 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeForgetting-MarI: LLM Unlearning via Marginal Information Regularization
Nov 14, 2025As AI models are trained on ever-expanding datasets, the ability to remove the influence of specific data from trained models has become essential for privacy protection and regulatory compliance. Unlearning addresses this challenge by selectively removing parametric knowledge from the trained models without retraining from scratch, which is critical for resource-intensive models such as Large Language Models (LLMs). Existing unlearning methods often degrade model performance by removing more information than necessary when attempting to ''forget'' specific data. We introduce Forgetting-MarI, an LLM unlearning framework that provably removes only the additional (marginal) information contributed by the data to be unlearned, while preserving the information supported by the data to be retained. By penalizing marginal information, our method yields an explicit upper bound on the unlearn dataset's residual influence in the trained models, providing provable undetectability. Extensive experiments confirm that our approach outperforms current state-of-the-art unlearning methods, delivering reliable forgetting and better preserved general model performance across diverse benchmarks. This advancement represents an important step toward making AI systems more controllable and compliant with privacy and copyright regulations without compromising their effectiveness.
Detail Across Scales: Multi-Scale Enhancement for Full Spectrum Neural Representations
Sep 19, 2025Implicit neural representations (INRs) have emerged as a compact and parametric alternative to discrete array-based data representations, encoding information directly in neural network weights to enable resolution-independent representation and memory efficiency. However, existing INR approaches, when constrained to compact network sizes, struggle to faithfully represent the multi-scale structures, high-frequency information, and fine textures that characterize the majority of scientific datasets. To address this limitation, we propose WIEN-INR, a wavelet-informed implicit neural representation that distributes modeling across different resolution scales and employs a specialized kernel network at the finest scale to recover subtle details. This multi-scale architecture allows for the use of smaller networks to retain the full spectrum of information while preserving the training efficiency and reducing storage cost. Through extensive experiments on diverse scientific datasets spanning different scales and structural complexities, WIEN-INR achieves superior reconstruction fidelity while maintaining a compact model size. These results demonstrate WIEN-INR as a practical neural representation framework for high-fidelity scientific data encoding, extending the applicability of INRs to domains where efficient preservation of fine detail is essential.
ZALM3: Zero-Shot Enhancement of Vision-Language Alignment via In-Context Information in Multi-Turn Multimodal Medical Dialogue
Sep 26, 2024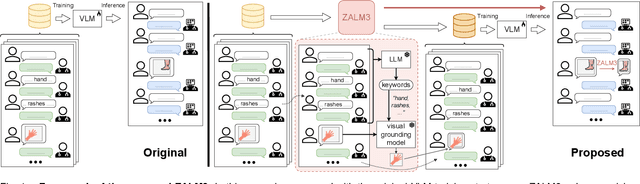
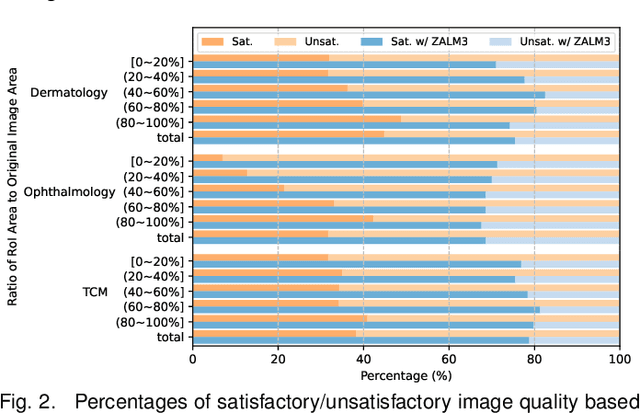
