 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeoSeg: Training-Free Reasoning-Driven Segmentation in Remote Sensing Imagery
Mar 04, 2026Recent advances in MLLMs are reframing segmentation from fixed-category prediction to instruction-grounded localization. While reasoning based segmentation has progressed rapidly in natural scenes, remote sensing lacks a generalizable solution due to the prohibitive cost of reasoning-oriented data and domain-specific challenges like overhead viewpoints. We present GeoSeg, a zero-shot, training-free framework that bypasses the supervision bottleneck for reasoning-driven remote sensing segmentation. GeoSeg couples MLLM reasoning with precise localization via: (i) bias-aware coordinate refinement to correct systematic grounding shifts and (ii) a dual-route prompting mechanism to fuse semantic intent with fine-grained spatial cues. We also introduce GeoSeg-Bench, a diagnostic benchmark of 810 image--query pairs with hierarchical difficulty levels. Experiments show that GeoSeg consistently outperforms all baselines, with extensive ablations confirming the effectiveness and necessity of each component.
SNR-Edit: Structure-Aware Noise Rectification for Inversion-Free Flow-Based Editing
Jan 27, 2026Inversion-free image editing using flow-based generative models challenges the prevailing inversion-based pipelines. However, existing approaches rely on fixed Gaussian noise to construct the source trajectory, leading to biased trajectory dynamics and causing structural degradation or quality loss. To address this, we introduce SNR-Edit, a training-free framework achieving faithful Latent Trajectory Correction via adaptive noise control. Mechanistically, SNR-Edit uses structure-aware noise rectification to inject segmentation constraints into the initial noise, anchoring the stochastic component of the source trajectory to the real image's implicit inversion position and reducing trajectory drift during source--target transport. This lightweight modification yields smoother latent trajectories and ensures high-fidelity structural preservation without requiring model tuning or inversion. Across SD3 and FLUX, evaluations on PIE-Bench and SNR-Bench show that SNR-Edit delivers performance on pixel-level metrics and VLM-based scoring, while adding only about 1s overhead per image.
MagicID: Hybrid Preference Optimization for ID-Consistent and Dynamic-Preserved Video Customization
Mar 16, 2025
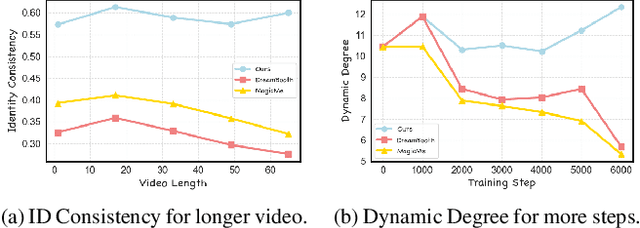

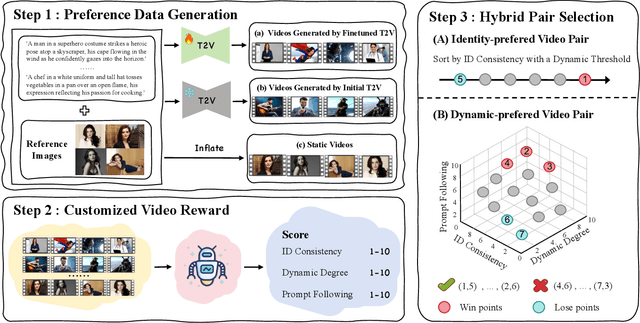
Video identity customization seeks to produce high-fidelity videos that maintain consistent identity and exhibit significant dynamics based on users' reference images. However, existing approaches face two key challenges: identity degradation over extended video length and reduced dynamics during training, primarily due to their reliance on traditional self-reconstruction training with static images. To address these issues, we introduce $\textbf{MagicID}$, a novel framework designed to directly promote the generation of identity-consistent and dynamically rich videos tailored to user preferences. Specifically, we propose constructing pairwise preference video data with explicit identity and dynamic rewards for preference learning, instead of sticking to the traditional self-reconstruction. To address the constraints of customized preference data, we introduce a hybrid sampling strategy. This approach first prioritizes identity preservation by leveraging static videos derived from reference images, then enhances dynamic motion quality in the generated videos using a Frontier-based sampling method. By utilizing these hybrid preference pairs, we optimize the model to align with the reward differences between pairs of customized preferences. Extensive experiments show that MagicID successfully achieves consistent identity and natural dynamics, surpassing existing methods across various metrics.
