 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Learning-Driven Friendly Jamming for Secure Multicarrier ISAC Under Channel Uncertainty
Mar 05, 2026Integrated sensing and communication (ISAC) systems promise efficient spectrum utilization by jointly supporting radar sensing and wireless communication. This paper presents a deep learning-driven framework for enhancing physical-layer security in multicarrier ISAC systems under imperfect channel state information (CSI) and in the presence of unknown eavesdropper (Eve) locations. Unlike conventional ISAC-based friendly jamming (FJ) approaches that require Eve's CSI or precise angle-of-arrival (AoA) estimates, our method exploits radar echo feedback to guide directional jamming without explicit Eve's information. To enhance robustness to radar sensing uncertainty, we propose a radar-aware neural network that jointly optimizes beamforming and jamming by integrating a novel nonparametric Fisher Information Matrix (FIM) estimator based on f-divergence. The jamming design satisfies the Cramer-Rao lower bound (CRLB) constraints even in the presence of noisy AoA. For efficient implementation, we introduce a quantized tensor train-based encoder that reduces the model size by more than 100 times with negligible performance loss. We also integrate a non-overlapping secure scheme into the proposed framework, in which specific sub-bands can be dedicated solely to communication. Extensive simulations demonstrate that the proposed solution achieves significant improvements in secrecy rate, reduced block error rate (BLER), and strong robustness against CSI uncertainty and angular estimation errors, underscoring the effectiveness of the proposed deep learning-driven friendly jamming framework under practical ISAC impairments.
SANet: A Semantic-aware Agentic AI Networking Framework for Cross-layer Optimization in 6G
Dec 27, 2025Agentic AI networking (AgentNet) is a novel AI-native networking paradigm in which a large number of specialized AI agents collaborate to perform autonomous decision-making, dynamic environmental adaptation, and complex missions. It has the potential to facilitate real-time network management and optimization functions, including self-configuration, self-optimization, and self-adaptation across diverse and complex environments. This paper proposes SANet, a novel semantic-aware AgentNet architecture for wireless networks that can infer the semantic goal of the user and automatically assign agents associated with different layers of the network to fulfill the inferred goal. Motivated by the fact that AgentNet is a decentralized framework in which collaborating agents may generally have different and even conflicting objectives, we formulate the decentralized optimization of SANet as a multi-agent multi-objective problem, and focus on finding the Pareto-optimal solution for agents with distinct and potentially conflicting objectives. We propose three novel metrics for evaluating SANet. Furthermore, we develop a model partition and sharing (MoPS) framework in which large models, e.g., deep learning models, of different agents can be partitioned into shared and agent-specific parts that are jointly constructed and deployed according to agents' local computational resources. Two decentralized optimization algorithms are proposed. We derive theoretical bounds and prove that there exists a three-way tradeoff among optimization, generalization, and conflicting errors. We develop an open-source RAN and core network-based hardware prototype that implements agents to interact with three different layers of the network. Experimental results show that the proposed framework achieved performance gains of up to 14.61% while requiring only 44.37% of FLOPs required by state-of-the-art algorithms.
Filtered Randomized Smoothing: A New Defense for Robust Modulation Classification
Oct 08, 2024



Deep Neural Network (DNN) based classifiers have recently been used for the modulation classification of RF signals. These classifiers have shown impressive performance gains relative to conventional methods, however, they are vulnerable to imperceptible (low-power) adversarial attacks. Some of the prominent defense approaches include adversarial training (AT) and randomized smoothing (RS). While AT increases robustness in general, it fails to provide resilience against previously unseen adaptive attacks. Other approaches, such as Randomized Smoothing (RS), which injects noise into the input, address this shortcoming by providing provable certified guarantees against arbitrary attacks, however, they tend to sacrifice accuracy. In this paper, we study the problem of designing robust DNN-based modulation classifiers that can provide provable defense against arbitrary attacks without significantly sacrificing accuracy. To this end, we first analyze the spectral content of commonly studied attacks on modulation classifiers for the benchmark RadioML dataset. We observe that spectral signatures of un-perturbed RF signals are highly localized, whereas attack signals tend to be spread out in frequency. To exploit this spectral heterogeneity, we propose Filtered Randomized Smoothing (FRS), a novel defense which combines spectral filtering together with randomized smoothing. FRS can be viewed as a strengthening of RS by leveraging the specificity (spectral Heterogeneity) inherent to the modulation classification problem. In addition to providing an approach to compute the certified accuracy of FRS, we also provide a comprehensive set of simulations on the RadioML dataset to show the effectiveness of FRS and show that it significantly outperforms existing defenses including AT and RS in terms of accuracy on both attacked and benign signals.
