 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepStruct: Pretraining of Language Models for Structure Prediction
May 21, 2022
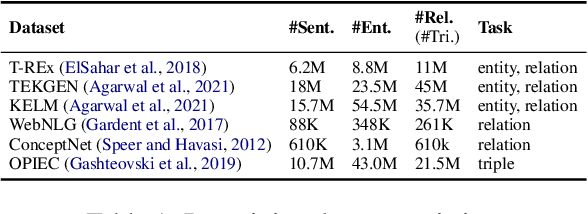

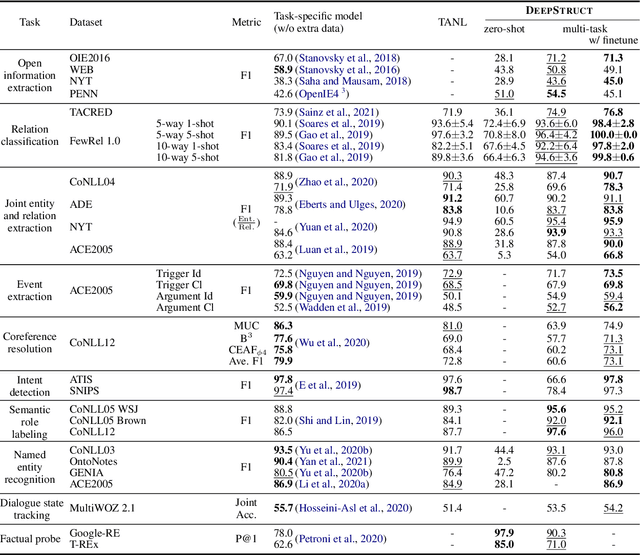
We introduce a method for improving the structural understanding abilities of language models. Unlike previous approaches that finetune the models with task-specific augmentation, we pretrain language models on a collection of task-agnostic corpora to generate structures from text. Our structure pretraining enables zero-shot transfer of the learned knowledge that models have about the structure tasks. We study the performance of this approach on 28 datasets, spanning 10 structure prediction tasks including open information extraction, joint entity and relation extraction, named entity recognition, relation classification, semantic role labeling, event extraction, coreference resolution, factual probe, intent detection, and dialogue state tracking. We further enhance the pretraining with the task-specific training sets. We show that a 10B parameter language model transfers non-trivially to most tasks and obtains state-of-the-art performance on 21 of 28 datasets that we evaluate.
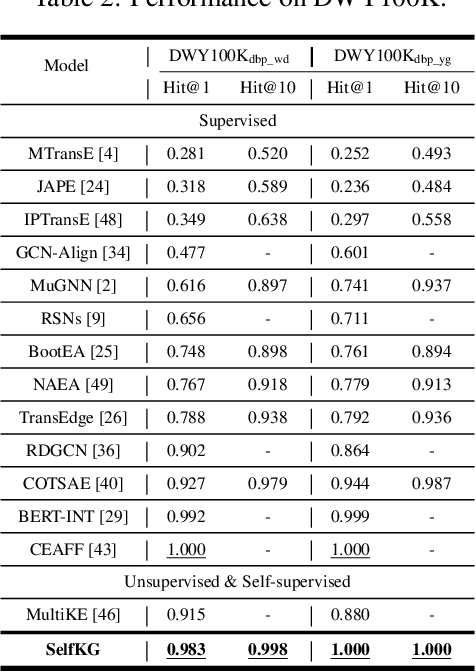
SelfKG: Self-Supervised Entity Alignment in Knowledge Graphs
Mar 02, 2022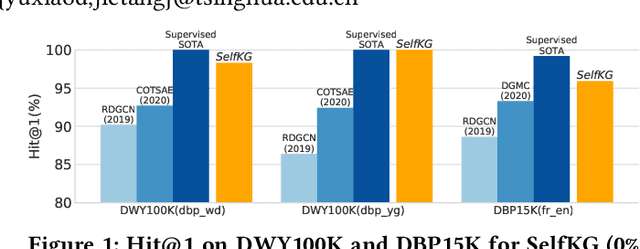
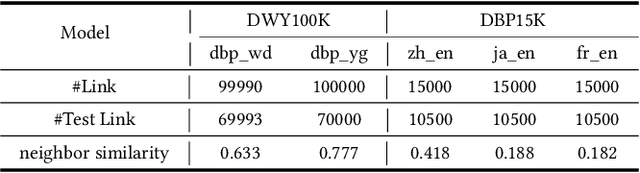
