 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntrinsicVoice: Empowering LLMs with Intrinsic Real-time Voice Interaction Abilities
Oct 09, 2024



Current methods of building LLMs with voice interaction capabilities rely heavily on explicit text autoregressive generation before or during speech response generation to maintain content quality, which unfortunately brings computational overhead and increases latency in multi-turn interactions. To address this, we introduce IntrinsicVoic,e an LLM designed with intrinsic real-time voice interaction capabilities. IntrinsicVoice aims to facilitate the transfer of textual capabilities of pre-trained LLMs to the speech modality by mitigating the modality gap between text and speech. Our novelty architecture, GroupFormer, can reduce speech sequences to lengths comparable to text sequences while generating high-quality audio, significantly reducing the length difference between speech and text, speeding up inference, and alleviating long-text modeling issues. Additionally, we construct a multi-turn speech-to-speech dialogue dataset named \method-500k which includes nearly 500k turns of speech-to-speech dialogues, and a cross-modality training strategy to enhance the semantic alignment between speech and text. Experimental results demonstrate that IntrinsicVoice can generate high-quality speech response with latency lower than 100ms in multi-turn dialogue scenarios. Demos are available at https://instrinsicvoice.github.io/.
PP-MeT: a Real-world Personalized Prompt based Meeting Transcription System
Sep 28, 2023



Speaker-attributed automatic speech recognition (SA-ASR) improves the accuracy and applicability of multi-speaker ASR systems in real-world scenarios by assigning speaker labels to transcribed texts. However, SA-ASR poses unique challenges due to factors such as speaker overlap, speaker variability, background noise, and reverberation. In this study, we propose PP-MeT system, a real-world personalized prompt based meeting transcription system, which consists of a clustering system, target-speaker voice activity detection (TS-VAD), and TS-ASR. Specifically, we utilize target-speaker embedding as a prompt in TS-VAD and TS-ASR modules in our proposed system. In constrast with previous system, we fully leverage pre-trained models for system initialization, thereby bestowing our approach with heightened generalizability and precision. Experiments on M2MeT2.0 Challenge dataset show that our system achieves a cp-CER of 11.27% on the test set, ranking first in both fixed and open training conditions.
Sparse Tensor Graphical Model: Non-convex Optimization and Statistical Inference
Sep 15, 2016
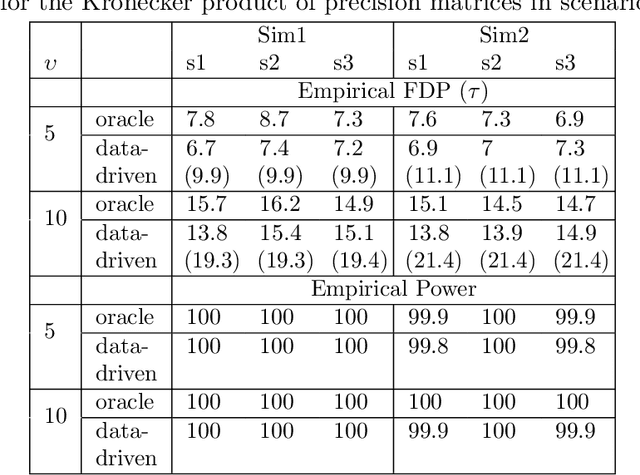
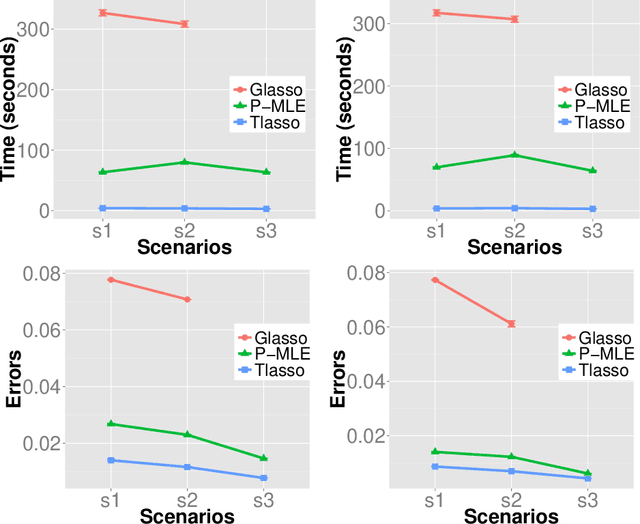
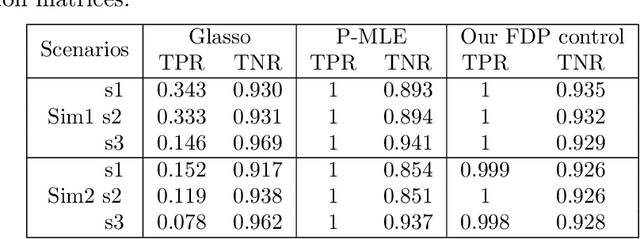
We consider the estimation and inference of sparse graphical models that characterize the dependency structure of high-dimensional tensor-valued data. To facilitate the estimation of the precision matrix corresponding to each way of the tensor, we assume the data follow a tensor normal distribution whose covariance has a Kronecker product structure. A critical challenge in the estimation and inference of this model is the fact that its penalized maximum likelihood estimation involves minimizing a non-convex objective function. To address it, this paper makes two contributions: (i) In spite of the non-convexity of this estimation problem, we prove that an alternating minimization algorithm, which iteratively estimates each sparse precision matrix while fixing the others, attains an estimator with the optimal statistical rate of convergence. Notably, such an estimator achieves estimation consistency with only one tensor sample, which was not observed in the previous work. (ii) We propose a de-biased statistical inference procedure for testing hypotheses on the true support of the sparse precision matrices, and employ it for testing a growing number of hypothesis with false discovery rate (FDR) control. The asymptotic normality of our test statistic and the consistency of FDR control procedure are established. Our theoretical results are further backed up by thorough numerical studies. We implement the methods into a publicly available R package Tlasso.