 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring $\ell_0$ Sparsification for Inference-free Sparse Retrievers
Apr 21, 2025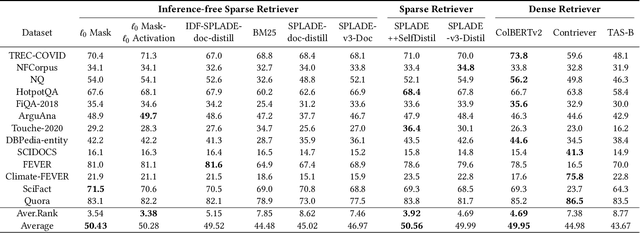
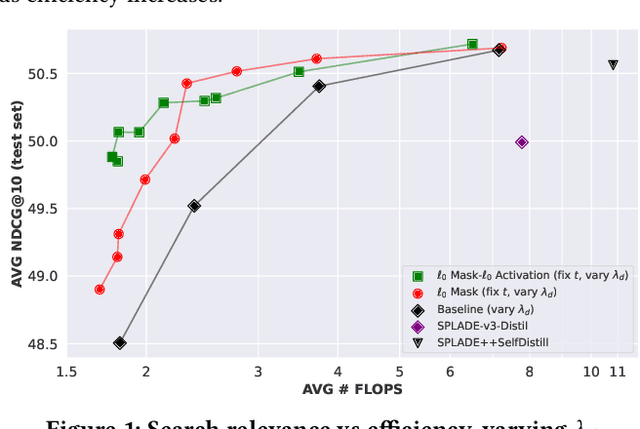
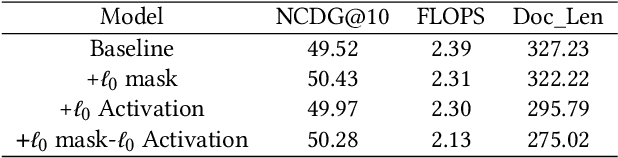
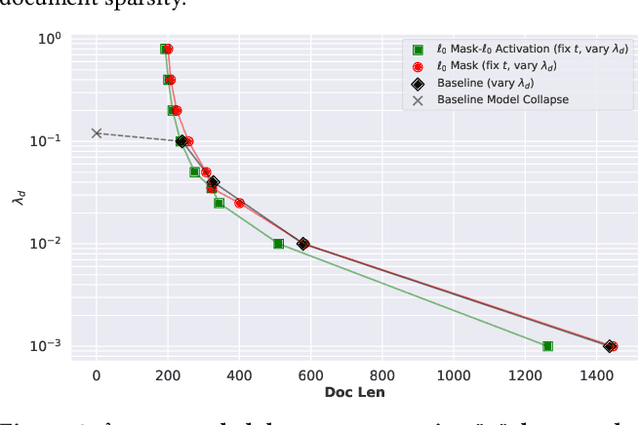
With increasing demands for efficiency, information retrieval has developed a branch of sparse retrieval, further advancing towards inference-free retrieval where the documents are encoded during indexing time and there is no model-inference for queries. Existing sparse retrieval models rely on FLOPS regularization for sparsification, while this mechanism was originally designed for Siamese encoders, it is considered to be suboptimal in inference-free scenarios which is asymmetric. Previous attempts to adapt FLOPS for inference-free scenarios have been limited to rule-based methods, leaving the potential of sparsification approaches for inference-free retrieval models largely unexplored. In this paper, we explore $\ell_0$ inspired sparsification manner for inference-free retrievers. Through comprehensive out-of-domain evaluation on the BEIR benchmark, our method achieves state-of-the-art performance among inference-free sparse retrieval models and is comparable to leading Siamese sparse retrieval models. Furthermore, we provide insights into the trade-off between retrieval effectiveness and computational efficiency, demonstrating practical value for real-world applications.