Securing MIMO Wiretap Channel with Learning-Based Friendly Jamming under Imperfect CSI
Dec 12, 2023



Wireless communications are particularly vulnerable to eavesdropping attacks due to their broadcast nature. To effectively deal with eavesdroppers, existing security techniques usually require accurate channel state information (CSI), e.g., for friendly jamming (FJ), and/or additional computing resources at transceivers, e.g., cryptography-based solutions, which unfortunately may not be feasible in practice. This challenge is even more acute in low-end IoT devices. We thus introduce a novel deep learning-based FJ framework that can effectively defeat eavesdropping attacks with imperfect CSI and even without CSI of legitimate channels. In particular, we first develop an autoencoder-based communication architecture with FJ, namely AEFJ, to jointly maximize the secrecy rate and minimize the block error rate at the receiver without requiring perfect CSI of the legitimate channels. In addition, to deal with the case without CSI, we leverage the mutual information neural estimation (MINE) concept and design a MINE-based FJ scheme that can achieve comparable security performance to the conventional FJ methods that require perfect CSI. Extensive simulations in a multiple-input multiple-output (MIMO) system demonstrate that our proposed solution can effectively deal with eavesdropping attacks in various settings. Moreover, the proposed framework can seamlessly integrate MIMO security and detection tasks into a unified end-to-end learning process. This integrated approach can significantly maximize the throughput and minimize the block error rate, offering a good solution for enhancing communication security in wireless communication systems.
RADIANCE: Radio-Frequency Adversarial Deep-learning Inference for Automated Network Coverage Estimation
Aug 21, 2023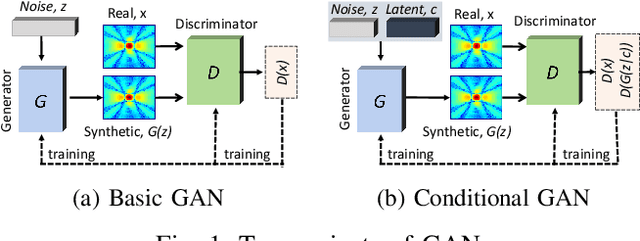

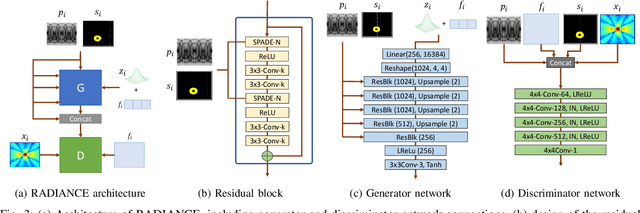

Radio-frequency coverage maps (RF maps) are extensively utilized in wireless networks for capacity planning, placement of access points and base stations, localization, and coverage estimation. Conducting site surveys to obtain RF maps is labor-intensive and sometimes not feasible. In this paper, we propose radio-frequency adversarial deep-learning inference for automated network coverage estimation (RADIANCE), a generative adversarial network (GAN) based approach for synthesizing RF maps in indoor scenarios. RADIANCE utilizes a semantic map, a high-level representation of the indoor environment to encode spatial relationships and attributes of objects within the environment and guide the RF map generation process. We introduce a new gradient-based loss function that computes the magnitude and direction of change in received signal strength (RSS) values from a point within the environment. RADIANCE incorporates this loss function along with the antenna pattern to capture signal propagation within a given indoor configuration and generate new patterns under new configuration, antenna (beam) pattern, and center frequency. Extensive simulations are conducted to compare RADIANCE with ray-tracing simulations of RF maps. Our results show that RADIANCE achieves a mean average error (MAE) of 0.09, root-mean-squared error (RMSE) of 0.29, peak signal-to-noise ratio (PSNR) of 10.78, and multi-scale structural similarity index (MS-SSIM) of 0.80.
