 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClustering Propagation for Universal Medical Image Segmentation
Mar 25, 2024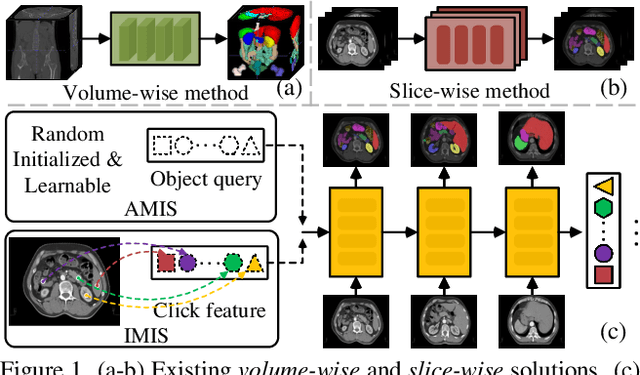
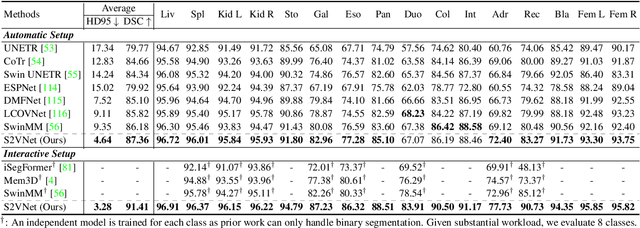
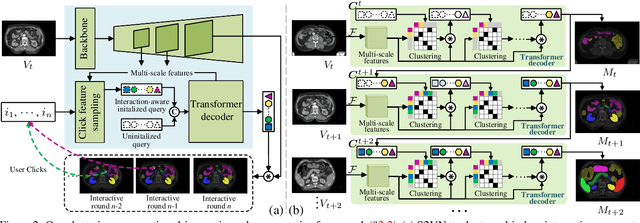
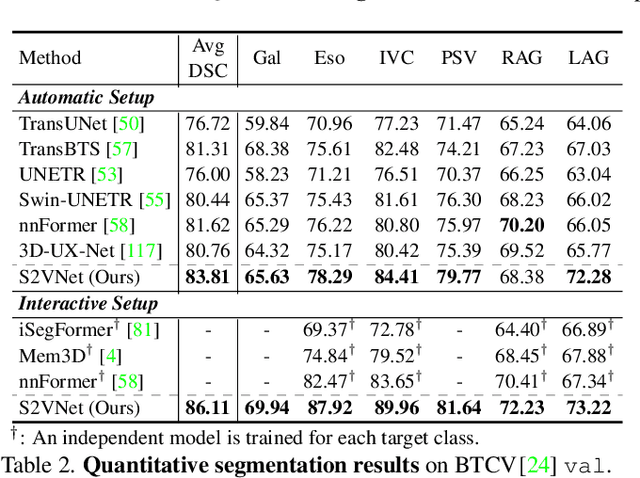
Prominent solutions for medical image segmentation are typically tailored for automatic or interactive setups, posing challenges in facilitating progress achieved in one task to another.$_{\!}$ This$_{\!}$ also$_{\!}$ necessitates$_{\!}$ separate$_{\!}$ models for each task, duplicating both training time and parameters.$_{\!}$ To$_{\!}$ address$_{\!}$ above$_{\!}$ issues,$_{\!}$ we$_{\!}$ introduce$_{\!}$ S2VNet,$_{\!}$ a$_{\!}$ universal$_{\!}$ framework$_{\!}$ that$_{\!}$ leverages$_{\!}$ Slice-to-Volume$_{\!}$ propagation$_{\!}$ to$_{\!}$ unify automatic/interactive segmentation within a single model and one training session. Inspired by clustering-based segmentation techniques, S2VNet makes full use of the slice-wise structure of volumetric data by initializing cluster centers from the cluster$_{\!}$ results$_{\!}$ of$_{\!}$ previous$_{\!}$ slice.$_{\!}$ This enables knowledge acquired from prior slices to assist in the segmentation of the current slice, further efficiently bridging the communication between remote slices using mere 2D networks. Moreover, such a framework readily accommodates interactive segmentation with no architectural change, simply by initializing centroids from user inputs. S2VNet distinguishes itself by swift inference speeds and reduced memory consumption compared to prevailing 3D solutions. It can also handle multi-class interactions with each of them serving to initialize different centroids. Experiments on three benchmarks demonstrate S2VNet surpasses task-specified solutions on both automatic/interactive setups.
PSTNet: Point Spatio-Temporal Convolution on Point Cloud Sequences
May 27, 2022

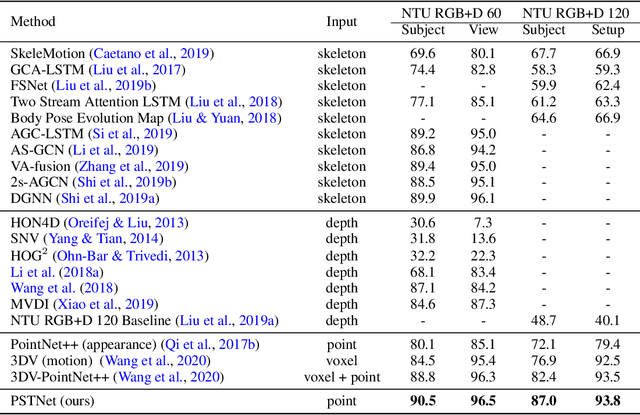

Point cloud sequences are irregular and unordered in the spatial dimension while exhibiting regularities and order in the temporal dimension. Therefore, existing grid based convolutions for conventional video processing cannot be directly applied to spatio-temporal modeling of raw point cloud sequences. In this paper, we propose a point spatio-temporal (PST) convolution to achieve informative representations of point cloud sequences. The proposed PST convolution first disentangles space and time in point cloud sequences. Then, a spatial convolution is employed to capture the local structure of points in the 3D space, and a temporal convolution is used to model the dynamics of the spatial regions along the time dimension. Furthermore, we incorporate the proposed PST convolution into a deep network, namely PSTNet, to extract features of point cloud sequences in a hierarchical manner. Extensive experiments on widely-used 3D action recognition and 4D semantic segmentation datasets demonstrate the effectiveness of PSTNet to model point cloud sequences.
Modeling the Probabilistic Distribution of Unlabeled Data forOne-shot Medical Image Segmentation
Feb 03, 2021

