 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVidSketch: Hand-drawn Sketch-Driven Video Generation with Diffusion Control
Feb 03, 2025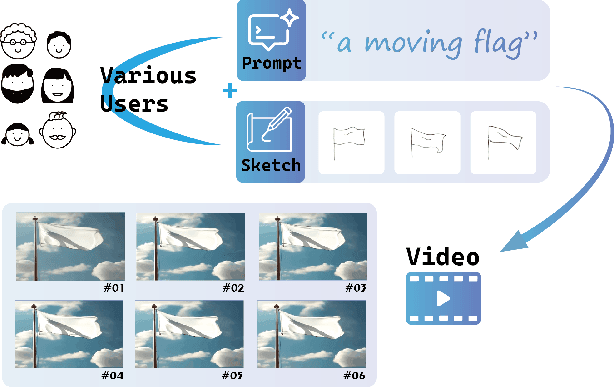



With the advancement of generative artificial intelligence, previous studies have achieved the task of generating aesthetic images from hand-drawn sketches, fulfilling the public's needs for drawing. However, these methods are limited to static images and lack the ability to control video animation generation using hand-drawn sketches. To address this gap, we propose VidSketch, the first method capable of generating high-quality video animations directly from any number of hand-drawn sketches and simple text prompts, bridging the divide between ordinary users and professional artists. Specifically, our method introduces a Level-Based Sketch Control Strategy to automatically adjust the guidance strength of sketches during the generation process, accommodating users with varying drawing skills. Furthermore, a TempSpatial Attention mechanism is designed to enhance the spatiotemporal consistency of generated video animations, significantly improving the coherence across frames. You can find more detailed cases on our official website.
HuViDPO:Enhancing Video Generation through Direct Preference Optimization for Human-Centric Alignment
Feb 02, 2025
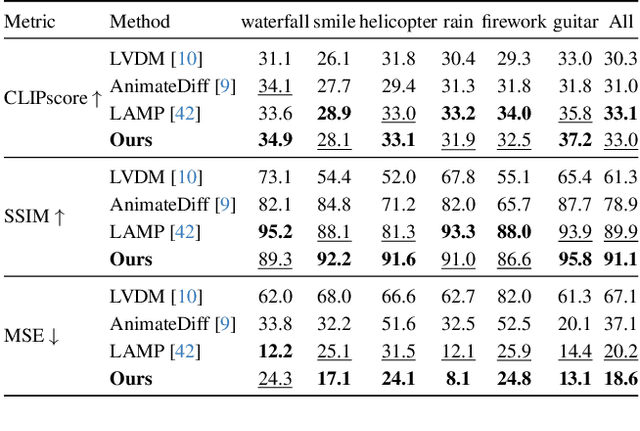
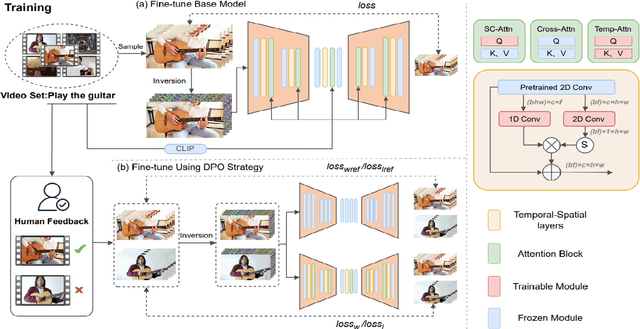
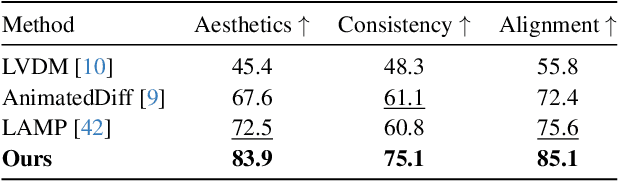
With the rapid development of AIGC technology, significant progress has been made in diffusion model-based technologies for text-to-image (T2I) and text-to-video (T2V). In recent years, a few studies have introduced the strategy of Direct Preference Optimization (DPO) into T2I tasks, significantly enhancing human preferences in generated images. However, existing T2V generation methods lack a well-formed pipeline with exact loss function to guide the alignment of generated videos with human preferences using DPO strategies. Additionally, challenges such as the scarcity of paired video preference data hinder effective model training. At the same time, the lack of training datasets poses a risk of insufficient flexibility and poor video generation quality in the generated videos. Based on those problems, our work proposes three targeted solutions in sequence. 1) Our work is the first to introduce the DPO strategy into the T2V tasks. By deriving a carefully structured loss function, we utilize human feedback to align video generation with human preferences. We refer to this new method as HuViDPO. 2) Our work constructs small-scale human preference datasets for each action category and fine-tune this model, improving the aesthetic quality of the generated videos while reducing training costs. 3) We adopt a First-Frame-Conditioned strategy, leveraging the rich in formation from the first frame to guide the generation of subsequent frames, enhancing flexibility in video generation. At the same time, we employ a SparseCausal Attention mechanism to enhance the quality of the generated videos.More details and examples can be accessed on our website: https://tankowa.github.io/HuViDPO. github.io/.