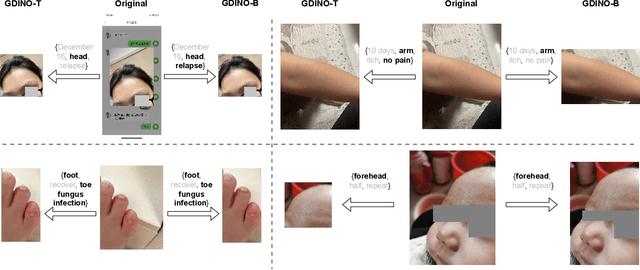
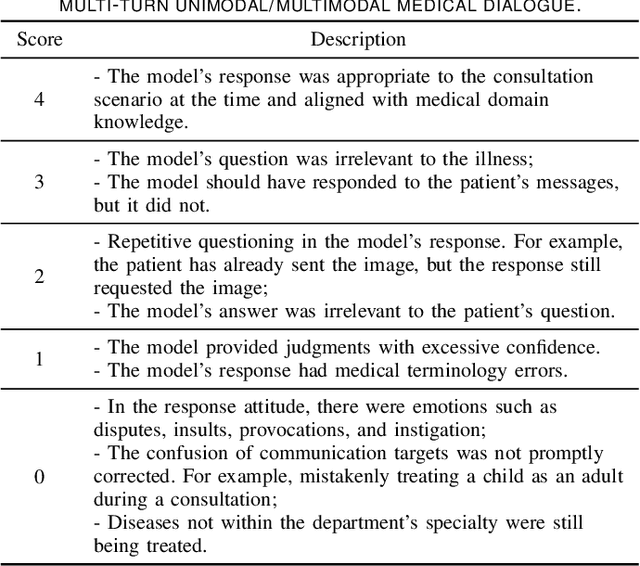
The rocketing prosperity of large language models (LLMs) in recent years has boosted the prevalence of vision-language models (VLMs) in the medical sector. In our online medical consultation scenario, a doctor responds to the texts and images provided by a patient in multiple rounds to diagnose her/his health condition, forming a multi-turn multimodal medical dialogue format. Unlike high-quality images captured by professional equipment in traditional medical visual question answering (Med-VQA), the images in our case are taken by patients' mobile phones. These images have poor quality control, with issues such as excessive background elements and the lesion area being significantly off-center, leading to degradation of vision-language alignment in the model training phase. In this paper, we propose ZALM3, a Zero-shot strategy to improve vision-language ALignment in Multi-turn Multimodal Medical dialogue. Since we observe that the preceding text conversations before an image can infer the regions of interest (RoIs) in the image, ZALM3 employs an LLM to summarize the keywords from the preceding context and a visual grounding model to extract the RoIs. The updated images eliminate unnecessary background noise and provide more effective vision-language alignment. To better evaluate our proposed method, we design a new subjective assessment metric for multi-turn unimodal/multimodal medical dialogue to provide a fine-grained performance comparison. Our experiments across three different clinical departments remarkably demonstrate the efficacy of ZALM3 with statistical significance.
IAPT: Instruction-Aware Prompt Tuning for Large Language Models
May 28, 2024



Soft prompt tuning is a widely studied parameter-efficient fine-tuning method. However, it has a clear drawback: many soft tokens must be inserted into the input sequences to guarantee downstream performance. As a result, soft prompt tuning is less considered than Low-rank adaptation (LoRA) in the large language modeling (LLM) era. In this work, we propose a novel prompt tuning method, Instruction-Aware Prompt Tuning (IAPT), that requires only four soft tokens. First, we install a parameter-efficient soft prompt generator at each Transformer layer to generate idiosyncratic soft prompts for each input instruction. The generated soft prompts can be seen as a semantic summary of the input instructions and can effectively guide the output generation. Second, the soft prompt generators are modules with a bottleneck architecture consisting of a self-attention pooling operation, two linear projections, and an activation function. Pilot experiments show that prompt generators at different Transformer layers require different activation functions. Thus, we propose to learn the idiosyncratic activation functions for prompt generators automatically with the help of rational functions. We have conducted experiments on various tasks, and the experimental results demonstrate that (a) our IAPT method can outperform the recent baselines with comparable tunable parameters. (b) Our IAPT method is more efficient than LoRA under the single-backbone multi-tenant setting.
