 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSkillWeaver: Web Agents can Self-Improve by Discovering and Honing Skills
Apr 09, 2025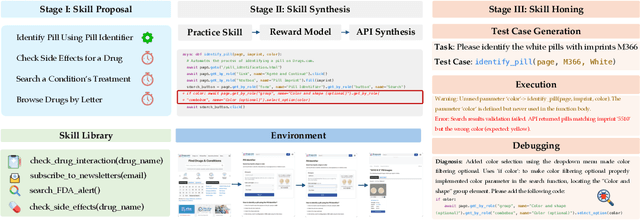
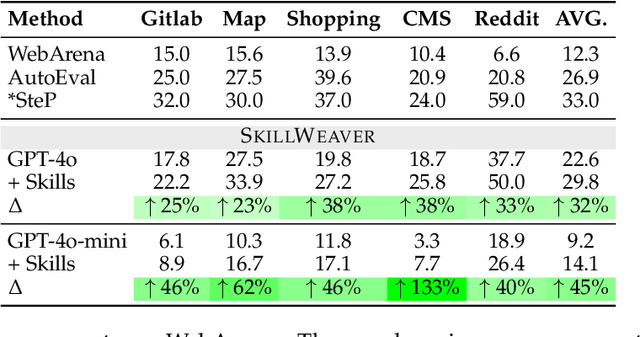

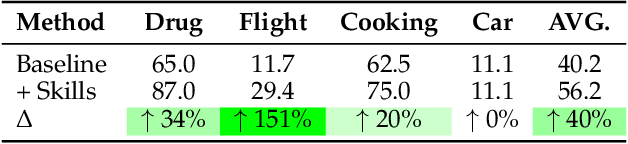
To survive and thrive in complex environments, humans have evolved sophisticated self-improvement mechanisms through environment exploration, hierarchical abstraction of experiences into reuseable skills, and collaborative construction of an ever-growing skill repertoire. Despite recent advancements, autonomous web agents still lack crucial self-improvement capabilities, struggling with procedural knowledge abstraction, refining skills, and skill composition. In this work, we introduce SkillWeaver, a skill-centric framework enabling agents to self-improve by autonomously synthesizing reusable skills as APIs. Given a new website, the agent autonomously discovers skills, executes them for practice, and distills practice experiences into robust APIs. Iterative exploration continually expands a library of lightweight, plug-and-play APIs, significantly enhancing the agent's capabilities. Experiments on WebArena and real-world websites demonstrate the efficacy of SkillWeaver, achieving relative success rate improvements of 31.8% and 39.8%, respectively. Additionally, APIs synthesized by strong agents substantially enhance weaker agents through transferable skills, yielding improvements of up to 54.3% on WebArena. These results demonstrate the effectiveness of honing diverse website interactions into APIs, which can be seamlessly shared among various web agents.
Deceptive Path Planning via Reinforcement Learning with Graph Neural Networks
Feb 09, 2024Deceptive path planning (DPP) is the problem of designing a path that hides its true goal from an outside observer. Existing methods for DPP rely on unrealistic assumptions, such as global state observability and perfect model knowledge, and are typically problem-specific, meaning that even minor changes to a previously solved problem can force expensive computation of an entirely new solution. Given these drawbacks, such methods do not generalize to unseen problem instances, lack scalability to realistic problem sizes, and preclude both on-the-fly tunability of deception levels and real-time adaptivity to changing environments. In this paper, we propose a reinforcement learning (RL)-based scheme for training policies to perform DPP over arbitrary weighted graphs that overcomes these issues. The core of our approach is the introduction of a local perception model for the agent, a new state space representation distilling the key components of the DPP problem, the use of graph neural network-based policies to facilitate generalization and scaling, and the introduction of new deception bonuses that translate the deception objectives of classical methods to the RL setting. Through extensive experimentation we show that, without additional fine-tuning, at test time the resulting policies successfully generalize, scale, enjoy tunable levels of deception, and adapt in real-time to changes in the environment.