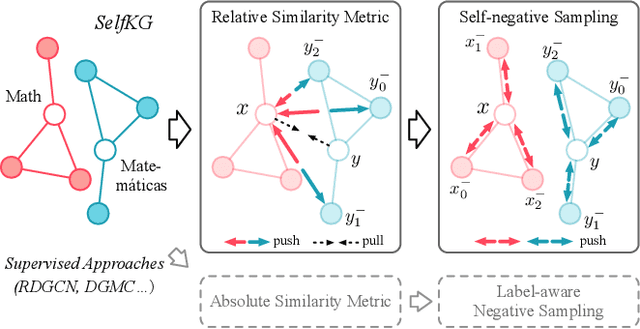
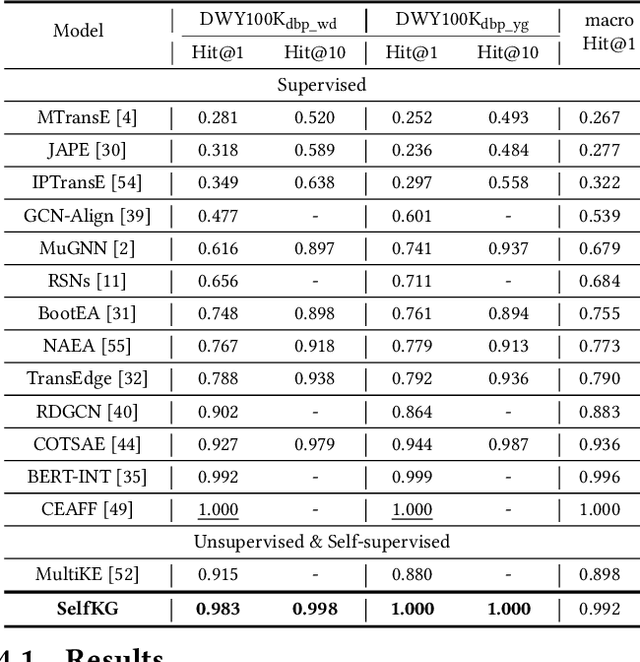
Entity alignment, aiming to identify equivalent entities across different knowledge graphs (KGs), is a fundamental problem for constructing Web-scale KGs. Over the course of its development, the label supervision has been considered necessary for accurate alignments. Inspired by the recent progress of self-supervised learning, we explore the extent to which we can get rid of supervision for entity alignment. Commonly, the label information (positive entity pairs) is used to supervise the process of pulling the aligned entities in each positive pair closer. However, our theoretical analysis suggests that the learning of entity alignment can actually benefit more from pushing unlabeled negative pairs far away from each other than pulling labeled positive pairs close. By leveraging this discovery, we develop the self-supervised learning objective for entity alignment. We present SelfKG with efficient strategies to optimize this objective for aligning entities without label supervision. Extensive experiments on benchmark datasets demonstrate that SelfKG without supervision can match or achieve comparable results with state-of-the-art supervised baselines. The performance of SelfKG suggests that self-supervised learning offers great potential for entity alignment in KGs. The code and data are available at https://github.com/THUDM/SelfKG.