Distributed Traffic Synthesis and Classification in Edge Networks: A Federated Self-supervised Learning Approach
Feb 01, 2023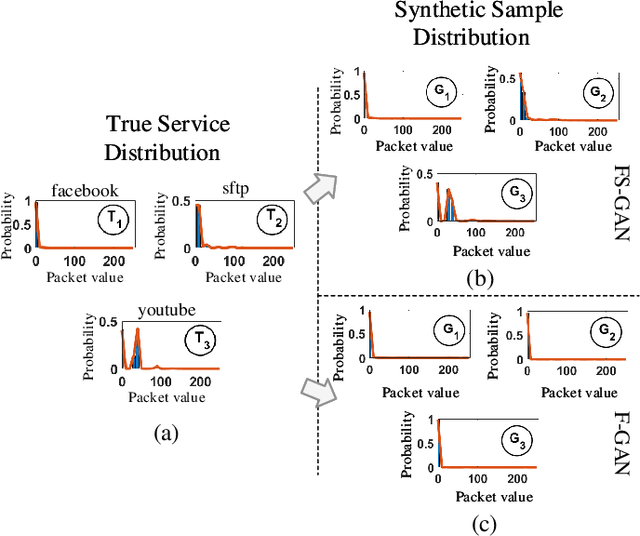
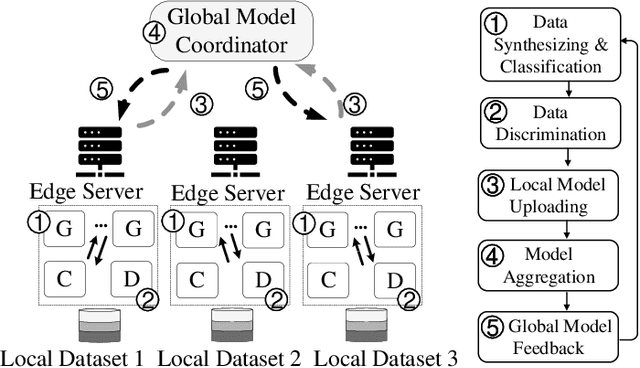
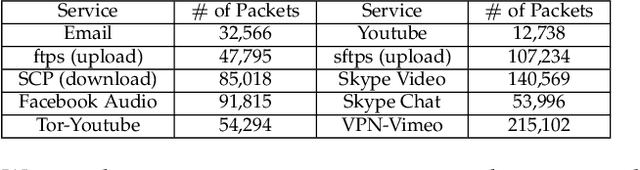
With the rising demand for wireless services and increased awareness of the need for data protection, existing network traffic analysis and management architectures are facing unprecedented challenges in classifying and synthesizing the increasingly diverse services and applications. This paper proposes FS-GAN, a federated self-supervised learning framework to support automatic traffic analysis and synthesis over a large number of heterogeneous datasets. FS-GAN is composed of multiple distributed Generative Adversarial Networks (GANs), with a set of generators, each being designed to generate synthesized data samples following the distribution of an individual service traffic, and each discriminator being trained to differentiate the synthesized data samples and the real data samples of a local dataset. A federated learning-based framework is adopted to coordinate local model training processes of different GANs across different datasets. FS-GAN can classify data of unknown types of service and create synthetic samples that capture the traffic distribution of the unknown types. We prove that FS-GAN can minimize the Jensen-Shannon Divergence (JSD) between the distribution of real data across all the datasets and that of the synthesized data samples. FS-GAN also maximizes the JSD among the distributions of data samples created by different generators, resulting in each generator producing synthetic data samples that follow the same distribution as one particular service type. Extensive simulation results show that the classification accuracy of FS-GAN achieves over 20% improvement in average compared to the state-of-the-art clustering-based traffic analysis algorithms. FS-GAN also has the capability to synthesize highly complex mixtures of traffic types without requiring any human-labeled data samples.
