 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmniFlatten: An End-to-end GPT Model for Seamless Voice Conversation
Oct 23, 2024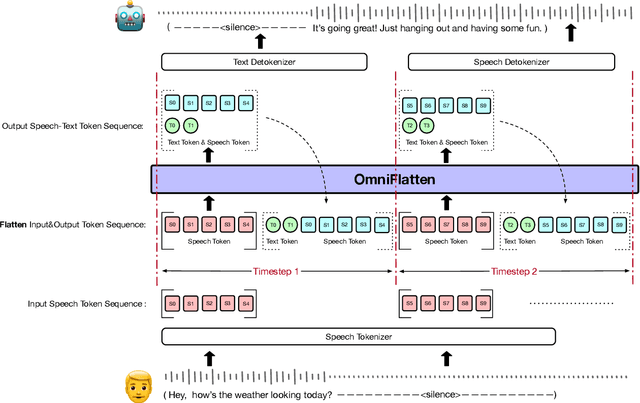
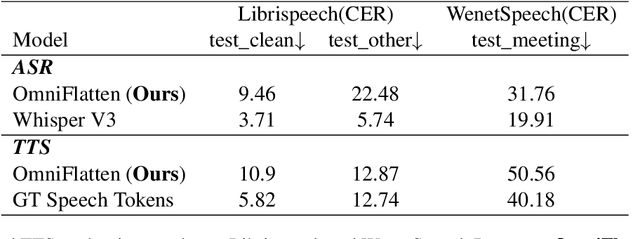
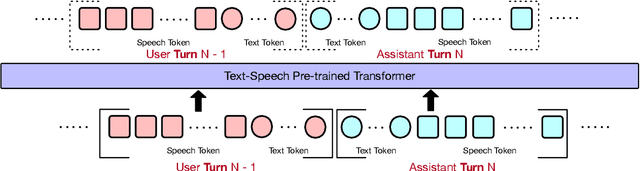
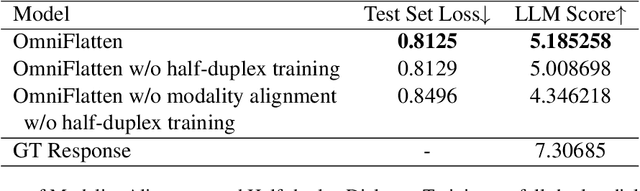
Full-duplex spoken dialogue systems significantly advance over traditional turn-based dialogue systems, as they allow simultaneous bidirectional communication, closely mirroring human-human interactions. However, achieving low latency and natural interactions in full-duplex dialogue systems remains a significant challenge, especially considering human conversation dynamics such as interruptions, backchannels, and overlapping speech. In this paper, we introduce a novel End-to-End GPT-based model OmniFlatten for full-duplex conversation, capable of effectively modeling the complex behaviors inherent to natural conversations with low latency. To achieve full-duplex communication capabilities, we propose a multi-stage post-training scheme that progressively adapts a text-based large language model (LLM) backbone into a speech-text dialogue LLM, capable of generating text and speech in real time, without modifying the architecture of the backbone LLM. The training process comprises three stages: modality alignment, half-duplex dialogue learning, and full-duplex dialogue learning. Throughout all training stages, we standardize the data using a flattening operation, which allows us to unify the training methods and the model architecture across different modalities and tasks. Our approach offers a straightforward modeling technique and a promising research direction for developing efficient and natural end-to-end full-duplex spoken dialogue systems. Audio samples of dialogues generated by OmniFlatten can be found at this web site (https://omniflatten.github.io/).
IntrinsicVoice: Empowering LLMs with Intrinsic Real-time Voice Interaction Abilities
Oct 09, 2024



Current methods of building LLMs with voice interaction capabilities rely heavily on explicit text autoregressive generation before or during speech response generation to maintain content quality, which unfortunately brings computational overhead and increases latency in multi-turn interactions. To address this, we introduce IntrinsicVoic,e an LLM designed with intrinsic real-time voice interaction capabilities. IntrinsicVoice aims to facilitate the transfer of textual capabilities of pre-trained LLMs to the speech modality by mitigating the modality gap between text and speech. Our novelty architecture, GroupFormer, can reduce speech sequences to lengths comparable to text sequences while generating high-quality audio, significantly reducing the length difference between speech and text, speeding up inference, and alleviating long-text modeling issues. Additionally, we construct a multi-turn speech-to-speech dialogue dataset named \method-500k which includes nearly 500k turns of speech-to-speech dialogues, and a cross-modality training strategy to enhance the semantic alignment between speech and text. Experimental results demonstrate that IntrinsicVoice can generate high-quality speech response with latency lower than 100ms in multi-turn dialogue scenarios. Demos are available at https://instrinsicvoice.github.io/.