Zero-Shot Information Extraction as a Unified Text-to-Triple Translation
Sep 23, 2021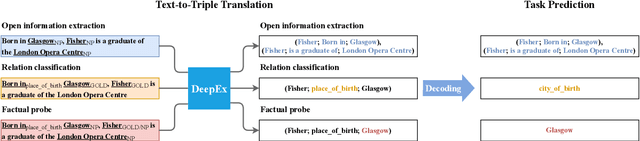
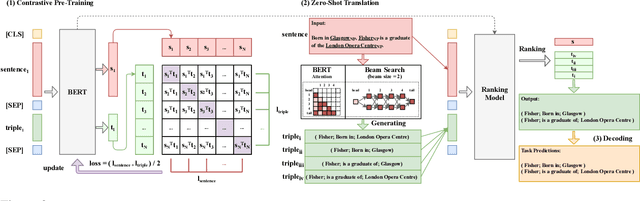

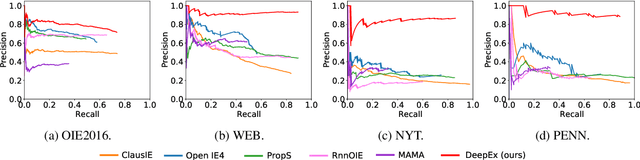
We cast a suite of information extraction tasks into a text-to-triple translation framework. Instead of solving each task relying on task-specific datasets and models, we formalize the task as a translation between task-specific input text and output triples. By taking the task-specific input, we enable a task-agnostic translation by leveraging the latent knowledge that a pre-trained language model has about the task. We further demonstrate that a simple pre-training task of predicting which relational information corresponds to which input text is an effective way to produce task-specific outputs. This enables the zero-shot transfer of our framework to downstream tasks. We study the zero-shot performance of this framework on open information extraction (OIE2016, NYT, WEB, PENN), relation classification (FewRel and TACRED), and factual probe (Google-RE and T-REx). The model transfers non-trivially to most tasks and is often competitive with a fully supervised method without the need for any task-specific training. For instance, we significantly outperform the F1 score of the supervised open information extraction without needing to use its training set.
A Self-supervised Method for Entity Alignment
Jun 17, 2021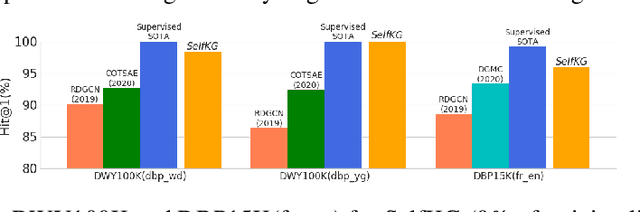
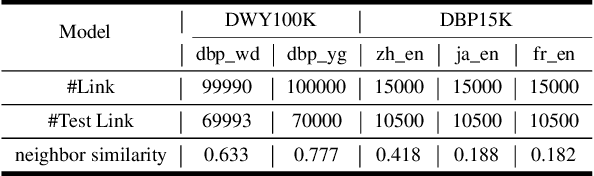
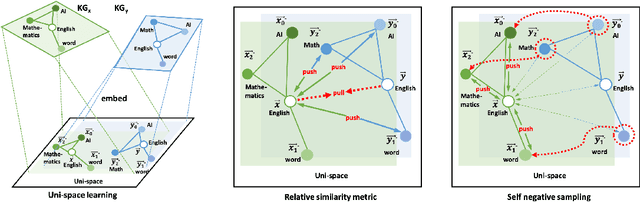
Entity alignment, aiming to identify equivalent entities across different knowledge graphs (KGs), is a fundamental problem for constructing large-scale KGs. Over the course of its development, supervision has been considered necessary for accurate alignments. Inspired by the recent progress of self-supervised learning, we explore the extent to which we can get rid of supervision for entity alignment. Existing supervised methods for this task focus on pulling each pair of positive (labeled) entities close to each other. However, our analysis suggests that the learning of entity alignment can actually benefit more from pushing sampled (unlabeled) negatives far away than pulling positive aligned pairs close. We present SelfKG by leveraging this discovery to design a contrastive learning strategy across two KGs. Extensive experiments on benchmark datasets demonstrate that SelfKG without supervision can match or achieve comparable results with state-of-the-art supervised baselines. The performance of SelfKG demonstrates self-supervised learning offers great potential for entity alignment in KGs.