Time-sensitive Learning for Heterogeneous Federated Edge Intelligence
Jan 26, 2023



Real-time machine learning has recently attracted significant interest due to its potential to support instantaneous learning, adaptation, and decision making in a wide range of application domains, including self-driving vehicles, intelligent transportation, and industry automation. We investigate real-time ML in a federated edge intelligence (FEI) system, an edge computing system that implements federated learning (FL) solutions based on data samples collected and uploaded from decentralized data networks. FEI systems often exhibit heterogenous communication and computational resource distribution, as well as non-i.i.d. data samples, resulting in long model training time and inefficient resource utilization. Motivated by this fact, we propose a time-sensitive federated learning (TS-FL) framework to minimize the overall run-time for collaboratively training a shared ML model. Training acceleration solutions for both TS-FL with synchronous coordination (TS-FL-SC) and asynchronous coordination (TS-FL-ASC) are investigated. To address straggler effect in TS-FL-SC, we develop an analytical solution to characterize the impact of selecting different subsets of edge servers on the overall model training time. A server dropping-based solution is proposed to allow slow-performance edge servers to be removed from participating in model training if their impact on the resulting model accuracy is limited. A joint optimization algorithm is proposed to minimize the overall time consumption of model training by selecting participating edge servers, local epoch number. We develop an analytical expression to characterize the impact of staleness effect of asynchronous coordination and straggler effect of FL on the time consumption of TS-FL-ASC. Experimental results show that TS-FL-SC and TS-FL-ASC can provide up to 63% and 28% of reduction, in the overall model training time, respectively.
* IEEE Link: https://ieeexplore.ieee.org/document/10018200
Automatic Machine Learning for Multi-Receiver CNN Technology Classifiers
Apr 28, 2022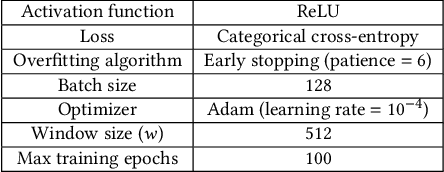
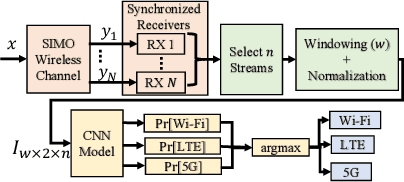

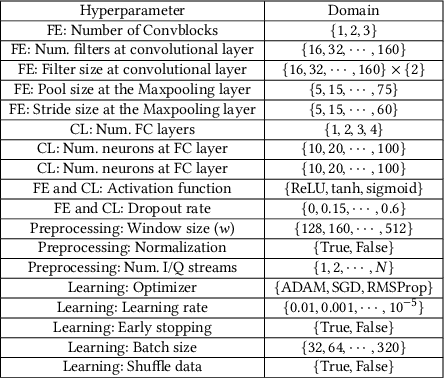
Convolutional Neural Networks (CNNs) are one of the most studied family of deep learning models for signal classification, including modulation, technology, detection, and identification. In this work, we focus on technology classification based on raw I/Q samples collected from multiple synchronized receivers. As an example use case, we study protocol identification of Wi-Fi, LTE-LAA, and 5G NR-U technologies that coexist over the 5 GHz Unlicensed National Information Infrastructure (U-NII) bands. Designing and training accurate CNN classifiers involve significant time and effort that goes into fine-tuning a model's architectural settings and determining the appropriate hyperparameter configurations, such as learning rate and batch size. We tackle the former by defining architectural settings themselves as hyperparameters. We attempt to automatically optimize these architectural parameters, along with other preprocessing (e.g., number of I/Q samples within each classifier input) and learning hyperparameters, by forming a Hyperparameter Optimization (HyperOpt) problem, which we solve in a near-optimal fashion using the Hyperband algorithm. The resulting near-optimal CNN (OCNN) classifier is then used to study classification accuracy for OTA as well as simulations datasets, considering various SNR values. We show that the number of receivers to construct multi-channel inputs for CNNs should be defined as a preprocessing hyperparameter to be optimized via Hyperband. OTA results reveal that our OCNN classifiers improve classification accuracy by 24.58% compared to manually tuned CNNs. We also study the effect of min-max normalization of I/Q samples within each classifier's input on generalization accuracy over simulated datasets with SNRs other than training set's SNR and show an average of 108.05% improvement when I/Q samples are normalized.