Towards Competitive Search Relevance For Inference-Free Learned Sparse Retrievers
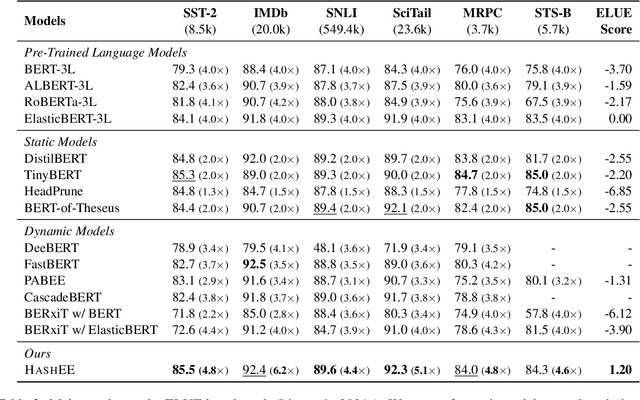
Nov 07, 2024Learned sparse retrieval, which can efficiently perform retrieval through mature inverted-index engines, has garnered growing attention in recent years. Particularly, the inference-free sparse retrievers are attractive as they eliminate online model inference in the retrieval phase thereby avoids huge computational cost, offering reasonable throughput and latency. However, even the state-of-the-art (SOTA) inference-free sparse models lag far behind in terms of search relevance when compared to both sparse and dense siamese models. Towards competitive search relevance for inference-free sparse retrievers, we argue that they deserve dedicated training methods other than using same ones with siamese encoders. In this paper, we propose two different approaches for performance improvement. First, we introduce the IDF-aware FLOPS loss, which introduces Inverted Document Frequency (IDF) to the sparsification of representations. We find that it mitigates the negative impact of the FLOPS regularization on search relevance, allowing the model to achieve a better balance between accuracy and efficiency. Moreover, we propose a heterogeneous ensemble knowledge distillation framework that combines siamese dense and sparse retrievers to generate supervisory signals during the pre-training phase. The ensemble framework of dense and sparse retriever capitalizes on their strengths respectively, providing a strong upper bound for knowledge distillation. To concur the diverse feedback from heterogeneous supervisors, we normalize and then aggregate the outputs of the teacher models to eliminate score scale differences. On the BEIR benchmark, our model outperforms existing SOTA inference-free sparse model by \textbf{3.3 NDCG@10 score}. It exhibits search relevance comparable to siamese sparse retrievers and client-side latency only \textbf{1.1x that of BM25}.
A Simple Hash-Based Early Exiting Approach For Language Understanding and Generation
Mar 03, 2022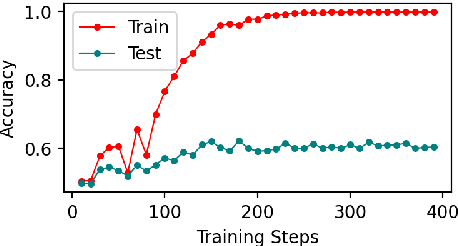
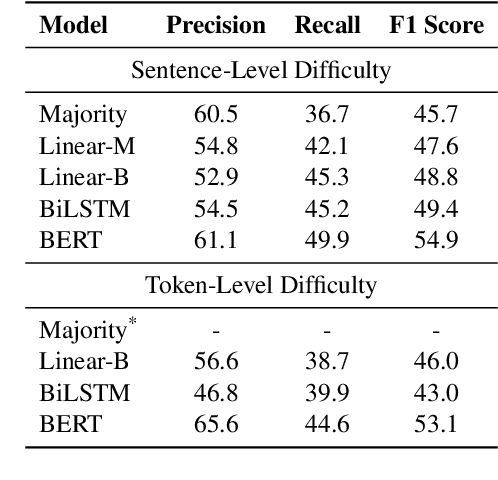
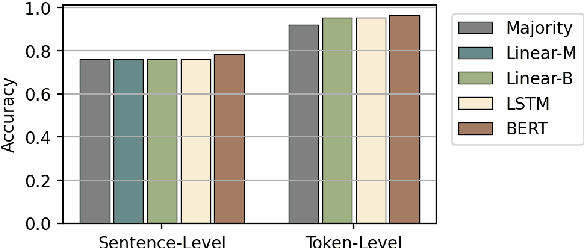
Early exiting allows instances to exit at different layers according to the estimation of difficulty. Previous works usually adopt heuristic metrics such as the entropy of internal outputs to measure instance difficulty, which suffers from generalization and threshold-tuning. In contrast, learning to exit, or learning to predict instance difficulty is a more appealing way. Though some effort has been devoted to employing such "learn-to-exit" modules, it is still unknown whether and how well the instance difficulty can be learned. As a response, we first conduct experiments on the learnability of instance difficulty, which demonstrates that modern neural models perform poorly on predicting instance difficulty. Based on this observation, we propose a simple-yet-effective Hash-based Early Exiting approach (HashEE) that replaces the learn-to-exit modules with hash functions to assign each token to a fixed exiting layer. Different from previous methods, HashEE requires no internal classifiers nor extra parameters, and therefore is more efficient. Experimental results on classification, regression, and generation tasks demonstrate that HashEE can achieve higher performance with fewer FLOPs and inference time compared with previous state-of-the-art early exiting methods.
