon.