 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgefastHan: A BERT-based Joint Many-Task Toolkit for Chinese NLP
Paper and Code
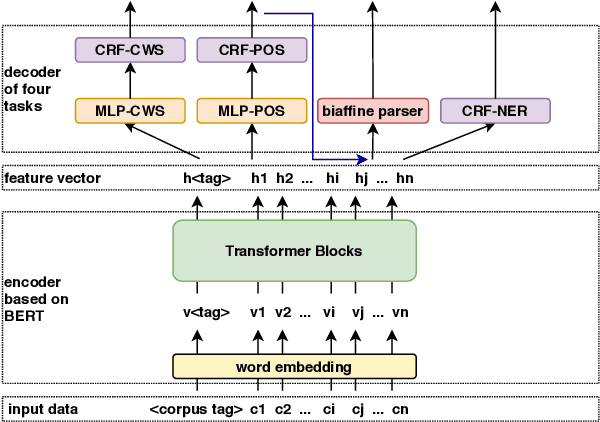
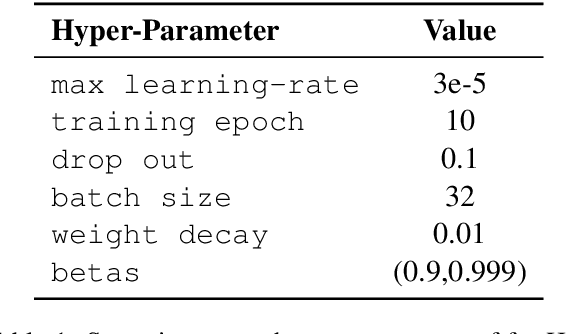
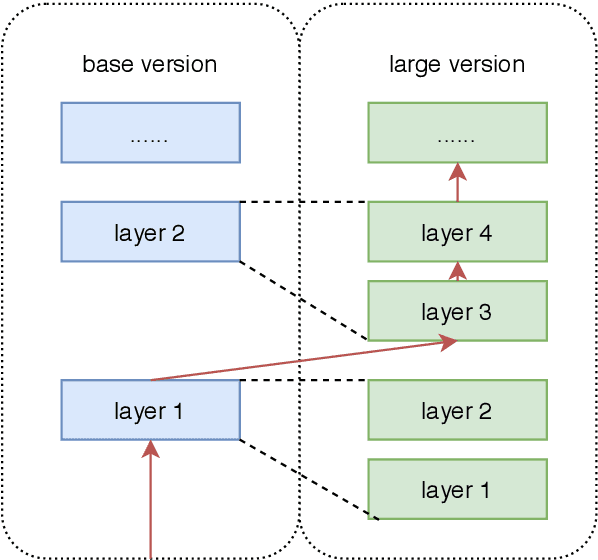
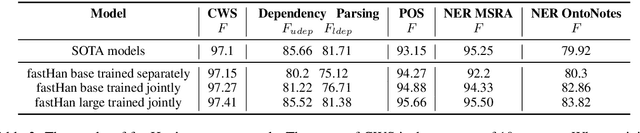
We present fastHan, an open-source toolkit for four basic tasks in Chinese natural language processing: Chinese word segmentation, Part-of-Speech tagging, named entity recognition, and dependency parsing. The kernel of fastHan is a joint many-task model based on a pruned BERT, which uses the first 8 layers in BERT. We also provide a 4-layer base version of model compressed from the 8-layer model. The joint-model is trained and evaluated in 13 corpora of four tasks, yielding near state-of-the-art (SOTA) performance in the dependency parsing task and SOTA performance in the other three tasks. In addition to its small size and excellent performance, fastHan is also very user-friendly. Implemented as a python package, fastHan allows users to easily download and use it. Users can get what they want with one line of code, even if they have little knowledge of deep learning. The project is released on Github.