TURNER: The Uncertainty-based Retrieval Framework for Chinese NER
Feb 18, 2022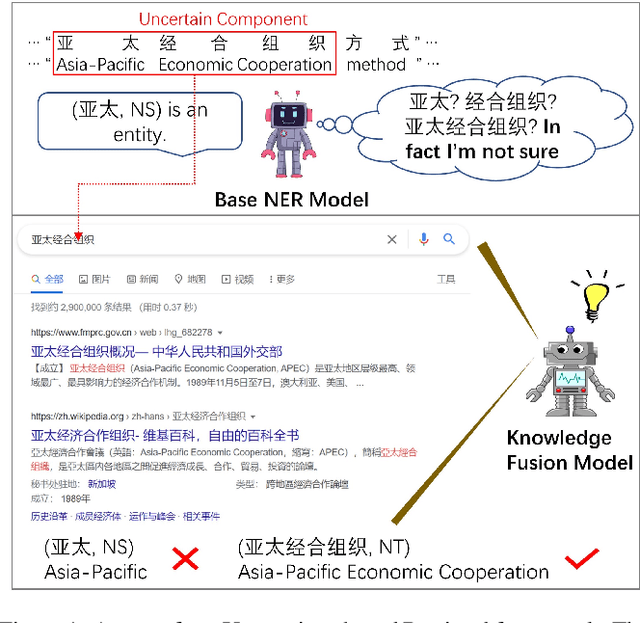


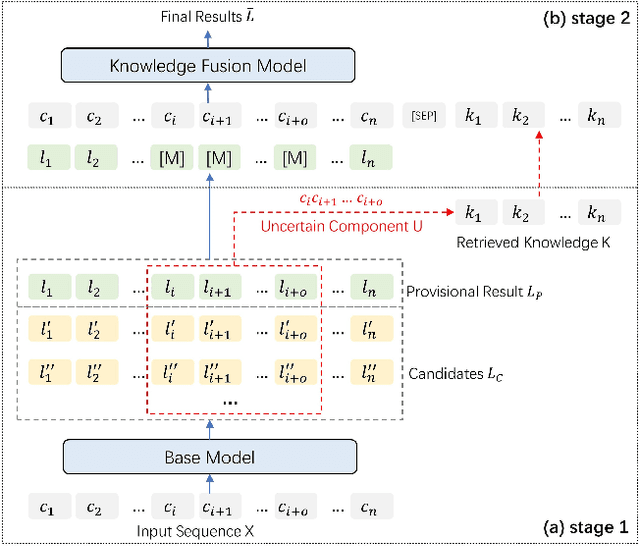
Chinese NER is a difficult undertaking due to the ambiguity of Chinese characters and the absence of word boundaries. Previous work on Chinese NER focus on lexicon-based methods to introduce boundary information and reduce out-of-vocabulary (OOV) cases during prediction. However, it is expensive to obtain and dynamically maintain high-quality lexicons in specific domains, which motivates us to utilize more general knowledge resources, e.g., search engines. In this paper, we propose TURNER: The Uncertainty-based Retrieval framework for Chinese NER. The idea behind TURNER is to imitate human behavior: we frequently retrieve auxiliary knowledge as assistance when encountering an unknown or uncertain entity. To improve the efficiency and effectiveness of retrieval, we first propose two types of uncertainty sampling methods for selecting the most ambiguous entity-level uncertain components of the input text. Then, the Knowledge Fusion Model re-predict the uncertain samples by combining retrieved knowledge. Experiments on four benchmark datasets demonstrate TURNER's effectiveness. TURNER outperforms existing lexicon-based approaches and achieves the new SOTA.