Text2MDT: Extracting Medical Decision Trees from Medical Texts
Jan 04, 2024



Knowledge of the medical decision process, which can be modeled as medical decision trees (MDTs), is critical to build clinical decision support systems. However, the current MDT construction methods rely heavily on time-consuming and laborious manual annotation. In this work, we propose a novel task, Text2MDT, to explore the automatic extraction of MDTs from medical texts such as medical guidelines and textbooks. We normalize the form of the MDT and create an annotated Text-to-MDT dataset in Chinese with the participation of medical experts. We investigate two different methods for the Text2MDT tasks: (a) an end-to-end framework which only relies on a GPT style large language models (LLM) instruction tuning to generate all the node information and tree structures. (b) The pipeline framework which decomposes the Text2MDT task to three subtasks. Experiments on our Text2MDT dataset demonstrate that: (a) the end-to-end method basd on LLMs (7B parameters or larger) show promising results, and successfully outperform the pipeline methods. (b) The chain-of-thought (COT) prompting method \cite{Wei2022ChainOT} can improve the performance of the fine-tuned LLMs on the Text2MDT test set. (c) the lightweight pipelined method based on encoder-based pretrained models can perform comparably with LLMs with model complexity two magnititudes smaller. Our Text2MDT dataset is open-sourced at \url{https://tianchi.aliyun.com/dataset/95414}, and the source codes are open-sourced at \url{https://github.com/michael-wzhu/text2dt}.
UltraFeedback: Boosting Language Models with High-quality Feedback
Oct 02, 2023



Reinforcement learning from human feedback (RLHF) has become a pivot technique in aligning large language models (LLMs) with human preferences. In RLHF practice, preference data plays a crucial role in bridging human proclivity and LLMs. However, the scarcity of diverse, naturalistic datasets of human preferences on LLM outputs at scale poses a great challenge to RLHF as well as feedback learning research within the open-source community. Current preference datasets, either proprietary or limited in size and prompt variety, result in limited RLHF adoption in open-source models and hinder further exploration. In this study, we propose ULTRAFEEDBACK, a large-scale, high-quality, and diversified preference dataset designed to overcome these limitations and foster RLHF development. To create ULTRAFEEDBACK, we compile a diverse array of instructions and models from multiple sources to produce comparative data. We meticulously devise annotation instructions and employ GPT-4 to offer detailed feedback in both numerical and textual forms. ULTRAFEEDBACK establishes a reproducible and expandable preference data construction pipeline, serving as a solid foundation for future RLHF and feedback learning research. Utilizing ULTRAFEEDBACK, we train various models to demonstrate its effectiveness, including the reward model UltraRM, chat language model UltraLM-13B-PPO, and critique model UltraCM. Experimental results indicate that our models outperform existing open-source models, achieving top performance across multiple benchmarks. Our data and models are available at https://github.com/thunlp/UltraFeedback.
Unified Demonstration Retriever for In-Context Learning
May 16, 2023



In-context learning is a new learning paradigm where a language model conditions on a few input-output pairs (demonstrations) and a test input, and directly outputs the prediction. It has been shown highly dependent on the provided demonstrations and thus promotes the research of demonstration retrieval: given a test input, relevant examples are retrieved from the training set to serve as informative demonstrations for in-context learning. While previous works focus on training task-specific retrievers for several tasks separately, these methods are often hard to transfer and scale on various tasks, and separately trained retrievers incur a lot of parameter storage and deployment cost. In this paper, we propose Unified Demonstration Retriever (\textbf{UDR}), a single model to retrieve demonstrations for a wide range of tasks. To train UDR, we cast various tasks' training signals into a unified list-wise ranking formulation by language model's feedback. Then we propose a multi-task list-wise ranking training framework, with an iterative mining strategy to find high-quality candidates, which can help UDR fully incorporate various tasks' signals. Experiments on 30+ tasks across 13 task families and multiple data domains show that UDR significantly outperforms baselines. Further analyses show the effectiveness of each proposed component and UDR's strong ability in various scenarios including different LMs (1.3B - 175B), unseen datasets, varying demonstration quantities, etc.
