 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMakeup216: Logo Recognition with Adversarial Attention Representations
Paper and Code
Dec 13, 2021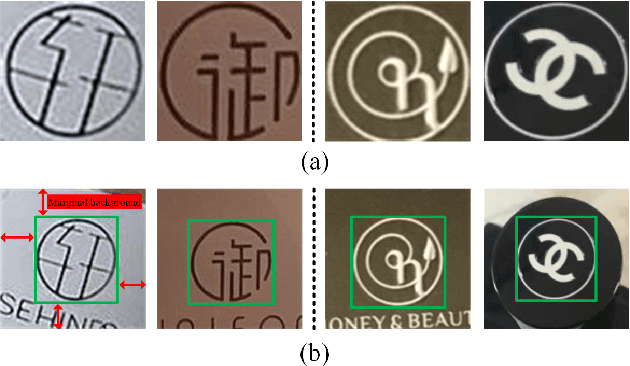
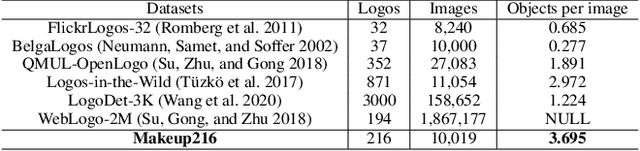

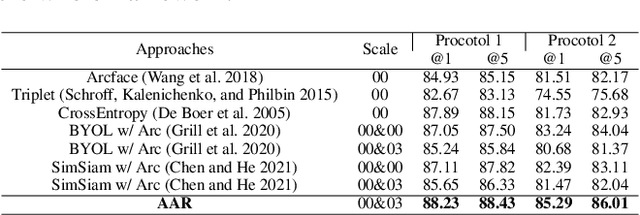
One of the challenges of logo recognition lies in the diversity of forms, such as symbols, texts or a combination of both; further, logos tend to be extremely concise in design while similar in appearance, suggesting the difficulty of learning discriminative representations. To investigate the variety and representation of logo, we introduced Makeup216, the largest and most complex logo dataset in the field of makeup, captured from the real world. It comprises of 216 logos and 157 brands, including 10,019 images and 37,018 annotated logo objects. In addition, we found that the marginal background around the pure logo can provide a important context information and proposed an adversarial attention representation framework (AAR) to attend on the logo subject and auxiliary marginal background separately, which can be combined for better representation. Our proposed framework achieved competitive results on Makeup216 and another large-scale open logo dataset, which could provide fresh thinking for logo recognition. The dataset of Makeup216 and the code of the proposed framework will be released soon.