 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCPT: A Pre-Trained Unbalanced Transformer for Both Chinese Language Understanding and Generation
Sep 14, 2021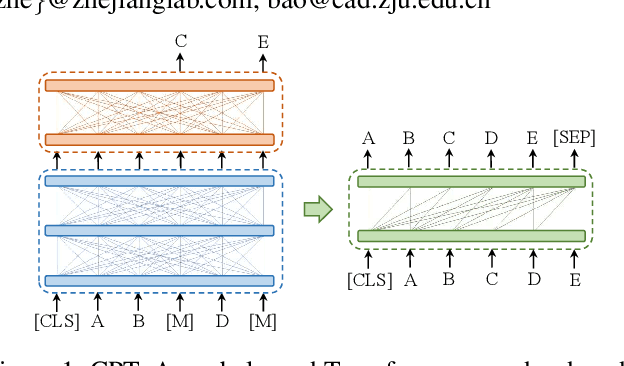
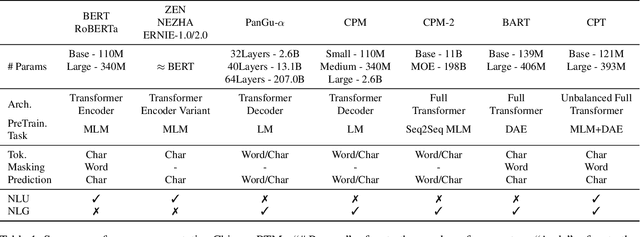
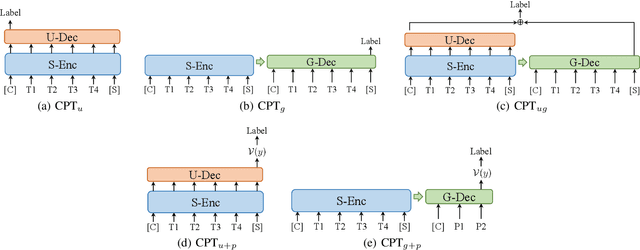
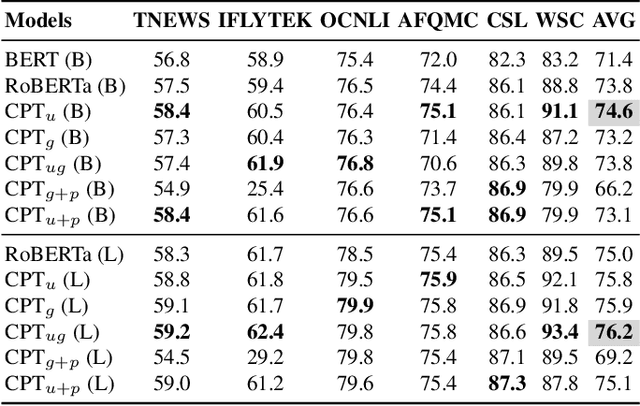
In this paper, we take the advantage of previous pre-trained models (PTMs) and propose a novel Chinese Pre-trained Unbalanced Transformer (CPT). Different from previous Chinese PTMs, CPT is designed for both natural language understanding (NLU) and natural language generation (NLG) tasks. CPT consists of three parts: a shared encoder, an understanding decoder, and a generation decoder. Two specific decoders with a shared encoder are pre-trained with masked language modeling (MLM) and denoising auto-encoding (DAE) tasks, respectively. With the partially shared architecture and multi-task pre-training, CPT can (1) learn specific knowledge of both NLU or NLG tasks with two decoders and (2) be fine-tuned flexibly that fully exploits the potential of the model. Moreover, the unbalanced Transformer saves the computational and storage cost, which makes CPT competitive and greatly accelerates the inference of text generation. Experimental results on a wide range of Chinese NLU and NLG tasks show the effectiveness of CPT.