 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBitStack: Fine-Grained Size Control for Compressed Large Language Models in Variable Memory Environments
Paper and Code
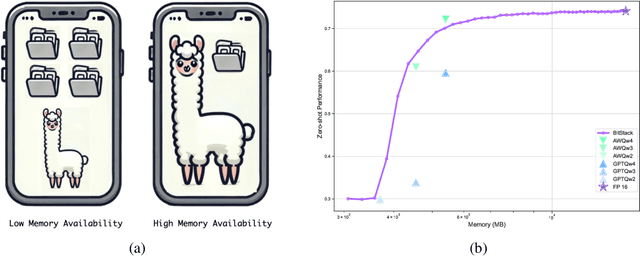
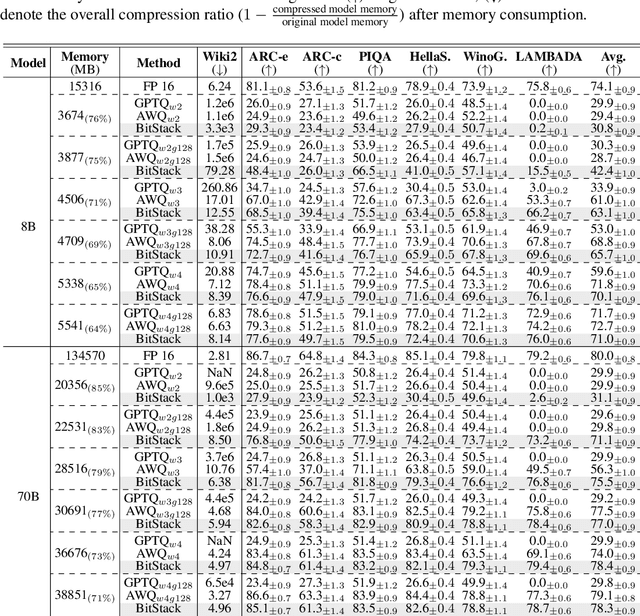
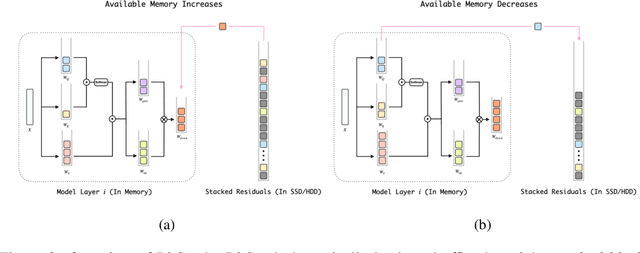
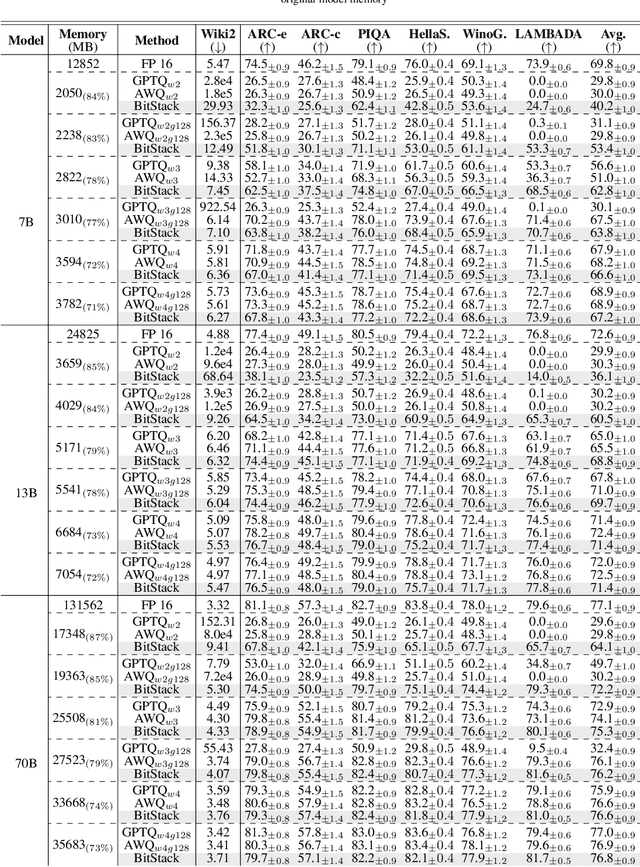
Large language models (LLMs) have revolutionized numerous applications, yet their deployment remains challenged by memory constraints on local devices. While scaling laws have enhanced LLM capabilities, the primary bottleneck has shifted from \textit{capability} to \textit{availability}, emphasizing the need for efficient memory management. Traditional compression methods, such as quantization, often require predefined compression ratios and separate compression processes for each setting, complicating deployment in variable memory environments. In this paper, we introduce \textbf{BitStack}, a novel, training-free weight compression approach that enables megabyte-level trade-offs between memory usage and model performance. By leveraging weight decomposition, BitStack can dynamically adjust the model size with minimal transmission between running memory and storage devices. Our approach iteratively decomposes weight matrices while considering the significance of each parameter, resulting in an approximately 1-bit per parameter residual block in each decomposition iteration. These blocks are sorted and stacked in storage as basic transmission units, with different quantities loaded based on current memory availability. Extensive experiments across a wide range of tasks demonstrate that, despite offering fine-grained size control, BitStack consistently matches or surpasses strong quantization baselines, particularly at extreme compression ratios. To the best of our knowledge, this is the first decomposition-based method that effectively bridges the gap to practical compression techniques like quantization. Code is available at https://github.com/xinghaow99/BitStack.