CWmin Estimation and Collision Identification in Wi-Fi Systems
Aug 31, 2021
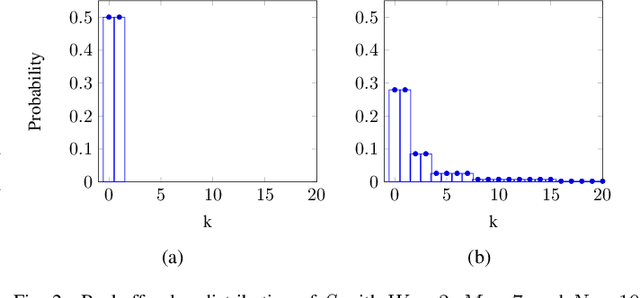

Wi-Fi networks are susceptible to aggressive behavior caused by selfish or malicious devices that reduce their minimum contention window size (CWmin) to below the standard CWmin. In this paper, we propose a scheme called Minimum Contention Window Estimation (CWE) to detect aggressive stations with low CWmin's, where the AP estimates the CWmin value of all stations transmitting uplink by monitoring their backoff values over a period of time and keeping track of the idle time each station spends during backoff. To correctly estimate each backoff value, we present a cross-correlation-based technique that uses the frequency offset between the AP and each station to identify stations involved in uplink collisions. The AP constructs empirical distributions for the monitored backoff values and compares them with a set of nominal PMF's, created via Markov analysis of the DCF protocol to estimate CWmin of various stations. After detecting the aggressive stations, the AP can choose to stop serving those stations. Simulation results show that the accuracy of our collision detection technique is 96%, 94%, and 88% when there are 3, 6, and 9 stations in the WLAN, respectively. For the former WLAN settings, the estimation accuracy of CWE scheme is 100%, 98.81%, and 96.3%, respectively.
Towards Ubiquitous AI in 6G with Federated Learning
Apr 26, 2020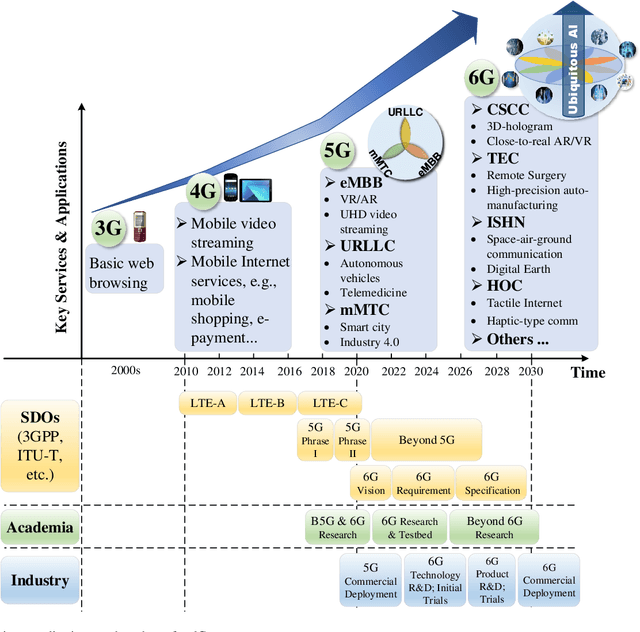