A Simple Hash-Based Early Exiting Approach For Language Understanding and Generation
Mar 03, 2022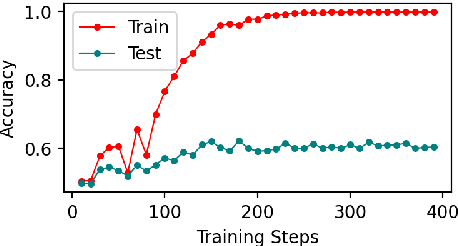
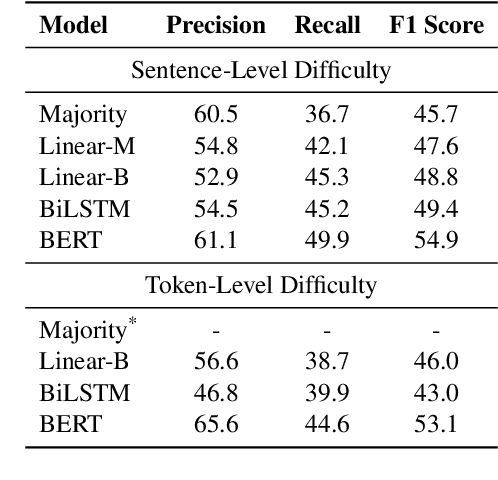
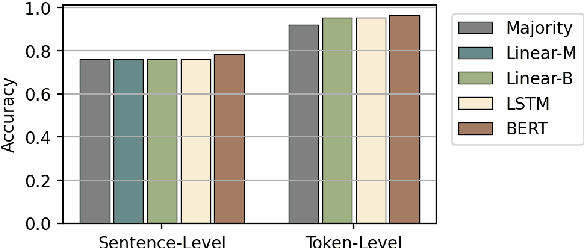
Early exiting allows instances to exit at different layers according to the estimation of difficulty. Previous works usually adopt heuristic metrics such as the entropy of internal outputs to measure instance difficulty, which suffers from generalization and threshold-tuning. In contrast, learning to exit, or learning to predict instance difficulty is a more appealing way. Though some effort has been devoted to employing such "learn-to-exit" modules, it is still unknown whether and how well the instance difficulty can be learned. As a response, we first conduct experiments on the learnability of instance difficulty, which demonstrates that modern neural models perform poorly on predicting instance difficulty. Based on this observation, we propose a simple-yet-effective Hash-based Early Exiting approach (HashEE) that replaces the learn-to-exit modules with hash functions to assign each token to a fixed exiting layer. Different from previous methods, HashEE requires no internal classifiers nor extra parameters, and therefore is more efficient. Experimental results on classification, regression, and generation tasks demonstrate that HashEE can achieve higher performance with fewer FLOPs and inference time compared with previous state-of-the-art early exiting methods.
CBLUE: A Chinese Biomedical Language Understanding Evaluation Benchmark
Jul 06, 2021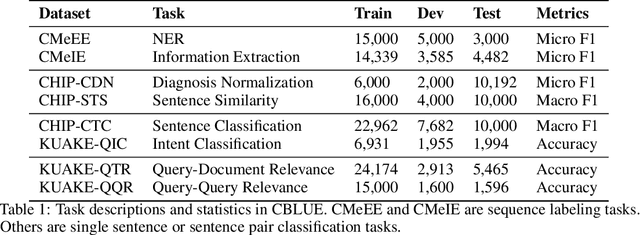
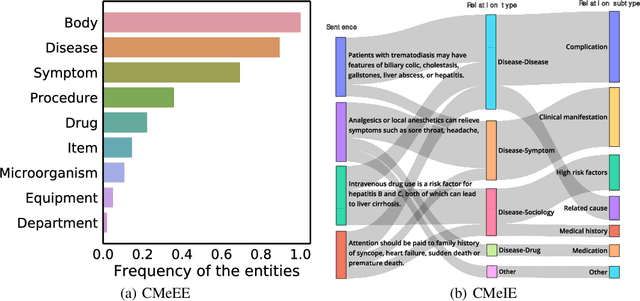
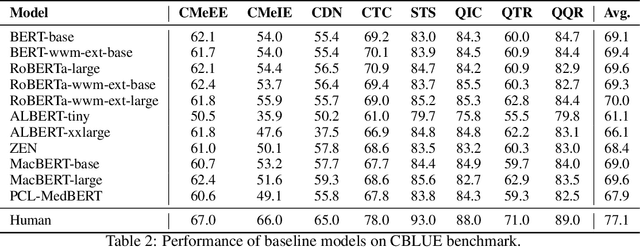
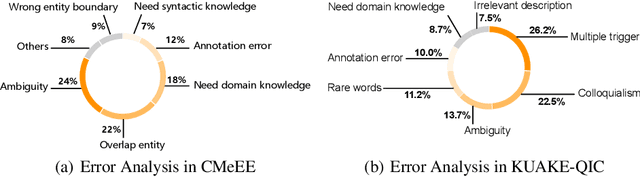
Artificial Intelligence (AI), along with the recent progress in biomedical language understanding, is gradually changing medical practice. With the development of biomedical language understanding benchmarks, AI applications are widely used in the medical field. However, most benchmarks are limited to English, which makes it challenging to replicate many of the successes in English for other languages. To facilitate research in this direction, we collect real-world biomedical data and present the first Chinese Biomedical Language Understanding Evaluation (CBLUE) benchmark: a collection of natural language understanding tasks including named entity recognition, information extraction, clinical diagnosis normalization, single-sentence/sentence-pair classification, and an associated online platform for model evaluation, comparison, and analysis. To establish evaluation on these tasks, we report empirical results with the current 11 pre-trained Chinese models, and experimental results show that state-of-the-art neural models perform by far worse than the human ceiling. Our benchmark is released at \url{https://tianchi.aliyun.com/dataset/dataDetail?dataId=95414&lang=en-us}.