RetrievalSum: A Retrieval Enhanced Framework for Abstractive Summarization
Sep 16, 2021
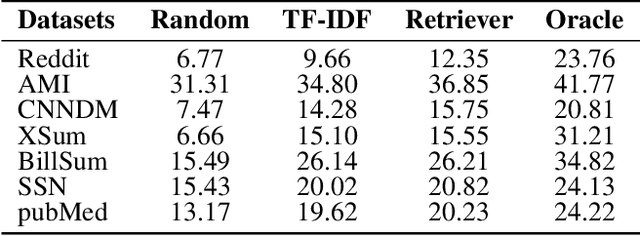
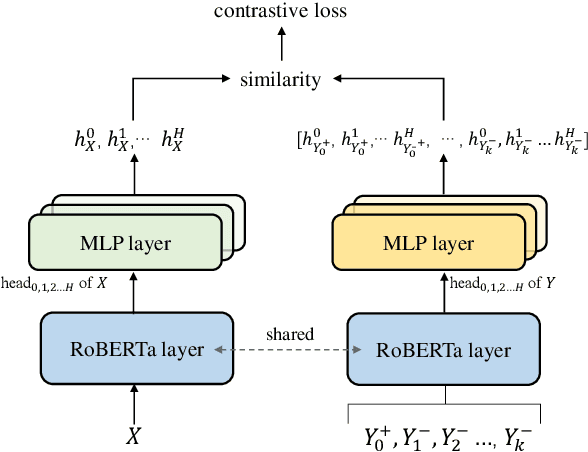
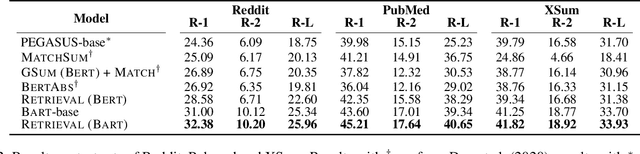
Existing summarization systems mostly generate summaries purely relying on the content of the source document. However, even for humans, we usually need some references or exemplars to help us fully understand the source document and write summaries in a particular format. But how to find the high-quality exemplars and incorporate them into summarization systems is still challenging and worth exploring. In this paper, we propose RetrievalSum, a novel retrieval enhanced abstractive summarization framework consisting of a dense Retriever and a Summarizer. At first, several closely related exemplars are retrieved as supplementary input to help the generation model understand the text more comprehensively. Furthermore, retrieved exemplars can also play a role in guiding the model to capture the writing style of a specific corpus. We validate our method on a wide range of summarization datasets across multiple domains and two backbone models: BERT and BART. Results show that our framework obtains significant improvement by 1.38~4.66 in ROUGE-1 score when compared with the powerful pre-trained models, and achieve new state-of-the-art on BillSum. Human evaluation demonstrates that our retrieval enhanced model can better capture the domain-specific writing style.
CPT: A Pre-Trained Unbalanced Transformer for Both Chinese Language Understanding and Generation
Sep 14, 2021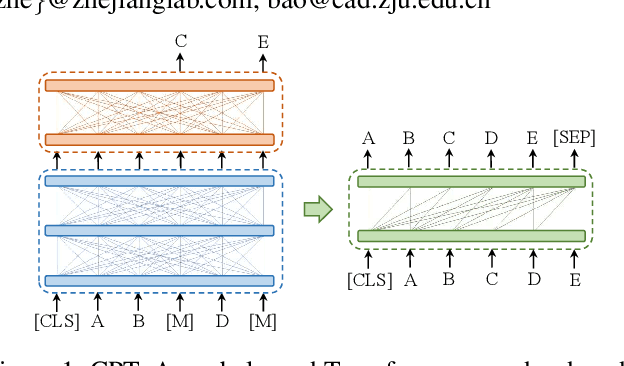
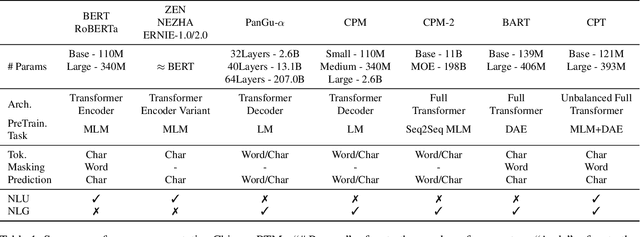
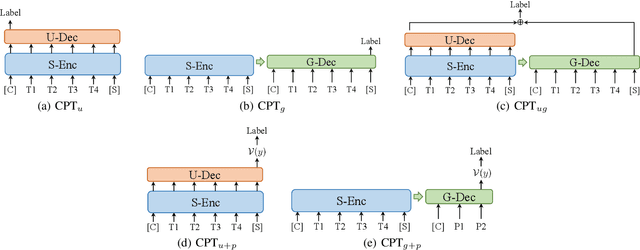
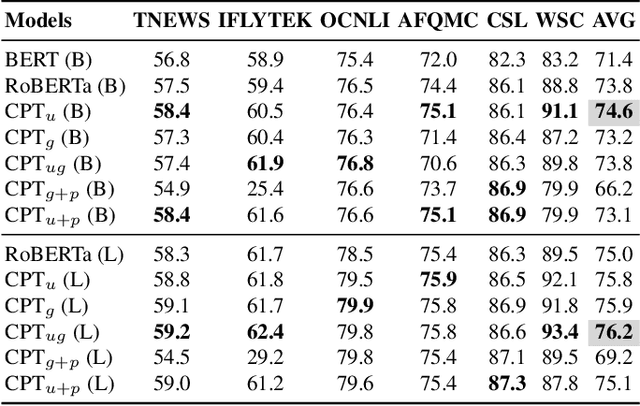
