 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeROD: Reception-aware Online Distillation for Sparse Graphs
Paper and Code
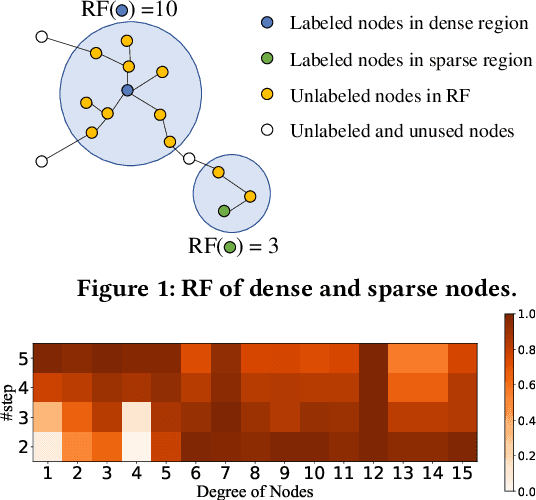
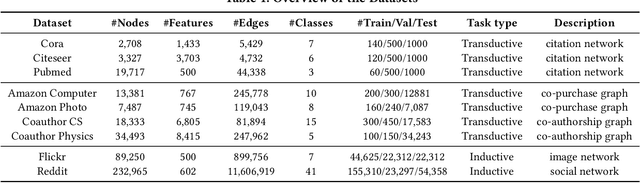
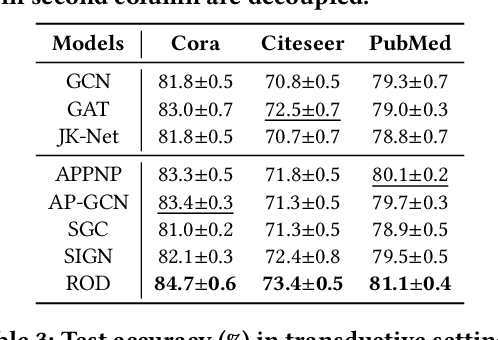
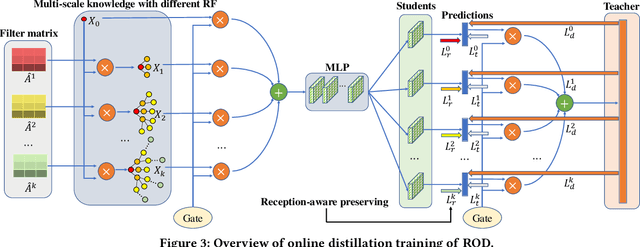
Graph neural networks (GNNs) have been widely used in many graph-based tasks such as node classification, link prediction, and node clustering. However, GNNs gain their performance benefits mainly from performing the feature propagation and smoothing across the edges of the graph, thus requiring sufficient connectivity and label information for effective propagation. Unfortunately, many real-world networks are sparse in terms of both edges and labels, leading to sub-optimal performance of GNNs. Recent interest in this sparse problem has focused on the self-training approach, which expands supervised signals with pseudo labels. Nevertheless, the self-training approach inherently cannot realize the full potential of refining the learning performance on sparse graphs due to the unsatisfactory quality and quantity of pseudo labels. In this paper, we propose ROD, a novel reception-aware online knowledge distillation approach for sparse graph learning. We design three supervision signals for ROD: multi-scale reception-aware graph knowledge, task-based supervision, and rich distilled knowledge, allowing online knowledge transfer in a peer-teaching manner. To extract knowledge concealed in the multi-scale reception fields, ROD explicitly requires individual student models to preserve different levels of locality information. For a given task, each student would predict based on its reception-scale knowledge, while simultaneously a strong teacher is established on-the-fly by combining multi-scale knowledge. Our approach has been extensively evaluated on 9 datasets and a variety of graph-based tasks, including node classification, link prediction, and node clustering. The result demonstrates that ROD achieves state-of-art performance and is more robust for the graph sparsity.