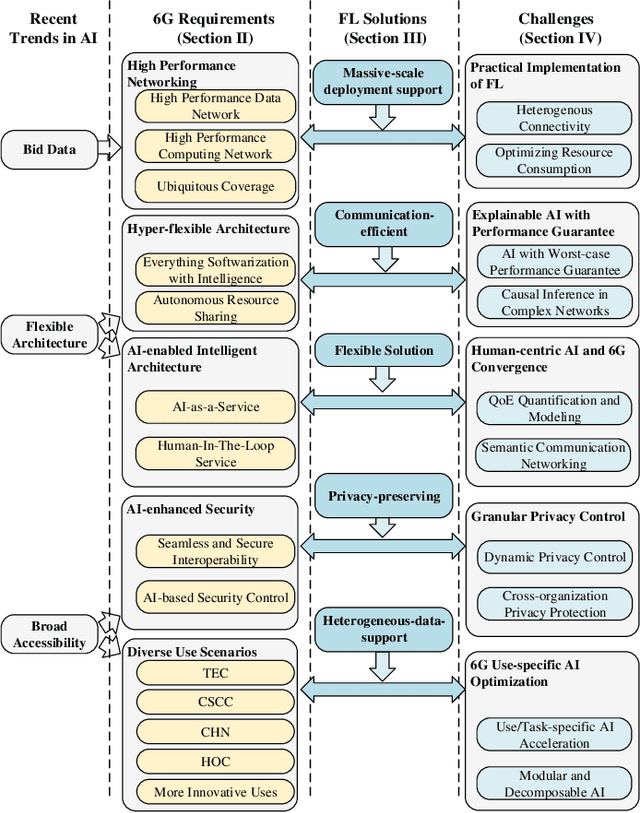
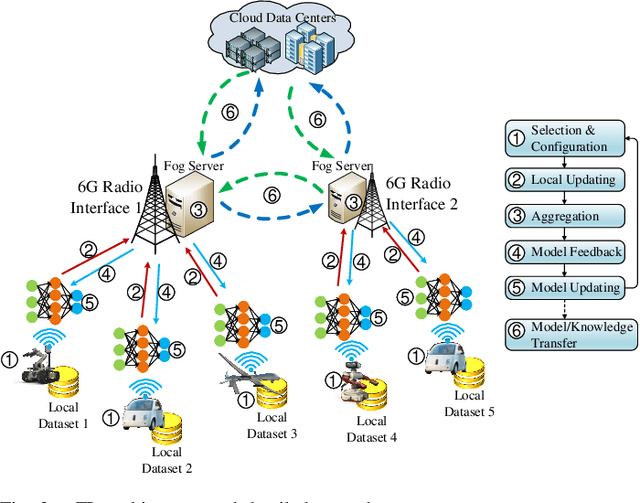
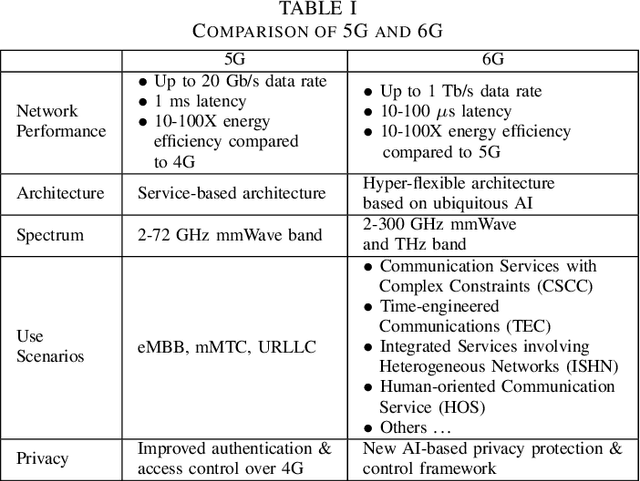
With 5G cellular systems being actively deployed worldwide, the research community has started to explore novel technological advances for the subsequent generation, i.e., 6G. It is commonly believed that 6G will be built on a new vision of ubiquitous AI, an hyper-flexible architecture that brings human-like intelligence into every aspect of networking systems. Despite its great promise, there are several novel challenges expected to arise in ubiquitous AI-based 6G. Although numerous attempts have been made to apply AI to wireless networks, these attempts have not yet seen any large-scale implementation in practical systems. One of the key challenges is the difficulty to implement distributed AI across a massive number of heterogeneous devices. Federated learning (FL) is an emerging distributed AI solution that enables data-driven AI solutions in heterogeneous and potentially massive-scale networks. Although it still in an early stage of development, FL-inspired architecture has been recognized as one of the most promising solutions to fulfill ubiquitous AI in 6G. In this article, we identify the requirements that will drive convergence between 6G and AI. We propose an FL-based network architecture and discuss its potential for addressing some of the novel challenges expected in 6G. Future trends and key research problems for FL-enabled 6G are also discussed.