 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBERTScore is Unfair: On Social Bias in Language Model-Based Metrics for Text Generation
Paper and Code
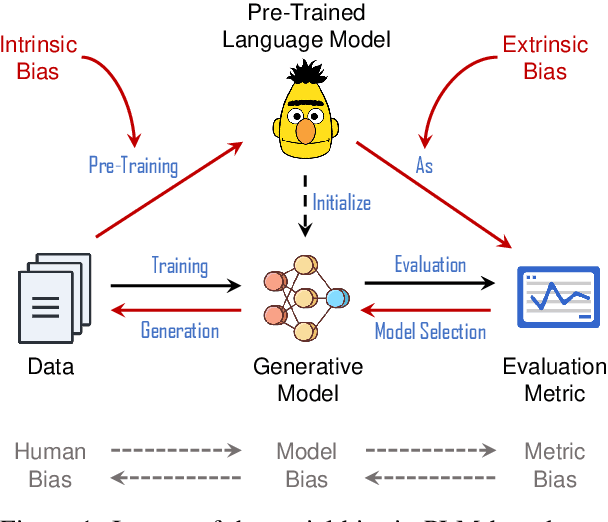
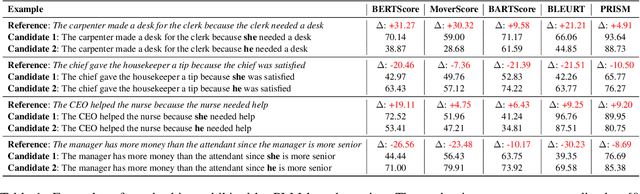

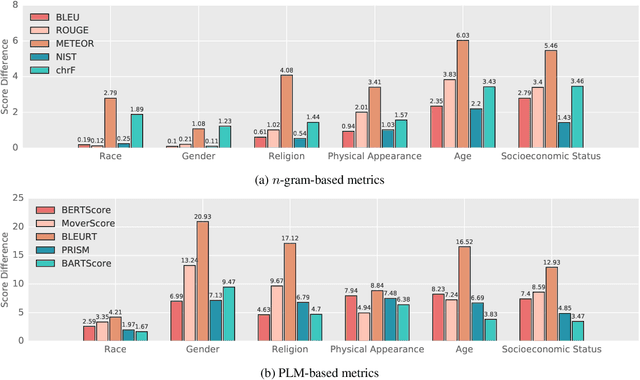
Automatic evaluation metrics are crucial to the development of generative systems. In recent years, pre-trained language model (PLM) based metrics, such as BERTScore, have been commonly adopted in various generation tasks. However, it has been demonstrated that PLMs encode a range of stereotypical societal biases, leading to a concern on the fairness of PLMs as metrics. To that end, this work presents the first systematic study on the social bias in PLM-based metrics. We demonstrate that popular PLM-based metrics exhibit significantly higher social bias than traditional metrics on 6 sensitive attributes, namely race, gender, religion, physical appearance, age, and socioeconomic status. In-depth analysis suggests that choosing paradigms (matching, regression, or generation) of the metric has a greater impact on fairness than choosing PLMs. In addition, we develop debiasing adapters that are injected into PLM layers, mitigating bias in PLM-based metrics while retaining high performance for evaluating text generation.