AutoRC: Improving BERT Based Relation Classification Models via Architecture Search
Sep 27, 2020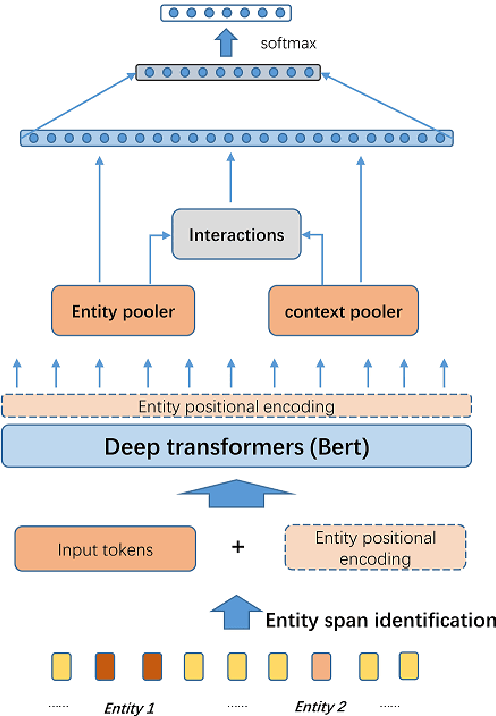
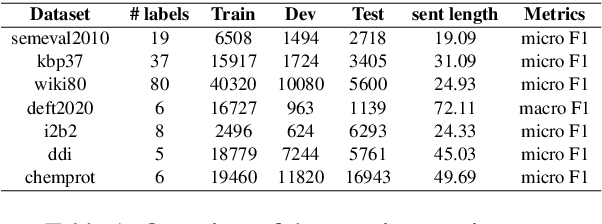
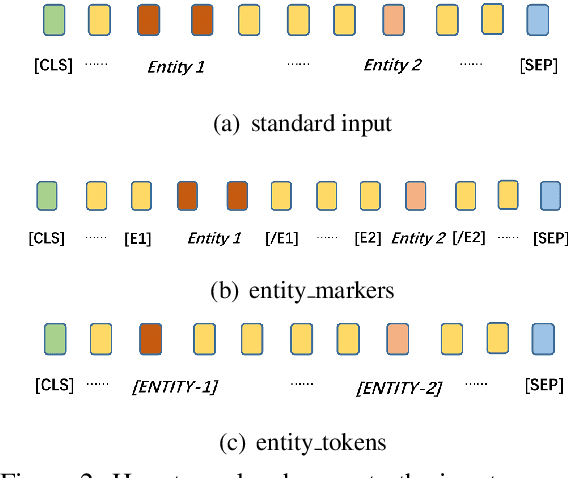

Although BERT based relation classification (RC) models have achieved significant improvements over the traditional deep learning models, it seems that no consensus can be reached on what is the optimal architecture. Firstly, there are multiple alternatives for entity span identification. Second, there are a collection of pooling operations to aggregate the representations of entities and contexts into fixed length vectors. Third, it is difficult to manually decide which feature vectors, including their interactions, are beneficial for classifying the relation types. In this work, we design a comprehensive search space for BERT based RC models and employ neural architecture search (NAS) method to automatically discover the design choices mentioned above. Experiments on seven benchmark RC tasks show that our method is efficient and effective in finding better architectures than the baseline BERT based RC model. Ablation study demonstrates the necessity of our search space design and the effectiveness of our search method.