VidSketch: Hand-drawn Sketch-Driven Video Generation with Diffusion Control
Feb 03, 2025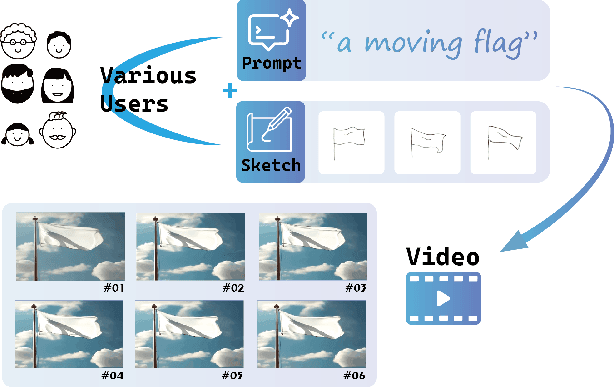



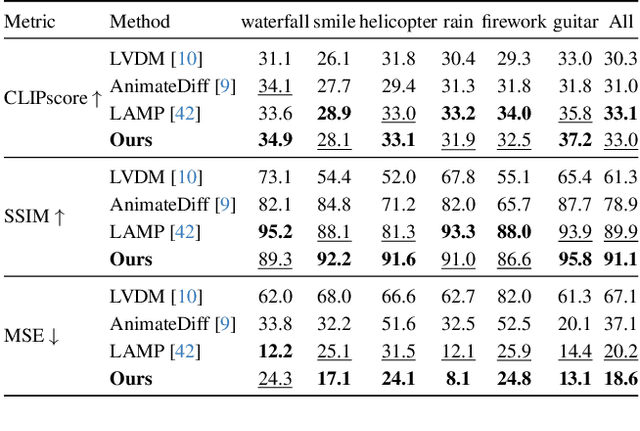
With the advancement of generative artificial intelligence, previous studies have achieved the task of generating aesthetic images from hand-drawn sketches, fulfilling the public's needs for drawing. However, these methods are limited to static images and lack the ability to control video animation generation using hand-drawn sketches. To address this gap, we propose VidSketch, the first method capable of generating high-quality video animations directly from any number of hand-drawn sketches and simple text prompts, bridging the divide between ordinary users and professional artists. Specifically, our method introduces a Level-Based Sketch Control Strategy to automatically adjust the guidance strength of sketches during the generation process, accommodating users with varying drawing skills. Furthermore, a TempSpatial Attention mechanism is designed to enhance the spatiotemporal consistency of generated video animations, significantly improving the coherence across frames. You can find more detailed cases on our official website.
HuViDPO:Enhancing Video Generation through Direct Preference Optimization for Human-Centric Alignment
Feb 02, 2025
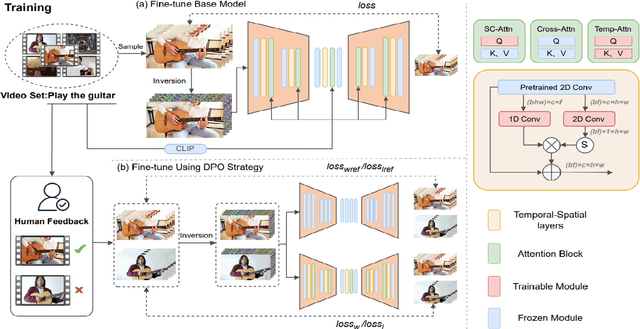
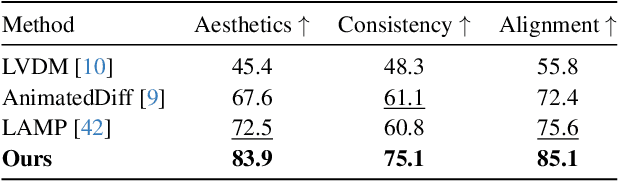
With the rapid development of AIGC technology, significant progress has been made in diffusion model-based technologies for text-to-image (T2I) and text-to-video (T2V). In recent years, a few studies have introduced the strategy of Direct Preference Optimization (DPO) into T2I tasks, significantly enhancing human preferences in generated images. However, existing T2V generation methods lack a well-formed pipeline with exact loss function to guide the alignment of generated videos with human preferences using DPO strategies. Additionally, challenges such as the scarcity of paired video preference data hinder effective model training. At the same time, the lack of training datasets poses a risk of insufficient flexibility and poor video generation quality in the generated videos. Based on those problems, our work proposes three targeted solutions in sequence. 1) Our work is the first to introduce the DPO strategy into the T2V tasks. By deriving a carefully structured loss function, we utilize human feedback to align video generation with human preferences. We refer to this new method as HuViDPO. 2) Our work constructs small-scale human preference datasets for each action category and fine-tune this model, improving the aesthetic quality of the generated videos while reducing training costs. 3) We adopt a First-Frame-Conditioned strategy, leveraging the rich in formation from the first frame to guide the generation of subsequent frames, enhancing flexibility in video generation. At the same time, we employ a SparseCausal Attention mechanism to enhance the quality of the generated videos.More details and examples can be accessed on our website: https://tankowa.github.io/HuViDPO. github.io/.