In this paper, we take the advantage of previous pre-trained models (PTMs) and propose a novel Chinese Pre-trained Unbalanced Transformer (CPT). Different from previous Chinese PTMs, CPT is designed for both natural language understanding (NLU) and natural language generation (NLG) tasks. CPT consists of three parts: a shared encoder, an understanding decoder, and a generation decoder. Two specific decoders with a shared encoder are pre-trained with masked language modeling (MLM) and denoising auto-encoding (DAE) tasks, respectively. With the partially shared architecture and multi-task pre-training, CPT can (1) learn specific knowledge of both NLU or NLG tasks with two decoders and (2) be fine-tuned flexibly that fully exploits the potential of the model. Moreover, the unbalanced Transformer saves the computational and storage cost, which makes CPT competitive and greatly accelerates the inference of text generation. Experimental results on a wide range of Chinese NLU and NLG tasks show the effectiveness of CPT.
fastHan: A BERT-based Joint Many-Task Toolkit for Chinese NLP
Sep 18, 2020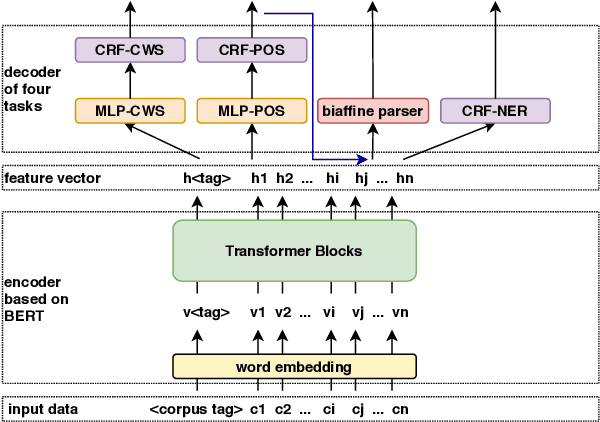
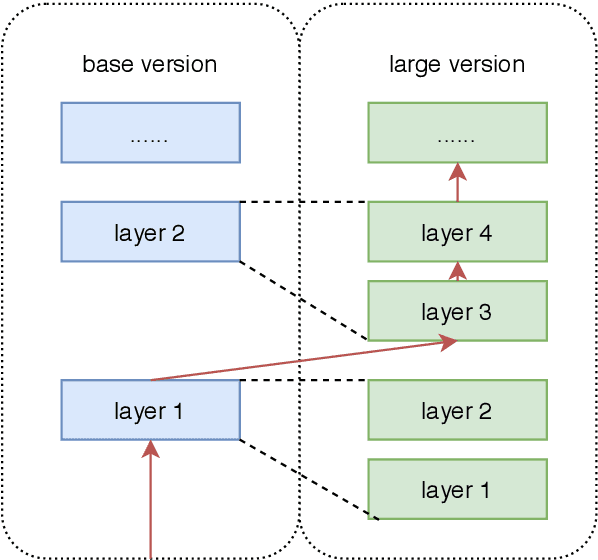
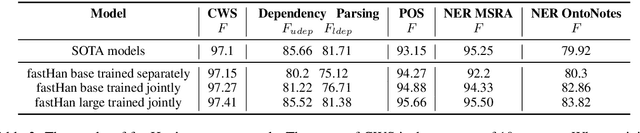
We present fastHan, an open-source toolkit for four basic tasks in Chinese natural language processing: Chinese word segmentation, Part-of-Speech tagging, named entity recognition, and dependency parsing. The kernel of fastHan is a joint many-task model based on a pruned BERT, which uses the first 8 layers in BERT. We also provide a 4-layer base version of model compressed from the 8-layer model. The joint-model is trained and evaluated in 13 corpora of four tasks, yielding near state-of-the-art (SOTA) performance in the dependency parsing task and SOTA performance in the other three tasks. In addition to its small size and excellent performance, fastHan is also very user-friendly. Implemented as a python package, fastHan allows users to easily download and use it. Users can get what they want with one line of code, even if they have little knowledge of deep learning. The project is released on Github.