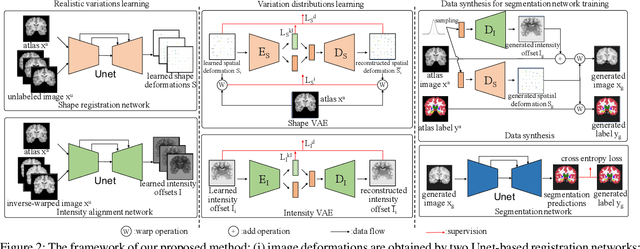

Existing image segmentation networks mainly leverage large-scale labeled datasets to attain high accuracy. However, labeling medical images is very expensive since it requires sophisticated expert knowledge. Thus, it is more desirable to employ only a few labeled data in pursuing high segmentation performance. In this paper, we develop a data augmentation method for one-shot brain magnetic resonance imaging (MRI) image segmentation which exploits only one labeled MRI image (named atlas) and a few unlabeled images. In particular, we propose to learn the probability distributions of deformations (including shapes and intensities) of different unlabeled MRI images with respect to the atlas via 3D variational autoencoders (VAEs). In this manner, our method is able to exploit the learned distributions of image deformations to generate new authentic brain MRI images, and the number of generated samples will be sufficient to train a deep segmentation network. Furthermore, we introduce a new standard segmentation benchmark to evaluate the generalization performance of a segmentation network through a cross-dataset setting (collected from different sources). Extensive experiments demonstrate that our method outperforms the state-of-the-art one-shot medical segmentation methods. Our code has been released at https://github.com/dyh127/Modeling-the-Probabilistic-Distribution-of-Unlabeled-Data.
Adaptive Exploration for Unsupervised Person Re-Identification
Jul 09, 2019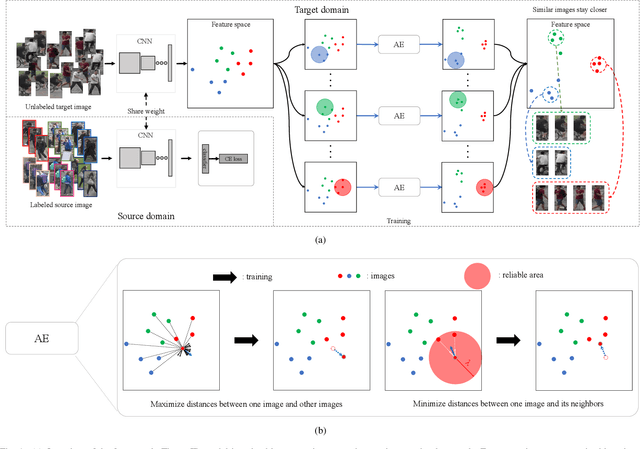

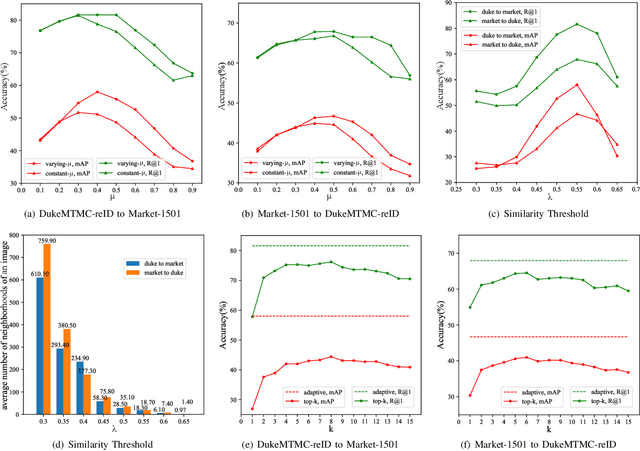

Due to domain bias, directly deploying a deep person re-identification (re-ID) model trained on one dataset often achieves considerably poor accuracy on another dataset. In this paper, we propose an Adaptive Exploration (AE) method to address the domain-shift problem for re-ID in an unsupervised manner. Specifically, with supervised training on the source dataset, in the target domain, the re-ID model is inducted to 1) maximize distances between all person images and 2) minimize distances between similar person images. In the first case, by treating each person image as an individual class, a non-parametric classifier with a feature memory is exploited to encourage person images to move away from each other. In the second case, according to a similarity threshold, our method adaptively selects neighborhoods in the feature space for each person image. By treating these similar person images as the same class, the non-parametric classifier forces them to stay closer. However, a problem of adaptive selection is that, when an image has too many neighborhoods, it is more likely to attract other images as its neighborhoods. As a result, a minority of images may select a large number of neighborhoods while a majority of images has only a few neighborhoods. To address this issue, we additionally integrate a balance strategy into the adaptive selection. Extensive experiments on large-scale re-ID datasets demonstrate the effectiveness of our method. Our code has been released at https://github.com/dyh127/Adaptive-Exploration-for-Unsupervised-Person-Re-Identification.