ConsistencyTrack: A Robust Multi-Object Tracker with a Generation Strategy of Consistency Model
Aug 28, 2024



Multi-object tracking (MOT) is a critical technology in computer vision, designed to detect multiple targets in video sequences and assign each target a unique ID per frame. Existed MOT methods excel at accurately tracking multiple objects in real-time across various scenarios. However, these methods still face challenges such as poor noise resistance and frequent ID switches. In this research, we propose a novel ConsistencyTrack, joint detection and tracking(JDT) framework that formulates detection and association as a denoising diffusion process on perturbed bounding boxes. This progressive denoising strategy significantly improves the model's noise resistance. During the training phase, paired object boxes within two adjacent frames are diffused from ground-truth boxes to a random distribution, and then the model learns to detect and track by reversing this process. In inference, the model refines randomly generated boxes into detection and tracking results through minimal denoising steps. ConsistencyTrack also introduces an innovative target association strategy to address target occlusion. Experiments on the MOT17 and DanceTrack datasets demonstrate that ConsistencyTrack outperforms other compared methods, especially better than DiffusionTrack in inference speed and other performance metrics. Our code is available at https://github.com/Tankowa/ConsistencyTrack.
Multi-method Integration with Confidence-based Weighting for Zero-shot Image Classification
May 03, 2024This paper introduces a novel framework for zero-shot learning (ZSL), i.e., to recognize new categories that are unseen during training, by using a multi-model and multi-alignment integration method. Specifically, we propose three strategies to enhance the model's performance to handle ZSL: 1) Utilizing the extensive knowledge of ChatGPT and the powerful image generation capabilities of DALL-E to create reference images that can precisely describe unseen categories and classification boundaries, thereby alleviating the information bottleneck issue; 2) Integrating the results of text-image alignment and image-image alignment from CLIP, along with the image-image alignment results from DINO, to achieve more accurate predictions; 3) Introducing an adaptive weighting mechanism based on confidence levels to aggregate the outcomes from different prediction methods. Experimental results on multiple datasets, including CIFAR-10, CIFAR-100, and TinyImageNet, demonstrate that our model can significantly improve classification accuracy compared to single-model approaches, achieving AUROC scores above 96% across all test datasets, and notably surpassing 99% on the CIFAR-10 dataset.
ConsistencyDet: A Robust Object Detector with a Denoising Paradigm of Consistency Model
Apr 17, 2024



Object detection, a quintessential task in the realm of perceptual computing, can be tackled using a generative methodology. In the present study, we introduce a novel framework designed to articulate object detection as a denoising diffusion process, which operates on the perturbed bounding boxes of annotated entities. This framework, termed ConsistencyDet, leverages an innovative denoising concept known as the Consistency Model. The hallmark of this model is its self-consistency feature, which empowers the model to map distorted information from any temporal stage back to its pristine state, thereby realizing a "one-step denoising" mechanism. Such an attribute markedly elevates the operational efficiency of the model, setting it apart from the conventional Diffusion Model. Throughout the training phase, ConsistencyDet initiates the diffusion sequence with noise-infused boxes derived from the ground-truth annotations and conditions the model to perform the denoising task. Subsequently, in the inference stage, the model employs a denoising sampling strategy that commences with bounding boxes randomly sampled from a normal distribution. Through iterative refinement, the model transforms an assortment of arbitrarily generated boxes into definitive detections. Comprehensive evaluations employing standard benchmarks, such as MS-COCO and LVIS, corroborate that ConsistencyDet surpasses other leading-edge detectors in performance metrics. Our code is available at https://github.com/Tankowa/ConsistencyDet.
ConsistencyDet: Robust Object Detector with Denoising Paradigm of Consistency Model
Apr 11, 2024Object detection, a quintessential task in the realm of perceptual computing, can be tackled using a generative methodology. In the present study, we introduce a novel framework designed to articulate object detection as a denoising diffusion process, which operates on perturbed bounding boxes of annotated entities. This framework, termed ConsistencyDet, leverages an innovative denoising concept known as the Consistency Model. The hallmark of this model is its self-consistency feature, which empowers the model to map distorted information from any temporal stage back to its pristine state, thereby realizing a ``one-step denoising'' mechanism. Such an attribute markedly elevates the operational efficiency of the model, setting it apart from the conventional Diffusion Model. Throughout the training phase, ConsistencyDet initiates the diffusion sequence with noise-infused boxes derived from the ground-truth annotations and conditions the model to perform the denoising task. Subsequently, in the inference stage, the model employs a denoising sampling strategy that commences with bounding boxes randomly sampled from a normal distribution. Through iterative refinement, the model transforms an assortment of arbitrarily generated boxes into the definitive detections. Comprehensive evaluations employing standard benchmarks, such as MS-COCO and LVIS, corroborate that ConsistencyDet surpasses other leading-edge detectors in performance metrics.