 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFedGSM: Efficient Federated Learning for LEO Constellations with Gradient Staleness Mitigation
Apr 17, 2023
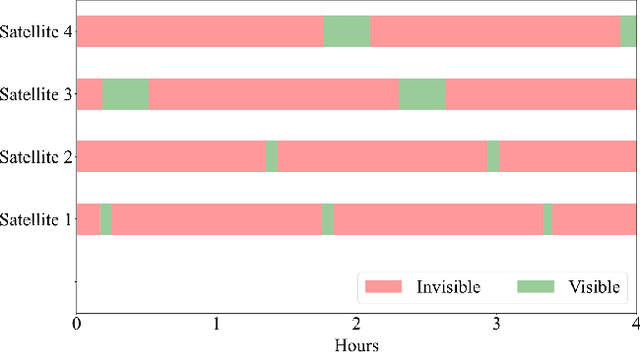


Recent advancements in space technology have equipped low Earth Orbit (LEO) satellites with the capability to perform complex functions and run AI applications. Federated Learning (FL) on LEO satellites enables collaborative training of a global ML model without the need for sharing large datasets. However, intermittent connectivity between satellites and ground stations can lead to stale gradients and unstable learning, thereby limiting learning performance. In this paper, we propose FedGSM, a novel asynchronous FL algorithm that introduces a compensation mechanism to mitigate gradient staleness. FedGSM leverages the deterministic and time-varying topology of the orbits to offset the negative effects of staleness. Our simulation results demonstrate that FedGSM outperforms state-of-the-art algorithms for both IID and non-IID datasets, underscoring its effectiveness and advantages. We also investigate the effect of system parameters.
A Simple Hash-Based Early Exiting Approach For Language Understanding and Generation
Mar 03, 2022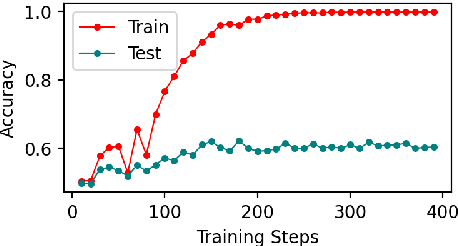
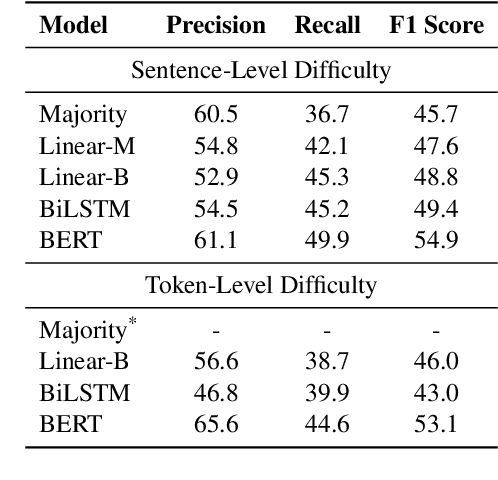
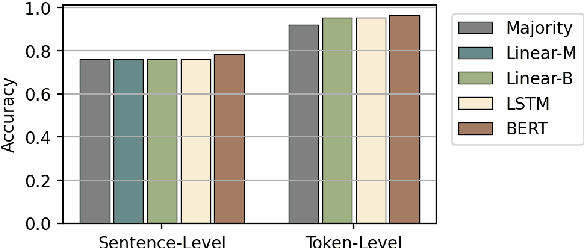
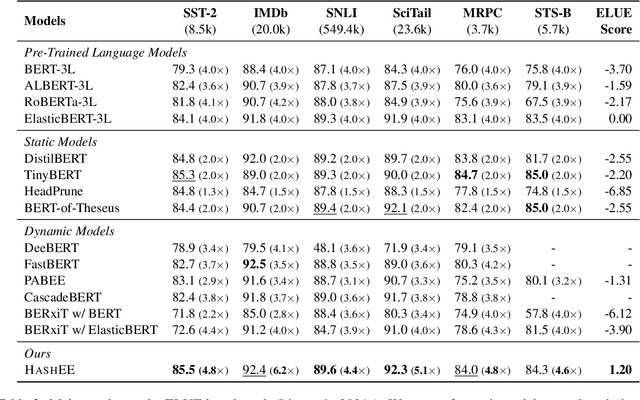
Early exiting allows instances to exit at different layers according to the estimation of difficulty. Previous works usually adopt heuristic metrics such as the entropy of internal outputs to measure instance difficulty, which suffers from generalization and threshold-tuning. In contrast, learning to exit, or learning to predict instance difficulty is a more appealing way. Though some effort has been devoted to employing such "learn-to-exit" modules, it is still unknown whether and how well the instance difficulty can be learned. As a response, we first conduct experiments on the learnability of instance difficulty, which demonstrates that modern neural models perform poorly on predicting instance difficulty. Based on this observation, we propose a simple-yet-effective Hash-based Early Exiting approach (HashEE) that replaces the learn-to-exit modules with hash functions to assign each token to a fixed exiting layer. Different from previous methods, HashEE requires no internal classifiers nor extra parameters, and therefore is more efficient. Experimental results on classification, regression, and generation tasks demonstrate that HashEE can achieve higher performance with fewer FLOPs and inference time compared with previous state-of-the-art early exiting methods.
Towards Efficient NLP: A Standard Evaluation and A Strong Baseline
Oct 13, 2021
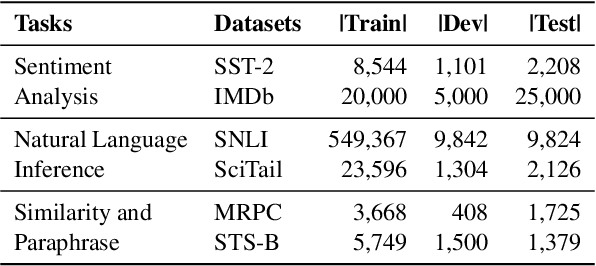
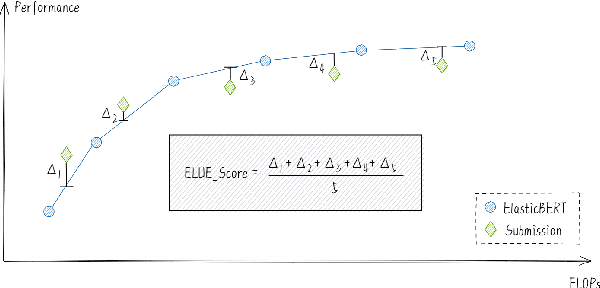
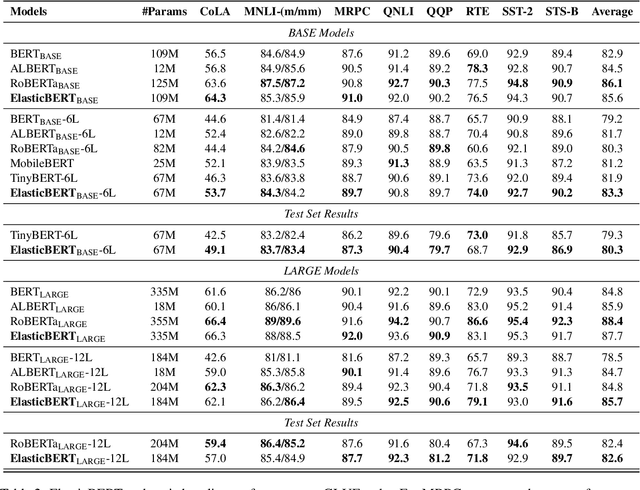
Supersized pre-trained language models have pushed the accuracy of various NLP tasks to a new state-of-the-art (SOTA). Rather than pursuing the reachless SOTA accuracy, most works are pursuing improvement on other dimensions such as efficiency, leading to "Pareto SOTA". Different from accuracy, the metric for efficiency varies across different studies, making them hard to be fairly compared. To that end, this work presents ELUE (Efficient Language Understanding Evaluation), a standard evaluation, and a public leaderboard for efficient NLP models. ELUE is dedicated to depicting the Pareto Front for various language understanding tasks, such that it can tell whether and how much a method achieves Pareto improvement. Along with the benchmark, we also pre-train and release a strong baseline, ElasticBERT, whose elasticity is both static and dynamic. ElasticBERT is static in that it allows reducing model layers on demand. ElasticBERT is dynamic in that it selectively executes parts of model layers conditioned on the input. We demonstrate the ElasticBERT, despite its simplicity, outperforms or performs on par with SOTA compressed and early exiting models. The ELUE benchmark is publicly available at http://eluebenchmark.fastnlp.top/.